k均值聚类 K-Means
非常大的 n_samples, 中等的 n_clusters,将样本分成 n 组等方差的样本来聚类数据
metric:点之间的距离

步骤:
随机选K个聚集点
每个数据被赋值最近聚集点类别
使用每个聚集中心点更新
重复直到聚点移动小于阈值
返回K个中心点坐标
优点:简单,对于规则性图形聚类很好,收敛性号 O(t k n)
缺点:
- 定K值
- 可能收敛到局部最优
- 假设集群是凸的和各向同性的,但情况并非总是如此。对细长的簇或形状不规则的流形反应不佳
- 在非常高维的空间中,欧几里得距离往往会膨胀(在 k 均值聚类之前运行诸如主成分分析 (PCA) 之类的降维算法可以缓解此问题并加快计算速度)
sklearn优化
-
使用init='k-means++'参数。将质心初始化为(通常)彼此远离,可能比随机初始化更好的结果
-
支持样本权重,可以由参数 给出 sample_weight。这允许在计算集群中心和惯性值时为某些样本分配更多权重。
-
MiniBatchKMeans, 使用小批量来减少计算时间,MiniBatchKMeans收敛速度比 快KMeans,但结果的质量降低。在实践中,这种质量差异可能非常小
import os
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import neighbors
import matplotlib.pyplot as plt
data_path = ['../tf_demo/data']
filepath = os.sep.join(data_path + ['Iris_Data.csv'])
data = pd.read_csv(filepath)
train_x =data.iloc[0:120,0:4]
train_y =data.iloc[0:120,4]
test_x =data.iloc[120:150,0:4]
test_y =data.iloc[120:150,4].values
model=KMeans(n_clusters=3)
model=model.fit(train_x)
clusterResult = pd.DataFrame(model2.labels_,index=train_x.index,columns=['species'])
密度聚类 DBSCAN
非常大的 n_samples, 中等的 n_clusters
metric:
该DBSCAN算法将集群视为由低密度区域分隔的高密度区域。由于这种相当通用的观点,DBSCAN 发现的簇可以是任何形状,而 k-means 假设簇是凸形的。DBSCAN 的核心组成部分是核心样本的概念,即位于高密度区域的样本。因此,集群是一组核心样本,每个核心样本彼此靠近(通过某种距离度量测量)和一组靠近核心样本的非核心样本(但本身不是核心样本)。该算法有两个参数 min_samples和eps,它们正式定义了我们所说的密集 的含义。更高min_samples或更低eps 表示形成集群所需的更高密度。
优点:
- 原始数据分布规律没有明显要求,能适应任意数据集分布形状的空间聚类,因此数据集适用性更广,- - 尤其是对非凸装、圆环形等异性簇分布的识别较好。
- 无需指定聚类数量,对结果的先验要求不高
- 由于DBSCAN可区分核心对象、边界点和噪点,因此对噪声的过滤效果好,能有效应对数据噪点。
由于他对整个数据集进行操作且聚类时使用了一个全局性的表征密度的参数,因此也存在比较明显的弱点:
- 对于高纬度问题,基于半径和密度的定义成问题。
- 当簇的密度变化太大时,聚类结果较差。
- 当数据量增大时,要求较大的内存支持,I/O消耗也很大。
print(__doc__)
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import c
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# #############################################################################
# Compute DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
OPTICS
可以认为是 DBSCAN 的泛化,将eps要求从单个值放宽 到值范围。DBSCAN 和 OPTICS 之间的主要区别在于 OPTICS 算法构建了一个可达性 图,它为每个样本分配了一个reachability_距离和一个集群ordering_属性内的点;如果OPTICS与默认值运行INF为组max_eps,然后DBSCAN风格簇萃取可以重复在线性时间对于任何给定执行eps使用值cluster_optics_dbscan的方法。环境 max_eps较低的值将导致较短的运行时间,并且可以认为是从每个点开始寻找其他潜在可达点的最大邻域半径。
# Authors: Shane Grigsby <refuge@rocktalus.com>
# Adrin Jalali <adrin.jalali@gmail.com>
# License: BSD 3 clause
from sklearn.cluster import OPTICS, cluster_optics_dbscan
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
import numpy as np
# Generate sample data
np.random.seed(0)
n_points_per_cluster = 250
C1 = [-5, -2] + .8 * np.random.randn(n_points_per_cluster, 2)
C2 = [4, -1] + .1 * np.random.randn(n_points_per_cluster, 2)
C3 = [1, -2] + .2 * np.random.randn(n_points_per_cluster, 2)
C4 = [-2, 3] + .3 * np.random.randn(n_points_per_cluster, 2)
C5 = [3, -2] + 1.6 * np.random.randn(n_points_per_cluster, 2)
C6 = [5, 6] + 2 * np.random.randn(n_points_per_cluster, 2)
X = np.vstack((C1, C2, C3, C4, C5, C6))
clust = OPTICS(min_samples=50, xi=.05, min_cluster_size=.05)
# Run the fit
clust.fit(X)
labels_050 = cluster_optics_dbscan(reachability=clust.reachability_,
core_distances=clust.core_distances_,
ordering=clust.ordering_, eps=0.5)
labels_200 = cluster_optics_dbscan(reachability=clust.reachability_,
core_distances=clust.core_distances_,
ordering=clust.ordering_, eps=2)
space = np.arange(len(X))
reachability = clust.reachability_[clust.ordering_]
labels = clust.labels_[clust.ordering_]
plt.figure(figsize=(10, 7))
G = gridspec.GridSpec(2, 3)
ax1 = plt.subplot(G[0, :])
ax2 = plt.subplot(G[1, 0])
ax3 = plt.subplot(G[1, 1])
ax4 = plt.subplot(G[1, 2])
# Reachability plot
colors = ['g.', 'r.', 'b.', 'y.', 'c.']
for klass, color in zip(range(0, 5), colors):
Xk = space[labels == klass]
Rk = reachability[labels == klass]
ax1.plot(Xk, Rk, color, alpha=0.3)
ax1.plot(space[labels == -1], reachability[labels == -1], 'k.', alpha=0.3)
ax1.plot(space, np.full_like(space, 2., dtype=float), 'k-', alpha=0.5)
ax1.plot(space, np.full_like(space, 0.5, dtype=float), 'k-.', alpha=0.5)
ax1.set_ylabel('Reachability (epsilon distance)')
ax1.set_title('Reachability Plot')
# OPTICS
colors = ['g.', 'r.', 'b.', 'y.', 'c.']
for klass, color in zip(range(0, 5), colors):
Xk = X[clust.labels_ == klass]
ax2.plot(Xk[:, 0], Xk[:, 1], color, alpha=0.3)
ax2.plot(X[clust.labels_ == -1, 0], X[clust.labels_ == -1, 1], 'k+', alpha=0.1)
ax2.set_title('Automatic Clustering\nOPTICS')
# DBSCAN at 0.5
colors = ['g', 'greenyellow', 'olive', 'r', 'b', 'c']
for klass, color in zip(range(0, 6), colors):
Xk = X[labels_050 == klass]
ax3.plot(Xk[:, 0], Xk[:, 1], color, alpha=0.3, marker='.')
ax3.plot(X[labels_050 == -1, 0], X[labels_050 == -1, 1], 'k+', alpha=0.1)
ax3.set_title('Clustering at 0.5 epsilon cut\nDBSCAN')
# DBSCAN at 2.
colors = ['g.', 'm.', 'y.', 'c.']
for klass, color in zip(range(0, 4), colors):
Xk = X[labels_200 == klass]
ax4.plot(Xk[:, 0], Xk[:, 1], color, alpha=0.3)
ax4.plot(X[labels_200 == -1, 0], X[labels_200 == -1, 1], 'k+', alpha=0.1)
ax4.set_title('Clustering at 2.0 epsilon cut\nDBSCAN')
plt.tight_layout()
plt.show()
层次聚类
Agglomerative clustering
自底而上的层次聚类方法,每一个对象最开始都是一个cluster,每次按一定的准则将最相近的两个cluster合并生成一个新的cluster,如此往复,直至最终所有的对象都属于一个cluster。
链接标准决定了用于合并策略的度量:
-
Ward最小化所有集群内的平方差的总和。它是一种方差最小化方法,在这个意义上类似于 k-means 目标函数,但使用凝聚分层方法进行处理。
-
最大或完全链接最小化成对集群的观察之间的最大距离。
-
平均链接最小化成对聚类的所有观察值之间的平均距离。
-
单链接最小化成对簇的最近观测值之间的距离。
metric:任意成对距离
AgglomerativeClustering 支持Ward、single、average、complete联动策略。
比较:
对于非欧几里德度量,平均链接是一个很好的选择。
单一链接虽然对噪声数据不稳健,但可以非常有效地计算,因此可用于提供较大数据集的层次聚类。单链接也可以在非全局数据上表现良好。
Ward hierarchical clustering
不直接测量距离,而是分析聚类的方差。Ward 的方法说两个簇 A 和 B 之间的距离是当我们合并它们时平方和会增加多少
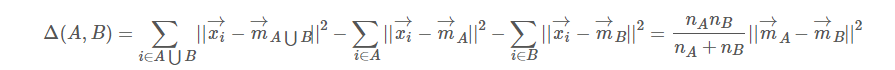
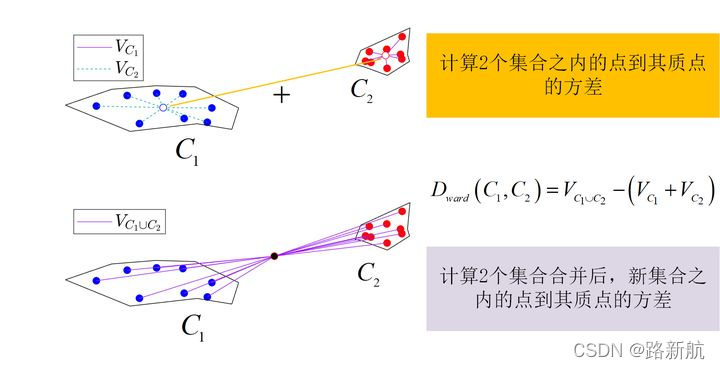
metric:点之间的距离
# Authors: Gael Varoquaux, Nelle Varoquaux
# License: BSD 3 clause
import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import kneighbors_graph
# Generate sample data
n_samples = 1500
np.random.seed(0)
t = 1.5 * np.pi * (1 + 3 * np.random.rand(1, n_samples))
x = t * np.cos(t)
y = t * np.sin(t)
X = np.concatenate((x, y))
X += .7 * np.random.randn(2, n_samples)
X = X.T
# Create a graph capturing local connectivity. Larger number of neighbors
# will give more homogeneous clusters to the cost of computation
# time. A very large number of neighbors gives more evenly distributed
# cluster sizes, but may not impose the local manifold structure of
# the data
knn_graph = kneighbors_graph(X, 30, include_self=False)
for connectivity in (None, knn_graph):
for n_clusters in (30, 3):
plt.figure(figsize=(10, 4))
for index, linkage in enumerate(('average',
'complete',
'ward',
'single')):
plt.subplot(1, 4, index + 1)
model = AgglomerativeClustering(linkage=linkage,
connectivity=connectivity,
n_clusters=n_clusters)
t0 = time.time()
model.fit(X)
elapsed_time = time.time() - t0
plt.scatter(X[:, 0], X[:, 1], c=model.labels_,
cmap=plt.cm.nipy_spectral)
plt.title('linkage=%s\n(time %.2fs)' % (linkage, elapsed_time),
fontdict=dict(verticalalignment='top'))
plt.axis('equal')
plt.axis('off')
plt.subplots_adjust(bottom=0, top=.83, wspace=0,
left=0, right=1)
plt.suptitle('n_cluster=%i, connectivity=%r' %
(n_clusters, connectivity is not None), size=17)
plt.show()
评估指标
评估指标解析:
- inertias:inertias是K均值模型对象的属性,表示样本距离最近的聚类中心的总和,它是作为在没有真实分类结果标签下的非监督式评估指标。该值越小越好,值越小证明样本在类间的分布越集中,即类内的距离越小。
- adjusted_mutual_info_s:调整后的互信息(Adjusted Mutual Information, AMI),调整后的互信息是对互信息评分的调整得分。它考虑到对于具有更大数量的聚类群,通常MI较高,而不管实际上是否有更多的信息共享,它通过调整聚类群的概率来纠正这种影响。当两个聚类集相同(即完全匹配)时,AMI返回值为1;随机分区(独立标签)平均预期AMI约为0,也可能为负数。
- homogeneity_s:同质化得分(Homogeneity),如果所有的聚类都只包含属于单个类的成员的数据点,则聚类结果将满足同质性。其取值范围[0,1]值越大意味着聚类结果与真实情况越吻合。
- completeness_s:完整性得分(Completeness),如果作为给定类的成员的所有数据点是相同集群的元素,则聚类结果满足完整性。其取值范围[0,1],值越大意味着聚类结果与真实情况越吻合。
- v_measure_s:它是同质化和完整性之间的谐波平均值,v = 2 (均匀性 完整性)/(均匀性+完整性)。其取值范围[0,1],值越大意味着聚类结果与真实情况越吻合。
- silhouette_s:轮廓系数(Silhouette),它用来计算所有样本的平均轮廓系数,使用平均群内距离和每个样本的平均最近簇距离来计算,它是一种非监督式评估指标。其最高值为1,最差值为-1,0附近的值表示重叠的聚类,负值通常表示样本已被分配到错误的集群。
- adjusted_rand_s:调整后的兰德指数(Adjusted Rand Index),兰德指数通过考虑在预测和真实聚类中在相同或不同聚类中分配的所有样本对和计数对来计算两个聚类之间的相似性度量。调整后的兰德指数通过对兰德指数的调整得到独立于样本量和类别的接近于0的值,其取值范围为[-1, 1],负数代表结果不好,越接近于1越好意味着聚类结果与真实情况越吻合。
- mutual_info_s:互信息(Mutual Information, MI),互信息是一个随机变量中包含的关于另一个随机变量的信息量,在这里指的是相同数据的两个标签之间的相似度的量度,结果是非负值。
- calinski_harabaz_s:该分数定义为群内离散与簇间离散的比值,它是一种非监督式评估指标。




