参考:李航 机器学习
聚类任务
聚类原则:
聚类过程:
聚类将样本D划分为K个不相交的簇
应用场景:
聚类可以寻找数据内在的分布结构,也可以作为分类等任务前置任务。
如:

性能度量
性能度量有两类:
- 将聚类结果与某个"参考模型" (reference model) 进行比较,称为"外部指标" (external index);
- 直接考察聚类结果而不利用任何参考模型,称为"内部指标" (internal index).
距离计算
距离度量需要满足:非负性,同一性,对称性,直传性。
常见度量公式"闵可夫斯基距离"
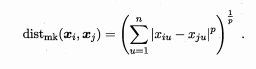

这种度量方式针对有序属性。
无序属性使用VDM(Value Difference Metric)

原型聚类
原型聚类亦称"基于原型的聚类" (prototype~ based clustering)) 此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用.通常情形下,算法先对原型进行初始化,然后对原型进行迭代更新求解.
k均值算法
参考:K-means聚类算法中的K如何确定?
loss函数:平方误差
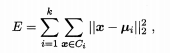
E值越小则簇内样本相似度越高.
k均值算法采用了贪心策略,通过迭代优化来近似求解式。
算法过程:

例子:



学习向量化
learning vector quantization,简称LVQ,也是试图找到一组原型向量来刻画聚类结构, 但与一般聚类算法不同的是, LVQ 假设数据样本带有类别标记,学习过程利用样本的这些监督信息辅助聚类
算法过程:

即如何更新原型向量:

分.对任意样本x,它将被划入与其距离最近的原型向量所代表的簇中
例子:


高斯混合聚类
与K均值、 LVQ 用原型向量来刻画聚类结构不同,高斯混合(Mixture-oιGaussian) 聚类采用概率模型来表达聚类原型.


再使用先验概率和极大似然估计等求解,获取EM算法
算法过程:



例子:


密度聚类
密度聚类亦称"基于密度的聚类" (density-based clustering) ,此类算法假设聚类结构能通过样本分布的紧密程度确定.通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果.
DBSCAN




DBSCAN 算法先任选数据集中的一个核心对象为"种子" (seed), 再由此出发确定相应的聚类簇.
算法过程:
算法


例子:


层次聚类
层次聚类(h archical clust ri 试图 不同层次对数据集进行 分,从而成树 聚类结构 数据集的划 采用"自 底向上 “的聚合策略,也可采"自 顶向下” 分拆策略.
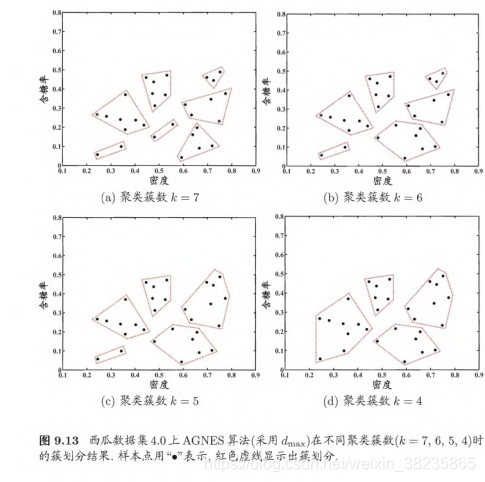
AGNES 是一种采用自底 向上聚合策略的层次 类算法.它先将数据集中每个样本看做一个初始聚类簇,然后在算法运行的每一步中找出离最近的两个聚类簇进行合并,该过程不断重复,直至达到预设的聚类簇个数.关键是如何计算聚类簇之间的距离.实际上,每个簇是一个样本集合,因此,只需
采用关于集合的某种距离即可.例如,给定聚类簇 Ci与Cj,可通过下面的式子来计算距离:
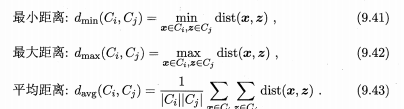
最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定而平均距离则由两个簇的所有样本共同决定.当聚类簇距离由 dmin,dmax,davg计算时 AGNES 算法被相应地称为"单链接" (single-linkage) “全链接” (complete-linkage) 或"均链接" (average-linkage) 算法.
算法过程:


例子:
以西瓜数据集 4.0 为例,令 AGNES 算法一直执行到所有样本出现在同一个簇中,即 k=1 则可得到图9.12 所示的"树状国" (dendrogram) ,其中每层链接一组聚类簇.

在树状图的特定层次上进行分割,则可得到相应的簇划分结果
聚类算法理论参考:
https://zhuanlan.zhihu.com/p/143092725
实践
目的:对商品 销售周期做聚类,做推荐组合
结论:进货周期类似的商品不合适做推荐组合
1.聚类
数据:
字段:
‘spid’:商品id
‘进货间隔天数中位数’:商品进货周期
def 进货间隔天数聚类(data):
data = data.reset_index().drop(['index'], axis=1) # 更新索引
msc = MinMaxScaler() # 缩放
le = LabelEncoder() # 编码标签
y_data = le.fit_transform(data['spid']).astype(int) # 转换标签为数值
X_data = data.drop(['spid'], axis=1) # 删除无关列 'spid','平均进货数量','进货间隔天数中位数'
X_data = pd.DataFrame(msc.fit_transform(X_data), # np.array
columns=X_data.columns)
def k_mean(X_data, y_data, K):
km = KMeans(n_clusters=K)
km = km.fit(X_data, y_data)
return km
model = k_mean(X_data, y_data, K=round(len(dict(data.value_counts()).keys()) / 2)) # K选择商品个数一半 30s
y_pred = model.predict(X_data)
y_pred_df = pd.DataFrame(list(y_pred), columns=['预测类别标号'])
data_df = pd.concat([data, y_pred_df], axis=1)
spid_groups_list = []
for k, v in dict(y_pred_df.value_counts()).items():
group_df = data_df[data_df['预测类别标号'] == k]
group_df = group_df.sort_values(by=['进货间隔天数中位数'], ascending=True)
spid_group_list = list(group_df['spid'].values)
spid_groups_list.append([spid_group_list, len(spid_group_list)])
spid_groups_list = sorted(spid_groups_list, key=lambda student: student[1], reverse=True)
save_list = [x[0] for x in spid_groups_list if x[1] >= 2] # 超过2
save_sorted_list = sorted(save_list, key=lambda i: len(i), reverse=False)
with open("聚类结果.txt", 'w', encoding='UTF-8') as fileObject:
json.dump({wldwid: save_sorted_list}, fileObject, ensure_ascii=False)
2.对聚类后的商品组合计算置信度
因为资源有限,聚类结果,一类可能包含多种样品,比如几十个样本,对于类别样本较多的类,从这几十个样本随机抽样2种,计算这两种商品的置信度
def 计算组合正确率():
with open("频繁项.txt", "r") as f: # 设置文件对象
frequent_items_json = json.load(f) # 将每一行文件加入到list中
wldwid, frequent_items_group_list = list(frequent_items_json.keys())[0], list(frequent_items_json.values())[0]
sample_group_list = []#抽样列表
for items_list in clustering_items_list:
if len(items_list) > 2:
spidA = random.sample(items_list, 1)[0] # choice 不放回采样
items_list.remove(spidA)
spidB = random.sample(items_list, 1)[0] # random.choice (items_list)#choice 不放回采样
sample_group_list.append([spidA, spidB])
data = full_data[full_data['wldwid'] == wldwid]
def 计算推荐正确率(data_items_list):
A_B_confidence_list = []
B_A_confidence_list = []
for spidA, spidB in data_items_list:
def 计算置信度(data, spidA, spidB):
sucess_num = 0
fail_num = 0
A_max_time = data[data['spid'] == spidA]['药店进货日期'].max() # spidA最后一次进货时间
A_min_time = data[data['spid'] == spidA]['药店进货日期'].min() # spidA第一次进货时间
if A_max_time == A_min_time:
return 0
current_day = A_min_time
while current_day < A_max_time:
A_djbh = data.loc[(data['药店进货日期'] == current_day) & (data['spid'] == spidA)]['djbh'].values[
0] # spidA最后一单单据编号
spidA_B = data.loc[(data['djbh'] == A_djbh) & (data['spid'] == spidB)][
'spid'].values # 购买商品A的清单是否有商品B
if len(spidA_B) > 0:
sucess_num += 1 #
else:
fail_num += 1
current_day = data[(data['药店进货日期'] > current_day) & (data['spid'] == spidA)].min()['药店进货日期']
return sucess_num / (sucess_num + fail_num)
A_B_confidence_list.append(计算置信度(data, spidA, spidB)) # 置信度
B_A_confidence_list.append(计算置信度(data, spidB, spidA)) # 置信度
print('聚类结果数据置信度大于0.8的组合占比例', (len([x for x in A_B_confidence_list if x >= 0.8]) + len(
[x for x in B_A_confidence_list if x >= 0.8])) / 2, '/', len(A_B_confidence_list))#282.5 / 539
计算推荐正确率(sample_group_list)