文章目录
- 1. K-Means原理
- 2. k-means 代码
- 3. 结果
- 3.1 关于 `matplotlib.pyplot` 中绘制点的形状和颜色
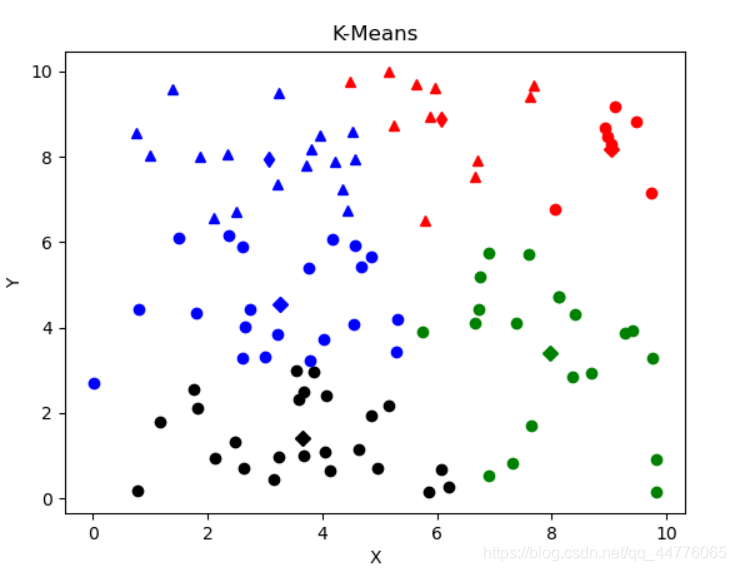
- 3.2 分类的结果
K-Means算法用来进行聚类,需要我们指定类别,即指定K的大小,通过类心不断改变,完成分类,这是无监督学习
1. K-Means原理
- 随机生成K个样本中心
- 根据样本点到随机点的距离将样本点进行归类
- 重新计算样本点的中心(中心是分类的中心)
- 重复步骤2、3, 直到样本点中心不再改变(或者迭代一定的次数)
2. k-means 代码
import numpy as np
def get_rand_data(row, column):
"""
随机产生二维数组
行的个数为 row
列的个数为 column
:param row:
:param column:
:return:
"""
# 随机产生二维数组的数据
return np.random.rand(row, column) * 10
pass
def calc_distance(vec_1, vec_2):
"""
计算两个点之间的距离,返回一个数值距离,来反映实际距离的大小
:param vec_1:
:param vec_2:
:return:
"""
return np.sum(np.power(vec_1 - vec_2, 2)) # 返回一维的数值
pass
# 随机生成中心点
def get_rand_point(data, k):
"""
由于点的个数不一致, 因此按照数据集的列生成随机点
1. 取列的个数, 对每一列生成随机点
2. 生成规则, 列的最大最小值之间的随机值 min + range * random.rand(), 对于numpy 生成矩阵
:param data:
:param k:
:return:
"""
column = np.shape(data)[1] # 取列那一行
center_point = np.mat(np.zeros((k, column))) # zeros参数是元组
# 按照列的最大最小值生成随机数
for j in range(column):
min_num = np.min(data[:, j])
range_num = (np.max(data[:, j]) - min_num)
center_point[:, j] = min_num + range_num * np.random.rand(k, 1)
return center_point
pass
def k_means(data, k, calc_dis=calc_distance, get_center=get_rand_point):
"""
k-means算法:
1. 生成中心点
2. 对每一个样本点进行处理, 找到距离其最近的中心点,保存到字典中
3. 根据中心点,重新计算中心点,再次确定样本的中心点
4. 重复2、3, 直到样本的中心点不改变
:param data: 数据集
:param k: 分类的个数
:param calc_dis: 计算距离函数
:param get_center: 获取随机的中心点
:return: 返回中心点,数据集的标记, 分类的次数
"""
# 得到行数
row = np.shape(data)[0]
# 生成保存点数据的矩阵
cluster_assment = {}
for point in list(data):
cluster_assment[tuple(point)] = [-1, np.inf]
# 得到中心点
center = get_center(data, k)
# 分类结束的标志
cluster_change = True
# 分类次数
cnt = 0
while cluster_change:
cnt += 1
cluster_change = False
# 对每一个点进行计算距离, 下标和距离保存到cluster中
for i in range(row):
min_dis, min_index = np.inf, -1
for j in range(k):
tmp_min_dis = calc_dis(data[i, :], center[j, :])
if tmp_min_dis < min_dis:
min_dis, min_index = tmp_min_dis, j
# 点的位置改变, 保存到字典中
if cluster_assment[tuple(data[i])][0] != min_index:
cluster_change = True
# 对于列表不能建立字典, 需要将列表转化为元组,能计算其hash值
cluster_assment[tuple(data[i])] = [min_index, min_dis]
# 对每一个中心点,取出取对应的样本点
for cent in range(k): # 重新计算中心点
p_list = []
for key in cluster_assment.keys():
if cluster_assment[key][0] == cent:
p_list.append(list(key))
p_list_mat = np.mat(p_list)
# 按列求均值
center[cent, :] = np.mean(p_list_mat, axis=0)
return center, cluster_assment, cnt
pass
# 绘制图像
def plot_points_2d(data, center, cluster_assment):
"""
绘制二维样本数据和中心点
1. 绘制样本点绘,指定形状和颜色
2. 绘制中心点, 指定不同的形状, 相同的颜色
:param data:
:param center:
:param cluster_assment:
:return:
"""
import matplotlib.pyplot as plt
m, n = data.shape
mark = ['or', 'ob', 'og', 'ok', '^r', '^b', '^g', '^k', '*r', '*b', '*g', '*k']
for i in range(m):
mark_index = int(cluster_assment[tuple(data[i])][0])
plt.plot(data[i, 0], data[i, 1], mark[mark_index])
mark_pattern = ['Dr', 'Db', 'Dg', 'Dk', 'dr', 'db', 'dg', 'dk', 'Xr', 'Xb', 'Xg', 'Xk']
for i in range(len(center)):
plt.plot(center[i, 0], center[i, 1], mark_pattern[i])
plt.xlabel("X")
plt.ylabel("Y")
plt.title("K-Means")
plt.show()
pass
def plot_points_3d(data, center, cluster_assment):
"""
绘制三维的中心点
1. 绘制三维的点使用 plt.axes(projection='3d')
2. 在 axes上绘制点
3.
:param data:
:param center:
:param cluster_assment:
:return:
"""
import matplotlib.pyplot as plt
axes_1 = plt.axes(projection='3d')
m, n = data.shape
mark = ['D', 'P', '^', 'h']
color = ['red', 'green', 'blue', 'black']
for i in range(m):
# 取对应中心点的下标
mark_index = int(cluster_assment[tuple(data[i])][0])
axes_1.scatter3D(data[i, 0], data[i, 1], data[i, 2], c=color[mark_index], s=12, marker=mark[mark_index])
for i in range(len(center)):
axes_1.scatter3D(center[i, 0], center[i, 1], center[i, 2], c=color[i], s=50, marker=mark[i])
axes_1.set_zlabel('Z', fontdict={'size': 15, 'color': 'red'})
axes_1.set_ylabel('Y', fontdict={'size': 15, 'color': 'red'})
axes_1.set_xlabel('X', fontdict={'size': 15, 'color': 'red'})
plt.show()
pass
def k_means_2d():
data = get_rand_data(100, 2) # 生成二维的数据点
center, cluster_assment, cnt = k_means(data, 6)
print("分类的次数: ", cnt)
# print(cluster_assment)
plot_points_2d(data, center, cluster_assment)
def k_means_3d():
data = get_rand_data(100, 3) # 生成三维数据点
center, cluster_assment, cnt = k_means(data, 4)
print("分类的次数: ", cnt)
# print(cluster_assment)
plot_points_3d(data, center, cluster_assment)
if __name__ == "__main__":
k_means_2d()
# k_means_3d()
3. 结果
3.1 关于 matplotlib.pyplot 中绘制点的形状和颜色
- mark点的形状

- 颜色缩写

3.2 分类的结果