基本思想
K-means 是一种基本的、经典的聚类方法,也被称为K-平均或K-均值算法,是一种广泛使用的聚类算法。K-Means算法是聚焦于相似的无监督的算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。其算法具体的步骤为
其中,
n
n
n为样本数,
μ
i
\mu_i
μi 为聚类中心(Clustering Center),
c
c
c 为聚类类别数量。
下面我们通过一个具体的例子来体会体会其思想,进而得到一般化的程序。
一个简单的例子
假定我们现有数据集
% data set;
Sigma = [1, 0; 0, 1];
mu1 = [1, -1];
x1 = mvnrnd(mu1, Sigma, 200);
mu2 = [5, -4];
x2 = mvnrnd(mu2, Sigma, 200);
mu3 = [1, 4];
x3 = mvnrnd(mu3, Sigma, 200);
mu4 = [6, 4];
x4 = mvnrnd(mu4, Sigma, 200);
mu5 = [7, 0.0];
x5 = mvnrnd(mu5, Sigma, 200);
其中每个 x i x_i xi对应着一个类别标签, 即
X = [x1; x2; x3; x4; x5];
X_label = [ones(200, 1); 2 * ones(200, 1); 3 * ones(200,1); 4 * ones(200, 1);5 * ones(200, 1)];
我们可以从图中看到数据的大致分布
% Show the data points
plot(x1(:,1), x1(:,2), 'r.'); hold on;
plot(x2(:,1), x2(:,2), 'b.');
plot(x3(:,1), x3(:,2), 'k.');
plot(x4(:,1), x4(:,2), 'g.');
plot(x5(:,1), x5(:,2), 'm.');

选择初始的聚类中心,聚类类别数
我们先取聚类类别数 k = 5 k=5 k=5,也就是说我们学习的任务便是将此数据分为5类; 在选择聚类中心的时候,我们有两种方式:
- 在样本集中随机选择 k k k 个点作为聚类中心;
- 在数据集分布的范围内随机选取
k
k
k个点作为聚类中心。
但是,我们试想,如果所有的初始聚类中心都在某一类中,那么最后聚类的结果可能会很糟糕。 例如下图
 所以,我们采用这样一种方式: 随机选取初始聚类中心,可以计算所有样本点到其的距离之和。 重复这一过程
m
m
m 次,从而得到
m
m
m 个对应的距离,我们将距离最小的一次对应的初始聚类中心作为最终的初始聚类中心。
所以,我们采用这样一种方式: 随机选取初始聚类中心,可以计算所有样本点到其的距离之和。 重复这一过程
m
m
m 次,从而得到
m
m
m 个对应的距离,我们将距离最小的一次对应的初始聚类中心作为最终的初始聚类中心。
% select initial clustering center
m = 30;
a = max(X);
b = min(X);
mu = zeros(k,2*m);
r = zeros(m,1);
for t=1:m
for i=1:k
mu(i,2*t-1:2*t)=[a(1)+(b(1)-a(1))*rand,a(2)+(b(2)-a(2))*rand];
end
for j = 1 : 1000
R = repmat(X(j, :), k, 1) - mu(:,2*t-1:2*t);
r(t) = r(t) + sum(sum(R.*R));
end
end
p = find(r==min(r));
mu = mu(:,2*p-1:2*p);
计算迭代过程
给定聚类中心后,每个样本点到初始聚类中心距离便也随之确定,我们将 x x x划分到距离最小所对应的那个类中,遍历所有 x x x后,更新聚类中心(均值)。若聚类中心不在变化,我们便认为聚类结束。
label = zeros(1000, 1);
mu_new = mu;
eps = 1e-6;
delta = 1;
while (delta > eps)
mu = mu_new;
for i =1:1000
y = repmat (X(i, :), k, 1);
dist = y - mu;
d = sum(dist.*dist,2);
j = find(d==min(d));
label(i) = j;
end
for j = 1 : k
order = find(label == j);
mu_new(j, :) = mean(X(order, :), 1);
end
delta = sqrt(sum(sum((mu-mu_new).*(mu-mu_new))));
end
根据聚类中心来确定样本聚类
将上述过程确定的聚类中心记为 μ \mu μ, 通过计算 x x x与 μ \mu μ的距离,便能确定 x x x对应的类别。
label = zeros(1000, 1);
for i = 1 : 1000
R = repmat(X(i,:),k,1) - mu;
Residual = sum(R.*R,2);
j = find(Residual == min(Residual));
label(i) = j;
end
注意,此处有一个问题:数据集聚类后的标签与原始标签可能不相等。比方说,原始 x 1 , ⋯ , x 5 x_1,\cdots,x_5 x1,⋯,x5 对应的标签为1,2,3,4,5;经过聚类之后其对应的标签为3,1,2,4,5。 从几何上来看,聚类结果和原来结果是完全一致的,所以我们需要引进一个map来处理这样的情况。
% Construct map function
s = zeros(k, 1);
for j =1 : k
order = find(label==j);
Y = X_label(order);
s(j) = mode(Y);
end
map_label =zeros(1000, 1);
for j = 1 : k
map_label(label==j) = s(j);
end
聚类结果
至此,我们的聚类结果为
figure;
hold on;
for i =1:1000
if map_label(i)==1
plot(X(i,1),X(i,2),'r.');
elseif map_label(i)==2
plot(X(i,1),X(i,2),'b.');
elseif map_label(i)==3
plot(X(i,1),X(i,2),'k.');
elseif map_label(i)==4
plot(X(i,1),X(i,2),'g.');
else
plot(X(i,1),X(i,2),'m.');
end
end
% show the cluster center
for i = 1 : 5
plot(mu(i,1),mu(i,2),'yo','LineWidth',3);
end
 聚类结果" />
聚类结果" />
评价指标
我们采用两种评价指标


% Calculate NMI(Normalized Mutual Information)
d = zeros(5, 1);
g = d;
sigma = zeros(5,5);
numerator = 0;
denominator1 = 0;
denominator2 = 0;
for i = 1 : 5
d(i) = length(find(map_label==i));
g(i) = length(find(X_label==i));
end
for i = 1 : 5
for j = 1 : 5
order = find(map_label==i);
sigma(i,j) = length(find(X_label(order)==j));
if sigma(i,j)~=0
numerator = numerator + sigma(i,j).*log(1000.*sigma(i,j)./(d(i).*g(j)));
end
end
end
for i = 1 : 5
if d(i)~=0
denominator1 = denominator1 + d(i).*log(d(i)/1000);
end
if g(i)~=0
denominator2 = denominator2 + g(i).*log(g(i)/1000);
end
end
denominator = sqrt(denominator1 * denominator2);
NMI = numerator/denominator;
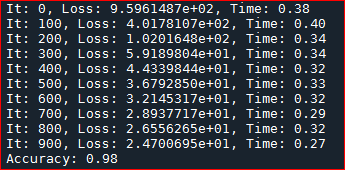
fprintf('NMI=%.3f\n',NMI);
accuracy = sum(map_label == X_label)/1000;
fprintf('accuracy=%.3f\n',accuracy);
结果为 N M I = 0.93 , A c c u r a c y = 0.978. NMI=0.93,\quad Accuracy=0.978. NMI=0.93,Accuracy=0.978.
一般化的Kmeans程序
对上述程序稍加修改,便得到了较为一般的聚类程序(无标签)
function [idx, mu] = k_means3(X,k)
% X: data set;
% k:the number of classfication
% mu:clustering center
% idx:label
if nargin<1
% data set;
Sigma = [1, 0; 0, 1];
mu1 = [1, -1];
x1 = mvnrnd(mu1, Sigma, 200);
mu2 = [5, -4];
x2 = mvnrnd(mu2, Sigma, 200);
mu3 = [1, 4];
x3 = mvnrnd(mu3, Sigma, 200);
mu4 = [6, 4];
x4 = mvnrnd(mu4, Sigma, 200);
mu5 = [7, 0.0];
x5 = mvnrnd(mu5, Sigma, 200);
% Show the data points
plot(x1(:,1), x1(:,2), 'r.'); hold on;
plot(x2(:,1), x2(:,2), 'b.');
plot(x3(:,1), x3(:,2), 'k.');
plot(x4(:,1), x4(:,2), 'g.');
plot(x5(:,1), x5(:,2), 'm.');
X = [x1; x2; x3; x4; x5];
k = 5;
end
[n,~] = size(X);
% select initial clustering center
m = 30;
index_set = zeros(m, k);
r = zeros(m, 1);
for i=1:m
index_set(i, :) = randperm(n, k);
X_init = X(index_set(i,:),:);
for j = 1 : n
R = repmat(X(j, :), k, 1) - X_init;
r(i) = r(i) + sum(sum(R.*R));
end
end
p = find(r==min(r));
final_index = index_set(p,:);
X_init = X(final_index, :);
label = zeros(n, 1);
mu = X_init;
mu_new = mu;
eps = 1e-6;
delta = 1;
while (delta > eps)
mu = mu_new;
for i =1:n
y = repmat (X(i, :), k, 1);
dist = y - mu;
d = sum(dist.*dist,2);
j = find(d==min(d));
label(i) = j;
end
for j = 1 : k
order = find(label == j);
mu_new(j, :) = mean(X(order, :), 1);
end
delta = sqrt(sum(sum((mu-mu_new).*(mu-mu_new))));
end
label = zeros(n, 1);
for i = 1 : n
R = repmat(X(i,:),k,1) - mu;
Residual = sum(R.*R,2);
j = find(Residual == min(Residual));
label(i) = j;
end
idx = label;
end
下一篇我们将用最简单的全连接神经网络(DNN)来解决解决此问题。



![【转载】Visual Studio 2010- IntelliTrace(智能跟踪)[优化c盘]](https://pic002.cnblogs.com/img/baobao267/201007/2010071316254893.jpg)