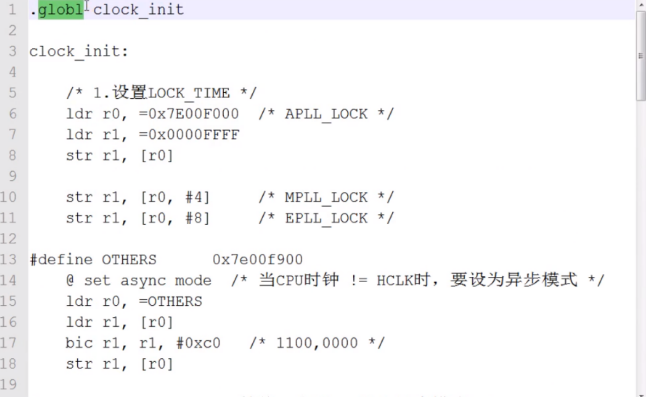
K近邻算法(KNN)
有监督机器学习
KNN是分类算法
1.思想:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。简单来说就是你离那个样本最近你就属于那个类别。
2.运用欧式距离作为公式


3.KNN需要做标准归一化处理。
参数n_neighbors=5:取最近的5个值
# 训练数据
knn = KNeighborsClassifier(n_neighbors=5)
# fit, predice, score
knn.fit(X_train, y_train)
y_predict = knn.predict(X_test)
print("预测目标位置为", y_predict)
# 得出准确率
print("预测准确率", knn.score(X_test, y_test))KNN优点:
算法简单,易于实现,无需估计参数,无需训练
KNN存在的问题:
(1)K的取值:
K的取值小,容易受异常点的影响(K值选择不当则分类精度不能保证)
K的取值大,容易受K值数量(类别)的波动
(2)性能问题
KNN是所有样本对中心点计算距离,所以时间复杂度高。
KNN在实际场景中运用很少,适合小数据场景,几千几万的样本。
K-means
1.思想:
初始随机给定K(超参数)个簇中心,这K个簇中心是在样本点中随机选择。
按照最邻近原则把待分类的样本点分到各个簇。
划分完成后按平均法重新计算各个簇的质心,从而在确定新的簇心。
一直迭代,直到簇心的移动距离小于某个给定的值。
2.k-means算法评价准则:误差平方和准则,误差平方和达到最优(小)时,可以使类内尽可能紧凑,聚类之间尽可能分开。
loss损失:是一个非凸函数,所以有许多最小值,不一定每次都能落到全局最优,有可能落到局部最优。

k:簇的个数
Ci:某个簇
p:某个簇中的点
mi:是簇Ci的均值
3.k-means是假设不同的簇服从了方差一样,均值不同的高斯分布。

k-means算法loss损失函数推导
我们直到k-means聚类算法是把样本分成k个聚类,每个聚类服从不同方差的正态分布,所以有最大似然估计将每个聚类中的每个样本的概率进行相乘得到以下公式。
取log相乘变相加
因为k-means是假设数据服从期望是不同的,方差是一样的(定值)的正态分布
所以带入正态分布的概率密度函数,化简求得k-means损失函数

k-medoids算法
中位数代替均值,防止数据中有异常值导致分类错误
当然如果分类前就通过数据预处理把离群值处理掉,就可以直接使用k-means
K-means在sklearn中的应用
重要参数n_cluster:随着n-cluster越来越大,误差平方和inertia_越来越小
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
km = KMeans(n_clusters=3, random_state=10)
# km.fit()这一步已经完成聚类了,质心已经求出来了,簇也已经分类好了。
km.fit_transform(X_train, y_train)
# 返回预测结果
print(km.predict(X_test))
# 返回质心坐标
print(km.cluster_centers_)
# 返回总距离的平方和,我们希望他越小越好
print(km.inertia_)
kmeans没有一个固定的评估指标
我们可以通过衡量簇内的差异越小,簇外的差异越大来衡量kmeans效果。
轮廓系数:
a:样本与同一簇中其他点之间的距离之和
b:样本与下一个最近的簇中所有点的距离之和
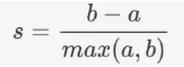
轮廓系数范围是(-1,1)其中值越接近于1代表样本与自己所在的簇样本很相似,与其他簇样本不相似。
当样本点与簇外样本点更相似的时候,轮廓系数为负。
当轮廓系数为0时,代表两个簇相似度一直,两个簇本应该是一个簇。
所以簇的轮廓系数高,说明聚类是合适的
簇的轮廓系数小甚至是负值,则说明聚类不合适,超参数k设置太大或者太小。
from sklearn.metrics import silhouette_score
print(silhouette_score(X_train, km.labels_))K个质心初始化
一个好的质心会让算法计算的更快。
init:可输入k-means++或者random,默认是k-means++使得初始质心彼此远离。
正常情况下k-means++比random迭代次数更少。
如何让迭代停下来(当质心不在移动的时候)
max_inter:最大迭代次数,默认300
tol:默认1e-4,两次Inertia下降的量,如果两次迭代之间Inertia下降的量小于tol所设定的值,迭代就会停下来。