目录
一、基础简介
二、实验步骤
1、特征提取
2、学习“视觉词典(visual vocabulary)”
3、根据IDF原理,计算视觉单词的权
4、针对特征集,根据视觉词典进行量化
5、对输入图像,根据TF-IDF转化成视觉单词的频率直方图
6、构造特征到图像的到排表,快速索引相关图像
7、根据索引结果进行直方图匹配
三、实验代码
1、利用爬虫获取数据集
2、sift提取特征并建立视觉词典
3、 创建索引,建立数据库
4、图像检索
5、遇到的问题
一、基础简介
图像特征匹配
- 暴力匹配法:250000 张图像约有310亿个图像对 ,每个图相对2秒 匹配 500台并行计算机需要1 年才能完成计算;1000000 张图像约有 5000亿个图像对 ,500台并行计算机需要15 年才能完成计算。
- 对于大场景数据集(如城市场景), 只有少 于 0.1% 的图像对具有匹配关系。
- 解决方案: 利用图像整体特征实现匹配/检索, 而非局部特征点。
BOW其实是Bag of words的缩写,也叫做词袋。BOW模型最早出现在自然语言处理和文本检索领域。该模型忽略掉文本的语法、语序等要素,吧文档看做若干词汇的集合,文档中的单词是独立出现的,使用一组无序的单词(words)表达一个文档,根据文档中单词的统计信息完成对文本的分类。

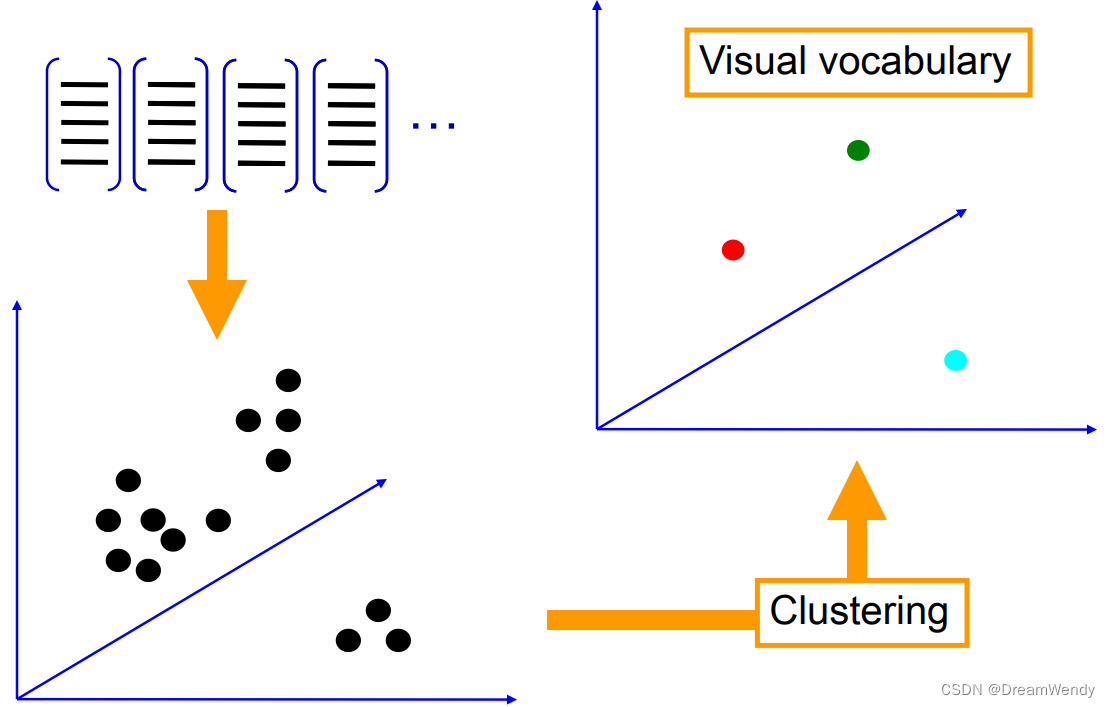
BOF是Bag-of-Features模型,其仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
二、实验步骤
1、特征提取
本次实验采用sift方法做特征提取,构造sift特征数据库。关于sift算法相关内容可查看以前相关的博客内容,不再多做解释。

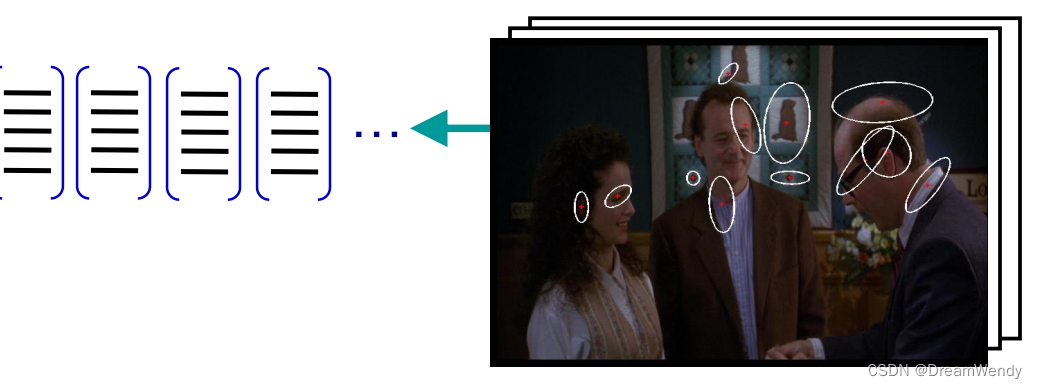
2、学习“视觉词典(visual vocabulary)”
采用k-means聚类算法对提取出的特征点进行分类处理,将聚类得出的聚类中心称为视觉单词,用来作投票依据,而视觉单词组成的集合称为视觉词典/码本。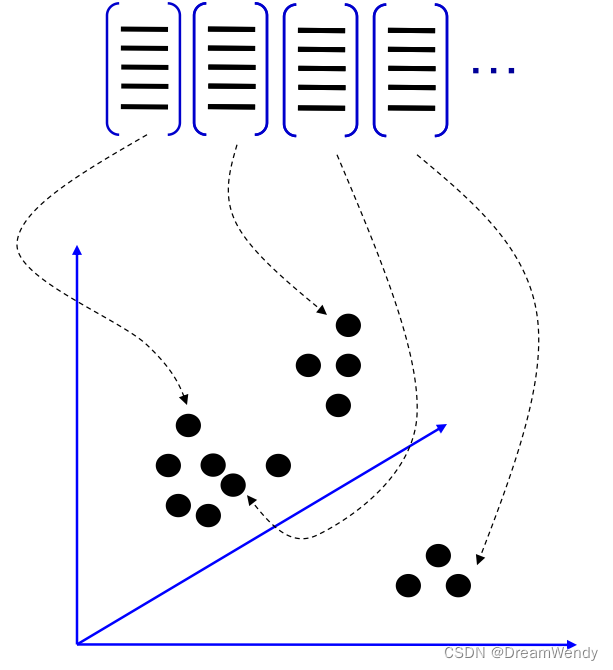

k-means算法流程:
(1)随机初始化 K 个聚类中心
(2)重复下述步骤直至算法收敛:
①对应每个特征,根据距离关系赋值给某个中心/类别;
②对每个类别,根据其对应的特征集重新计算聚类中心。聚类是实现 visual vocabulary/codebook的关键:
- 无监督学习策略
- k-means 算法获取的聚类中心作为视觉单词(codevector)
- 视觉词典/码本(visual vocabulary/codebook)可以通过不同的训练集协同训练获得
- 一旦训练集准备足够充分, 训练出来的视觉词典/码本(visual vocabulary/codebook)将具有普适性

3、根据IDF原理,计算视觉单词的权
每个视觉单词的权重是不一样的,这与视觉词典的规模有关,词典规模大,计算量大,容易过拟合,词典规模小,无法覆盖所有可能的情况。
4、针对特征集,根据视觉词典进行量化
这一步骤将我们输入的特征集合,映射到上一步做来的码本之中。通过计算输入特征到视觉单词的距离,然后将其映射到距离最近的视觉单词中,并计数,投票量化。
码本/字典用于对输入图片的特征集进行量化 :
- 对于输入特征,量化的过程是将该特征映射到距离其最接近的codevector ,并实现计数
- 码本 = 视觉词典
- Codevector = 视觉单
5、对输入图像,根据TF-IDF转化成视觉单词的频率直方图
这一步骤通过对图像特征提取,然后将提取出来的特征点,根据第四步,转换为频率直方图。
Bag of features: 单词权重
- 在文本检索中,不同单词对文本检索的贡 献有差异
- the bigger fraction of the documents a word appears in, the less useful it is for matching – e.g., a word that appears in all documents is not helping
Bag of features: 单词的TF-IDF权重
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率),是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。总而言之就是, 一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
TF为词频,指的是某一个给定的词语在该文件中出现的次数。单词 w 在文档 d 中的词频是:
其中nw 是单词 w 在文档 d 中出现的次数。为了归一化,将 nw 除以整个文档中单词的总数。
逆向文件频率IDF是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。其计算公式为:
|D| 是在语料库 D 中文档的数目,分母是语料库中包含单词 w 的文档数 d。将两者相乘可以得到矢量 v 中对应元素的 tf-idf 权重。

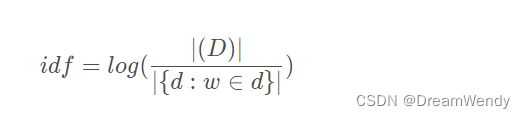
6、构造特征到图像的到排表,快速索引相关图像
倒排表是一种逆向的查找方式,通过对视觉词汇的反向查找,会得到拥有同一视觉词汇的图像集合,反复多次就能得到一张倒排表。倒排表可以快速的得到新的图像与数据库里相似的图像。
比如,对于下述两个文本而言:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
之前是:
1:[ “Jim”, “too”]
2:[“also”, “football”, “games”,]
经过倒排后是:
“Jim”:[1]
“too”:[1]
“also”:[2]
“football”:[2]
“games”:[2]
对于图像来说,经过倒排后,就是视觉单词:[视觉单词所出现的图像集合]。倒排表可以快速使用反转文件来计算新图像与数据库中所有图像之间的相似性,仅考虑其分档与查询图像重叠的数据库图像,大大减少了匹配次数,优化了算法。
7、根据索引结果进行直方图匹配
根据欧式距离求解,进行相似度排序。
视觉词典存在的问题:
①如何选择视觉词典/码本的规模?
- 太少:视觉单词无法覆盖所有可能出现的情况
- 太多: 计算量大,容易过拟合
②如何提升计算效率?
- Vocabulary trees (Nister & Stewenius, 2006)
三、实验代码
1、利用爬虫获取数据集
import requests
import os
import urllib
# 爬虫类
class Spider_baidu_image():
def __init__(self):
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36'}
self.headers_image = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36',
'Referer': 'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1557124645631_R&pv=&ic=&nc=1&z=&hd=1&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E8%83%A1%E6%AD%8C'}
self.keyword = input("请输入搜索图片关键字:")
self.paginator = int(input("请输入搜索页数,每页30张图片:"))
# 获取url请求的参数,存入列表并返回
def get_param(self):
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1, self.paginator + 1):
params.append('tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0©right=0&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=star&pn={}&rn=30&gsm=78&1557125391211='.format(keyword, keyword, 30 * i))
return params
# 由url参数返回各个url拼接后的响应,存入列表并返回
def get_urls(self, params):
urls = []
for i in params:
urls.append(self.url + i)
return urls
# 获取图像url
def get_image_url(self, urls):
image_url = []
for url in urls:
json_data = requests.get(url, headers=self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
# 根据图片url,在本地目录下新建一个以搜索关键字命名的文件夹,然后将每一个图片存入。
def get_image(self, image_url):
cwd = os.getcwd()
file_name = os.path.join(cwd, self.keyword)
if not os.path.exists(self.keyword):
os.mkdir(file_name)
for index, url in enumerate(image_url, start=1):
with open(file_name + '\\{}.jpg'.format(index), 'wb') as f:
f.write(requests.get(url, headers=self.headers_image).content)
if index != 0 and index % 30 == 0:
print('{}第{}页下载完成'.format(self.keyword, index / 30))
def __call__(self, *args, **kwargs):
params = self.get_param()
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url)
if __name__ == '__main__':
spider = Spider_baidu_image()
spider()
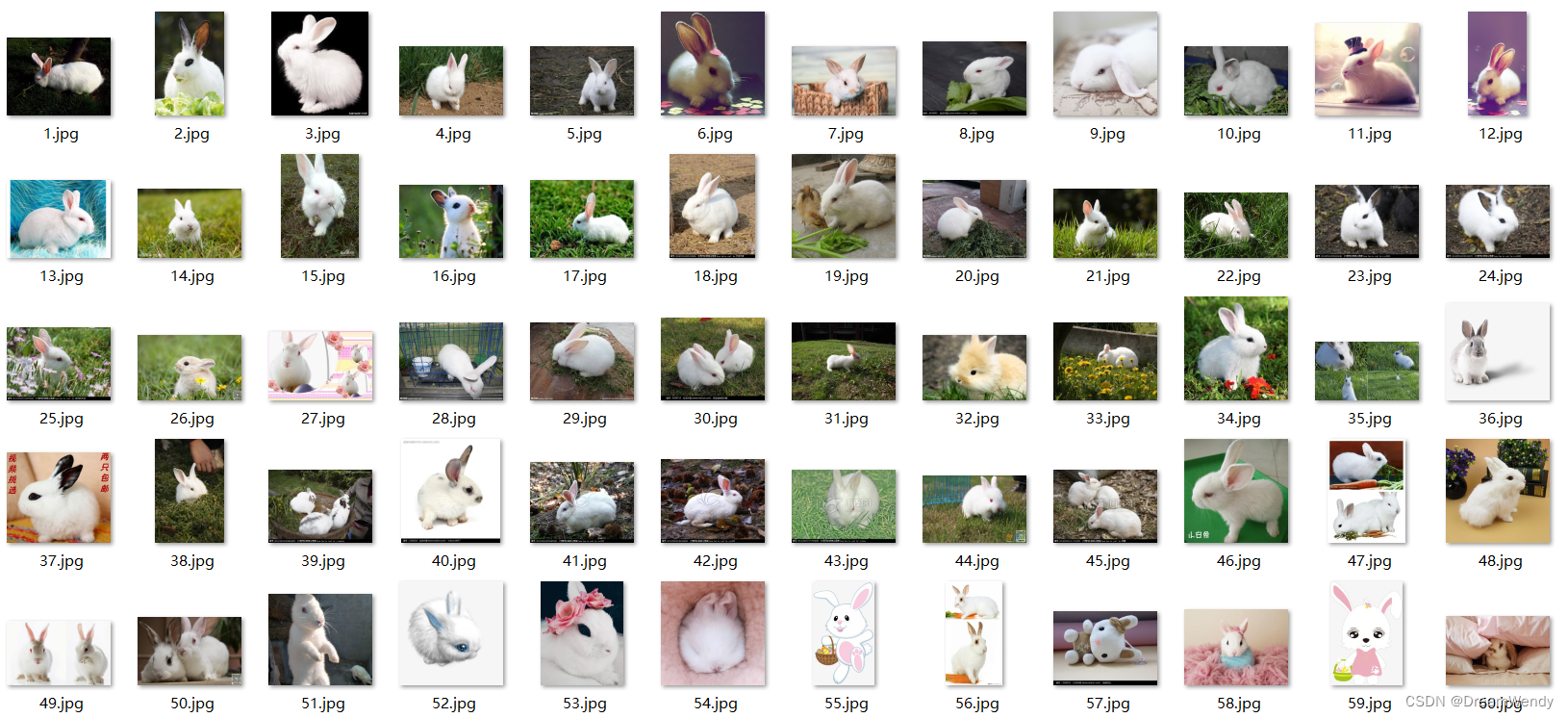
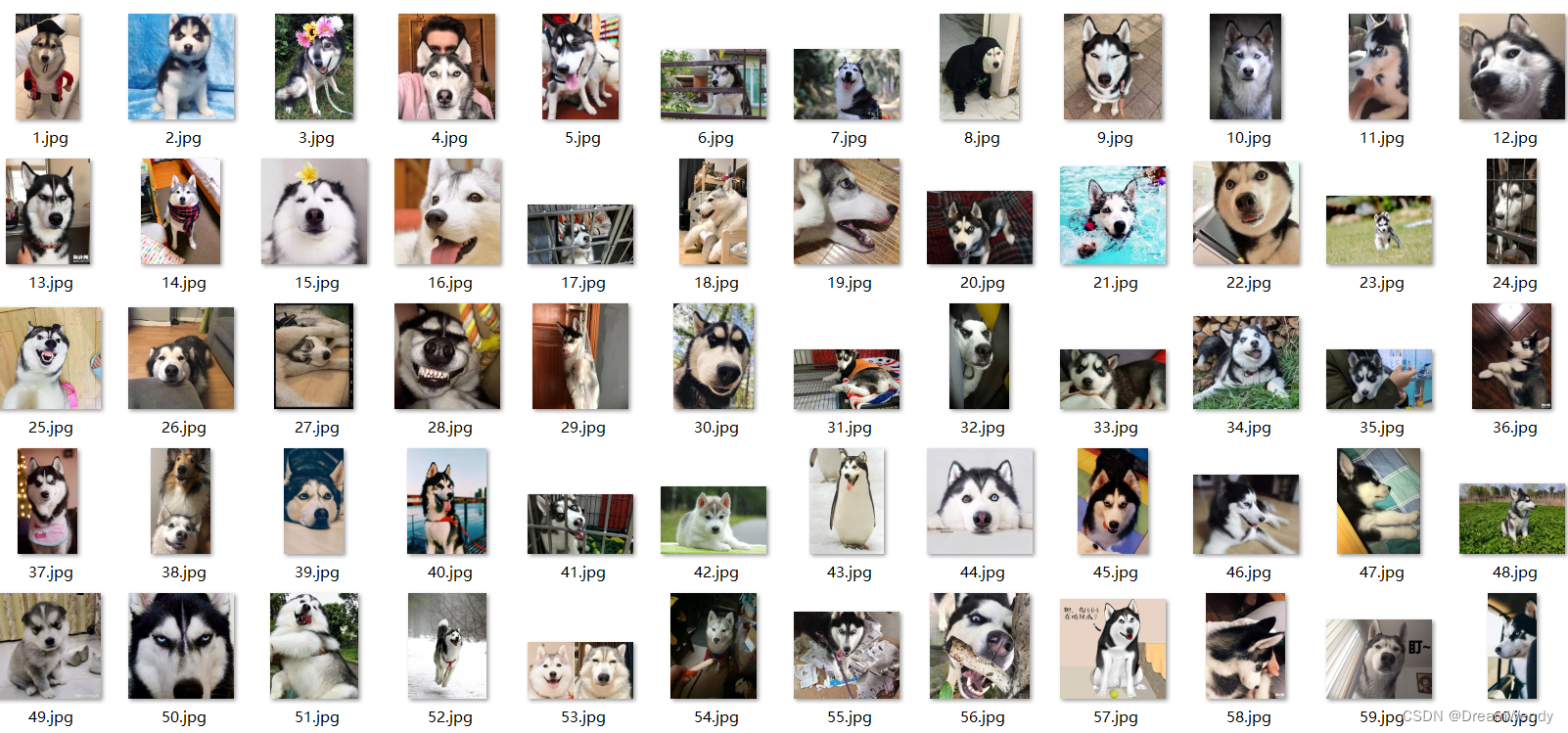
本次实验的数据集共有240张图片,分别在4个不同对象,以下是数据集展示:

2、sift提取特征并建立视觉词典
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
# 获取图像列表
imlist = get_imlist("D:\\python\\workSpace\\ComputerVision\\Test5\\image")
nbr_images = len(imlist)
# 获取特征列表
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
# 提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
# 生成词汇
voc = vocabulary.Vocabulary('test77_test')
voc.train(featlist, 100, 10)
# 保存词汇.将生成的词汇保存到vocabulary.pkl(f)中
with open('D:\\python\\workSpace\\ComputerVision\\Test5\\image\\vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print('vocabulary is:', voc.name, voc.nbr_words)
3、 创建索引,建立数据库
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
# 图像索引
# 获取图像列表
imlist = get_imlist("D:\\python\\workSpace\\ComputerVision\\Test5\\image")
nbr_images = len(imlist)
# 获取特征列表
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
# 载入词汇
with open("D:\\python\\workSpace\\ComputerVision\\Test5\\image\\vocabulary.pkl", 'rb') as f:
voc = pickle.load(f)
# 创建索引
indx = imagesearch.Indexer('testImaAdd.db', voc) # 创建索引器Indexer类
indx.create_tables()
# 遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs, descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i], descr)
# 提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print(con.execute('select count (filename) from imlist').fetchone())
print(con.execute('select * from imlist').fetchone())![]()
4、图像检索
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# 载入图像列表
imlist = get_imlist('D:\\python\\workSpace\\ComputerVision\\Test5\\image')
nbr_images = len(imlist)
# 载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# 载入词汇
with open('D:\\python\\workSpace\\ComputerVision\\Test5\\image\\vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
# 查询图像索引和查询返回的图像数
q_ind = 1
nbr_results = 5
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)
# 载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# 用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# 载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx])
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:5]) # 常规查询
imagesearch.plot_results(src,res_geom[:5]) # 重排后的结果
以第一张图片为检索图片,而后面的四张图片则是匹配到的图片,可以看出柴犬的图像检索匹配出的图像相似度较高。
5、遇到的问题