什么是RFM模型
RFM模型是衡量客户价值和客户创利能力的重要工具。该模型通过一个客户的近期购买行为、购买的总体频率,以及花了多少钱三项指标来描述该客户的价值状况。
如何构建RFM模型
最近一次消费 (Recency)
最近一次消费意指上一次购买的时间——用户上一次是什么时候下的单、用户上一次是什 么时候订购的服务,或在线下门店中用户上一次进店购买是什么时候。
消费频率 (Frequency)
消费频率是顾客在限定的期间内所购买的次数。一般而言,最常购买的用户,也是满意度/忠诚 度最高的顾客,同时也是对品牌认可度最高的用户。
消费金额 (Monetary)
消费金额是电商相关业务数据库的支柱,也可以用来验证“帕雷托法则”——公司80%的收 入来自20%的顾客。M值带有时间范围,指的是一段时间(通常是1年)内的消费金额。对于 一般电商店铺而言,M值对客户细分的作用相对较弱(因为客单价波动幅度不大)。
实战
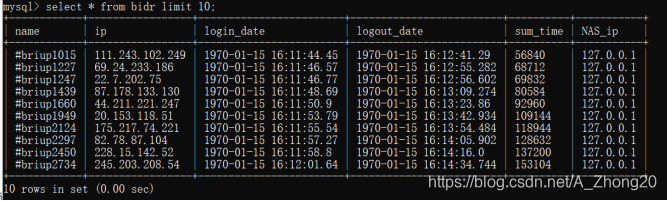
假如我们有如下某餐饮店铺的用户RFM数据,只显示了前15条数据

我们通过聚类方法:K-Means聚类算法(非监督的学习算法)
算法过程:
- 从n个样本数据中随机挑选k个对象作为初始的聚类中心。
- 分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
- 所有对象分配完成后,重新计算k个聚类的中心。
- 与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转至步骤2,否则转至步骤5
- 当质心不发生变化时,停止并输出聚类结果。
import pandas as pd
inputfile = '/content/consumption_data.xls'
outputfile = '/content/data_type.xls'
k = 3 # 聚类的类别
iteration = 500 # 聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') # 读取数据
data_zs = 1.0*(data - data.mean())/data.std() # 数据标准化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration,random_state=1234) # 分为k类,并发数4
model.fit(data_zs) # 开始聚类
# 简单打印结果
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心
r = pd.concat([r2, r1], axis = 1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + ['类别数目'] # 重命名表头
print(r)
# 详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) # 详细输出每个样本对应的类别
r.columns = list(data.columns) + ['聚类类别'] # 重命名表头
r.to_excel(outputfile) # 保存结果
def density_plot(data): # 自定义作图函数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel(u'密度') for i in range(k)]
plt.legend()
return plt
pic_output = '/content/' # 概率密度图文件名前缀
for i in range(k):
density_plot(data[r[u'聚类类别']==i]).savefig(u'%s%s.png' %(pic_output, i))
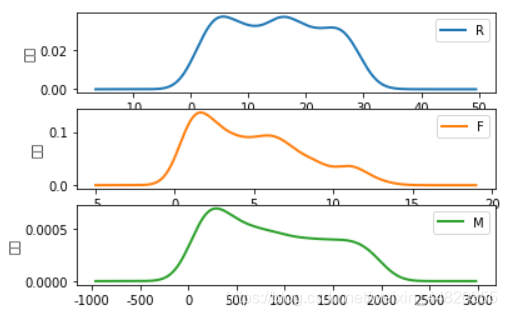
这时我们可以得到K-means的输出结果
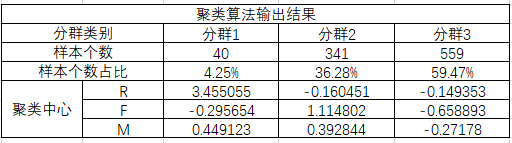
不同用户的RFM聚类类别结果

分群1的特点:R间隔分布较大,间隔分布在30至80天左右,消费次数集中在0~15次,消费金额在0-2000左右。精细化运营:老用户召回的方法,回归礼包什么的,加打优惠力度

分群2的特点:R间隔分布较小,间隔分布在0至30天左右,消费次数集中在10~30次,消费金额在500-2000左右。精细化运营:加大用户粘性,推荐办一个会员

分群3的特点:R间隔分布较小,间隔分布在0至30天左右,消费次数集中在0~12次,消费金额在0-1800左右。精细化运营:由于客单价偏低,针对用户购物链去推荐相应的产品