层次聚类假设类别之间存在层次结构,将样本聚到层次化的类中层次聚类又有聚合或自下而上、分裂或自上而下两种方法。
- 聚合聚类开始将每个样本各自分到一个类;之后将相距最近的两类合并,建立一个新的类,重复此操作直到满足停止条件;得到层次化的类别。
- 分裂聚类开始将所有样本分到一个类;之后将已有类中相距最远的样本分到两个新的类,重复此操作直到满足停止条件;得到层次化的类别。
层次聚类之聚合(自下向上)
python">import math
import random
import numpy as np
from sklearn import datasets,cluster
import matplotlib.pyplot as plt
iris = datasets.load_iris()
gt = iris['target']
print(gt.shape) # (150,) 是0,1或者2,共3分类
print(iris['data'][:,:2].shape) # (150, 2)
data = iris['data'][:,:2]
x = data[:, 0]
y = data[:, 1]
plt.figure('初始分布')
plt.scatter(x, y, color='blue')
plt.xlim(4, 8)
plt.ylim(1, 5)
plt.title('initialization distrubution')
plt.show()
print('------------------------------------')
# 定义聚类数的节点
class ClusterNode:
def __init__(self, vec, left=None, right=None, distance=-1, id=None, count=1):
"""
:param vec: 保存两个数据聚类后形成新的中心
:param left: 左节点
:param right: 右节点
:param distance: 两个节点的距离
:param id: 用来标记哪些节点是计算过的
:param count: 这个节点的叶子节点个数
"""
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
self.count = count
def euler_distance(point1: np.ndarray, point2: list) -> float:
"""
计算两点之间的欧拉距离,支持多维
"""
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
# 层次聚类(聚合法,自下而上)
class Hierarchical:
def __init__(self, k):
"""
:param k: 聚类类别数
"""
self.k = k
self.labels = None
def fit(self, x): # x是数据
nodes = [ClusterNode(vec=v, id=i) for i, v in enumerate(x)]
distances = {}
point_num, feature_num = x.shape # 150 2
self.labels = [-1] * point_num # (150,) label全-1
currentclustid = -1
while (len(nodes)) > self.k:
min_dist = math.inf # 正无穷
nodes_len = len(nodes)
closest_part = None # 距离最近的节点对id
# 两两节点计算距离
for i in range(nodes_len - 1):
for j in range(i + 1, nodes_len):
d_key = (nodes[i].id, nodes[j].id)
if d_key not in distances:
distances[d_key] = euler_distance(nodes[i].vec, nodes[j].vec)
d = distances[d_key]
if d < min_dist:
min_dist = d
# 计算哪两个节点的距离在所有两两节点中最小
closest_part = (i, j)
part1, part2 = closest_part
node1, node2 = nodes[part1], nodes[part2]
# 计算两个距离最近的节点的中心点(叶子节点数目决定权重)
new_vec = [(node1.vec[i] * node1.count + node2.vec[i] * node2.count) / (node1.count + node2.count)
for i in range(feature_num)]
new_node = ClusterNode(vec=new_vec,
left=node1,
right=node2,
distance=min_dist,
id=currentclustid,
count=node1.count + node2.count)
currentclustid -= 1
# 删掉这两个距离最近的节点
del nodes[part2], nodes[part1]
# 加上这两个节点的中心节点
nodes.append(new_node)
self.nodes = nodes
self.calc_label()
def calc_label(self):
"""
调取聚类的结果
"""
for i, node in enumerate(self.nodes):
# 将节点的所有叶子节点都分类
self.leaf_traversal(node, i)
def leaf_traversal(self, node: ClusterNode, label):
"""
递归遍历叶子节点, 最后会得到 k个根节点,代表 k类,某个根节点下面的所有叶节点属于一类
"""
if node.left == None and node.right == None:
self.labels[node.id] = label
if node.left:
self.leaf_traversal(node.left, label)
if node.right:
self.leaf_traversal(node.right, label)
my = Hierarchical(3) # 定义3分类
my.fit(data)
labels = np.array(my.labels)
print(labels.shape) # (150,)
# visualize result
cat1 = data[np.where(labels == 0)]
cat2 = data[np.where(labels == 1)]
cat3 = data[np.where(labels == 2)]
plt.figure('层次聚类之聚合')
plt.scatter(cat1[:,0], cat1[:,1], color='green')
plt.scatter(cat2[:,0], cat2[:,1], color='red')
plt.scatter(cat3[:,0], cat3[:,1], color='blue')
plt.title('Hierarchical clustering with k=3')
plt.xlim(4, 8)
plt.ylim(1, 5)
plt.show()
print('----------------------------------------------')
sk = cluster.AgglomerativeClustering(3)
sk.fit(data)
labels_ = sk.labels_
print(labels_.shape) # (150,)
# visualize result of sklearn
cat1_ = data[np.where(labels_==0)]
cat2_ = data[np.where(labels_==1)]
cat3_ = data[np.where(labels_==2)]
plt.figure('sklearn 层次聚类')
plt.scatter(cat1_[:,0], cat1_[:,1], color='green')
plt.scatter(cat2_[:,0], cat2_[:,1], color='red')
plt.scatter(cat3_[:,0], cat3_[:,1], color='blue')
plt.title('sklearn Hierarchical clustering with k=3')
plt.xlim(4, 8)
plt.ylim(1, 5)
plt.show()



K-means聚类
. k k k均值聚类是常用的聚类算法,有以下特点。基于划分的聚类方法;类别数k事先指定;以欧氏距离平方表示样本之间的距离或相似度,以中心或样本的均值表示类别;以样本和其所属类的中心之间的距离的总和为优化的目标函数;得到的类别是平坦的、非层次化的;算法是迭代算法,不能保证得到全局最优。
k k k均值聚类算法,首先选择k个类的中心,将样本分到与中心最近的类中,得到一个聚类结果;然后计算每个类的样本的均值,作为类的新的中心;重复以上步骤,直到收敛为止。
python">import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris = datasets.load_iris()
gt = iris['target']
print(gt.shape) # (150,) 是0,1或者2,3分类
print(iris['data'][:,:2].shape) # (150, 2)
data = iris['data'][:,:2]
x = data[:, 0]
y = data[:, 1]
plt.figure('初始分布')
plt.scatter(x, y, color='blue')
plt.xlim(4, 8)
plt.ylim(1, 5)
plt.title('initialization distrubution')
plt.show()
print('------------------------------------')
# kmeans
class MyKmeans:
def __init__(self, k, n=20):
self.k = k
self.n = n
def fit(self, x, centers=None):
# 第一步,随机选择 K 个点, 或者指定
if centers is None:
idx = np.random.randint(low=0, high=len(x), size=self.k)
centers = x[idx]
inters = 0
# n轮迭代
while inters < self.n:
# print(inters)
# print(centers)
points_set = {key: [] for key in range(self.k)}
# 第二步,遍历所有点 P,将 P 放入最近的聚类中心的集合中
for p in x:
nearest_index = np.argmin(np.sum((centers - p) ** 2, axis=1) ** 0.5)
points_set[nearest_index].append(p)
# 第三步,遍历每一个点集,计算新的聚类中心
for i_k in range(self.k):
centers[i_k] = sum(points_set[i_k]) / len(points_set[i_k])
inters += 1
return points_set, centers
m = MyKmeans(3)
points_set, centers = m.fit(data)
# visualize result
cat1 = np.asarray(points_set[0])
cat2 = np.asarray(points_set[1])
cat3 = np.asarray(points_set[2])
plt.figure('Kmeans result')
# 画中心点
for ix, p in enumerate(centers):
plt.scatter(p[0], p[1], color='C{}'.format(ix), marker='^', edgecolor='black', s=256)
plt.scatter(cat1[:, 0], cat1[:, 1], color='green')
plt.scatter(cat2[:, 0], cat2[:, 1], color='red')
plt.scatter(cat3[:, 0], cat3[:, 1], color='blue')
plt.title('kmeans with k=3')
plt.xlim(4, 8)
plt.ylim(1, 5)
plt.show()
print('---------------------------------------------------')
# sklearn K-means
kmeans = KMeans(n_clusters=3, max_iter=100).fit(data)
gt_labels__ = kmeans.labels_
print(gt_labels__.shape) # (150,)
centers__ = kmeans.cluster_centers_
print(centers__.shape) # (3,2)
# visualize result
cat1_ = data[gt_labels__ == 0]
cat2_ = data[gt_labels__ == 1]
cat3_ = data[gt_labels__ == 2]
plt.figure('sklearn K-means')
for ix, p in enumerate(centers__):
plt.scatter(p[0], p[1], color='C{}'.format(ix), marker='^', edgecolor='black', s=256)
plt.scatter(cat1_[:, 0], cat1_[:, 1], color='green')
plt.scatter(cat2_[:, 0], cat2_[:, 1], color='red')
plt.scatter(cat3_[:, 0], cat3_[:, 1], color='blue')
plt.title('kmeans using sklearn with k=3')
plt.xlim(4, 8)
plt.ylim(1, 5)
plt.show()
print('-------------------------------')
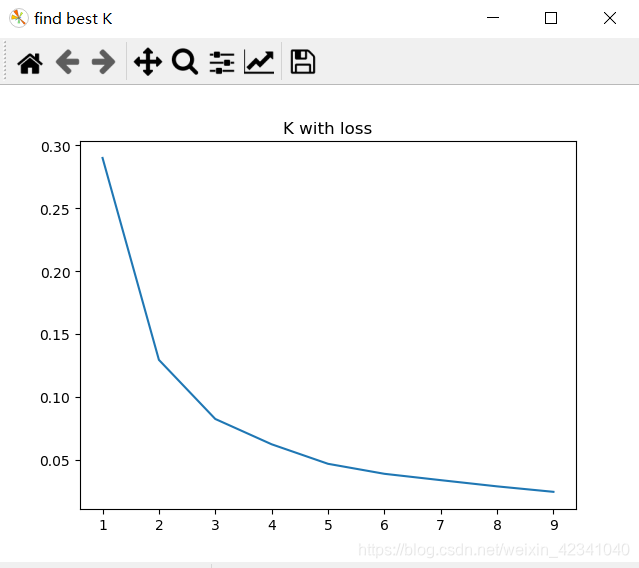
# sklearn寻找最佳k值
loss = []
for i in range(1, 10):
kmeans = KMeans(n_clusters=i, max_iter=100).fit(data)
loss.append(kmeans.inertia_ / len(data) / 3)
plt.figure('find best K')
plt.title('K with loss')
plt.plot(range(1, 10), loss)
plt.show()