目录
一、K-means聚类
二、层次聚类
三、密度聚类
四、聚类方法比较
五、聚类效果评价方法
一、K-means聚类
1、算法原理:
- 首先任取k个样本点作为k个簇的初始中心;
- 对每一个样本点,计算它们与k个中心的距离,把它归入距离最小的中心所在的簇;
- 等到所有的样本点归类完毕,重新计算k个簇的中心;
- 重复以上过程直至样本点归入的簇不再变动,或者簇中心的位置移动小于阈值;
2、优点:
- 是解决聚类问题的一种经典算法,简单、快速
- 对处理大数据集,该算法保持可伸缩性和高效率
- 当结果簇是密集的,它的效果较好
3、问题:
- 类别数目K需要预设;
- 初始聚类中心的选取是随机的,着会直接影响最终的聚类效果;
- 每次迭代都要重新计算各个点和质心的距离,然后排序,时间成本高;
- 在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用;
- 不适合于发现非凸形状的簇或者大小差别很大的簇
- 对噪声和孤立点数据敏感
优化策略:k-means++:初始seeds,选择相互之间距离尽可能远的点;
4、参数说明:
默认参数:
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001,
precompute_distances='auto', verbose=0, random_state=None,
copy_x=True, n_jobs=None, algorithm='auto')
n-cluster :分类簇的数量
max_iter :最大的迭代次数
n_init :算法的运行次数
init :接收待定的string。kmeans++表示该初始化策略选择的初始均值向量之间都距离比较远,它的效果较好;random表示从数据中随机选择K个样本最为初始均值向量;或者提供一个数组,数组的形状为(n_cluster,n_features),该数组作为初始均值向量。
precompute_distance :接收Boolean或者auto。表示是否提前计算好样本之间的距离,auto表示如果nsamples*n>12 million,则不提前计算。
tol :接收float,表示算法收敛的阈值。
N_jobs : 表示任务使用CPU数量
random_state : 表示随机数生成器的种子。
verbose : 0表示不输出日志信息;1表示每隔一段时间打印一次日志信息。如果大于1,打印次数频繁。
5、核心代码:
import numpy as np
import sklearn.cluster as sc
import sklearn.metrics as sm
import matplotlib.pyplot as plt
x = []
with open("D:/python/data/multiple3.txt", 'r') as f:
for line in f.readlines():
data = [float(substr) for substr in line.split(',')]
x.append(data)
x = np.array(x)
print(x.shape)
# k均值聚类器
model = sc.KMeans(n_clusters=4) # n_clusters为事先预定的聚类簇数量
# 训练
model.fit(x)
cluster_labels_ = model.labels_ # 每一个点的聚类结果
cluster_centers_ = model.cluster_centers_ # 获得聚类几何中心
print('cluster_labels_: ', cluster_labels_)
print('cluster_centers_: ', cluster_centers_)
silhouette_score = sm.silhouette_score(x, cluster_labels_,
sample_size=len(x),
metric='euclidean' # 欧式距离度量方式
)
print('silhouette_score: ', silhouette_score)
print('--------可视化--------')
plt.figure('K-Means Cluster', facecolor='lightgray')
plt.title('K-Means Cluster', fontsize=16)
plt.xlabel('x', fontsize=12)
plt.ylabel('y', fontsize=12)
plt.tick_params(labelsize=10)
plt.scatter(x[:,0], x[:,1], s=50, c=cluster_labels_, cmap='brg')
plt.scatter(cluster_centers_[:,0], cluster_centers_[:,1], marker='+',
c='black', s=120, linewidths=3)
plt.show()
二、层次聚类
1、算法原理:
- 每一个样本点视为一个簇;
- 计算各个簇之间的距离,最近的两个簇聚合成一个新簇;
- 重复以上过程直至最后只有一簇。
凝聚层次聚类:AGNES算法(自底向上)
首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足
分裂层次聚类:DIANA算法(自顶向下)
首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。
2、优点:
- 不需要指定具体的簇数,只关注簇之间的远近;
- 最终会生成一个树形图,便于树模型的开发;
- 不依赖于中心点的划分,所以对于中心特征不明显的样本,划分效果更佳稳定;
3、问题:
处理速度相对较慢;
4、参数说明:
- method:以距离将凝聚层次算法分为
- ward:默认选项,使用方差作为标准,假设簇A、簇B合并后使得所有簇的方差增加最小,则选择合并A、B;
- average:
将两个簇中所有点之间平均距离最小的两个簇合并;
- complete: d(u,v) = max(dist(u[i],u[j])),将两个簇中点的最大距离最小的两个簇合并
- ‘single’: d(u,v) = min(dist(u[i],u[j])),对于u中所有点i和v中所有点j。这被称为最近邻点算法。
- weighted:d(u,v) = (dist(s,v) + dist(t,v))/2,u是由s和t形成的,而v是森林中剩余的聚类簇,这被称为WPGMA(加权分组平均)法。
-
'centroid'
Cs和Ct分别为聚类簇s和t的聚类中心,当s和t形成一个新的聚类簇时,聚类中心centroid会在s和t上重新计算。这段聚类就变成了u的质心和剩下聚类簇v的质心之间的欧式距离。这杯称为UPGMC算法(采用质心的无加权paire-group方法)。
- 'median' :当两个聚类簇s和t组合成一个新的聚类簇u时,s和t的质心的均值称为u的质心。这被称为WPGMC算法。
- ward:默认选项,使用方差作为标准,假设簇A、簇B合并后使得所有簇的方差增加最小,则选择合并A、B;
-
y:nump.ndarry。是一个压缩距离的平面上三角矩阵。或者n*m的观测值。压缩距离矩阵的所有元素必须是有限的,没有NaNs或infs。
method:str,可选。
metric:str或function,可选。在y维观测向量的情况下使用该参数,苟泽忽略。参照有效距离度量列表的pdist函数,还可以使用自定义距离函数。
optimal_ordering:bool。若为true,linkage矩阵则被重新排序,以便连续叶子间距最小。当数据可视化时,这将使得树结构更为直观。默认为false,因为数据集非常大时,执行此操作计算量将非常大。
-
返回值:
Z:numpy.ndarry。
层次聚类编码为一个linkage矩阵。
Z共有四列组成,第一字段与第二字段分别为聚类簇的编号,在初始距离前每个初始值被从0~n-1进行标识,每生成一个新的聚类簇就在此基础上增加一对新的聚类簇进行标识,第三个字段表示前两个聚类簇之间的距离,第四个字段表示新生成聚类簇所包含的元素的个数。
5、核心代码:
from scipy.cluster.hierarchy import dendrogram, linkage,fcluster
from matplotlib import pyplot as plt
X = [[i] for i in [2, 8, 0, 4, 1, 9, 9, 0]]
# X = [[1,2],[3,2],[4,4],[1,2],[1,3]]
Z = linkage(X, method='ward')
f = fcluster(Z,4,criterion='distance')
fig = plt.figure(figsize=(5, 3))
dn = dendrogram(Z)
plt.show()三、密度聚类
1、算法原理:DBSCAN聚类:

2、优点:
- 对噪声不敏感;
- 不需要提前设置聚类个数;
3、问题:
- 对初值选择敏感;
- 对密度不均的数据聚合效果不好;
- 需要提前确定Σ和M值;
4、实现代码:
import numpy as np
import sklearn.cluster as sc
import matplotlib.pyplot as plt
import sklearn.metrics as sm
x = []
with open('D:/python/data/perf.txt', 'r') as f:
for line in f.readlines():
data = [float(substr) for substr in line.split(',')]
x.append(data)
x = np.array(x)
print(x.shape)
# 模型超参数
radius = 0.8 # 邻域半径
min_samples = 5 # 聚类簇最少样本点数量
# 创建噪声密度聚类器
model = sc.DBSCAN(eps=radius, min_samples=min_samples)
# 训练模型
model.fit(x)
# 划分结果
cluster_labels_ = model.labels_
# 评价聚类模型
score = sm.silhouette_score(x, model.labels_,
sample_size=len(x),
metric='euclidean') # 轮廓系数
print('silhouette_score: ', score)
# silhouette_score: 0.6366395861050828
# 区分三类样本
# 核心样本
core_mask = np.zeros(len(x), dtype=bool)
core_mask[model.core_sample_indices_] = True
# 噪声样本
offset_mask = cluster_labels_==-1
# 边界样本
border_mask = ~(core_mask | offset_mask)
print('--------可视化--------')
plt.figure('DBSCAN Cluster', facecolor='lightgray')
plt.title('DBSCAN Cluster', fontsize=18)
plt.xlabel('x', fontsize=12)
plt.ylabel('y', fontsize=12)
plt.tick_params(labelsize=8)
plt.grid(':')
labels = set(cluster_labels_)
cs = plt.get_cmap('brg', len(labels))(range(len(labels)))
# 核心点
plt.scatter(x[core_mask][:, 0],
x[core_mask][:, 1],
c=cs[cluster_labels_[core_mask]],
s=80, label='Core')
# 边界点
plt.scatter(x[border_mask][:, 0],
x[border_mask][:, 1],
edgecolor=cs[cluster_labels_[border_mask]],
facecolor='none', s=80, label='Periphery')
# 噪声点
plt.scatter(x[offset_mask][:, 0],
x[offset_mask][:, 1],
marker='D', c=cs[cluster_labels_[offset_mask]],
s=80, label='Offset')
plt.legend()
plt.show().
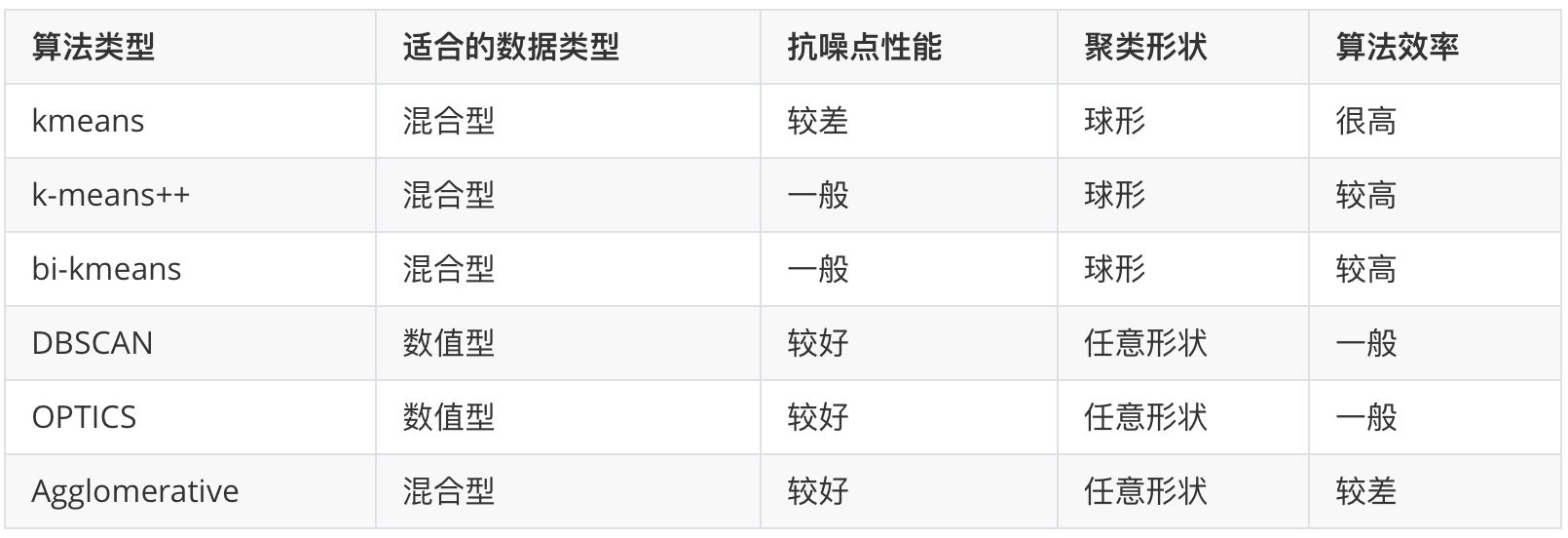
四、聚类方法比较
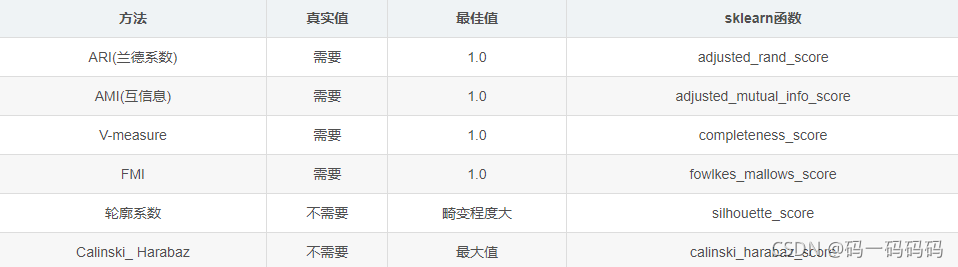
五、聚类效果评价方法
参考:
【2】常用聚类算法 - 知乎
【3】聚类方法简单总结_enginelong的博客-CSDN博客