上一篇: 数据分类
1、决策树
python"># 决策树
import pandas as pd
fname="data/lesson.csv"
dataf=pd.read_csv(fname,encoding="gbk")
# print(dataf)
# 提取x,y数据
x=dataf.iloc[:,1:5].values
y=dataf.iloc[:,5].values
# print(x)
# print(y)
for i in range(0,len(x)):
for j in range(0,len(x[i])):
thisdata=x[i][j]
if(thisdata=="是" or thisdata=="多" or thisdata=="高"):
x[i][j]=int(1)
else:
x[i][j]=int(-1)
# print(x)
for i in range(0,len(y)):
thisdata=y[i]
if(thisdata=="高"):
y[i]=1
else:
y[i]=-1
# 容易错的地方:直接dtc训练
# 正确的做法:转化格式,将x,y转化为数据框,再转化为数组并指定格式
xf=pd.DataFrame(x)
# print(xf)
yf=pd.DataFrame(y)
# print(yf)
x2=xf.values.astype(int)
y2=yf.values.astype(int)
# print(x2,y2)
# 建立决策树
from sklearn.tree import DecisionTreeClassifier as DTC
dtc=DTC(criterion="entropy") # 以信息熵的形式建立决策树
dtc.fit(x2,y2)
# 直接预测销量高低
import numpy as np
x3=np.array([[1,-1,-1,1],[1,1,1,1],[-1,1,-1,1]])
rst=dtc.predict(x3)
print(rst)
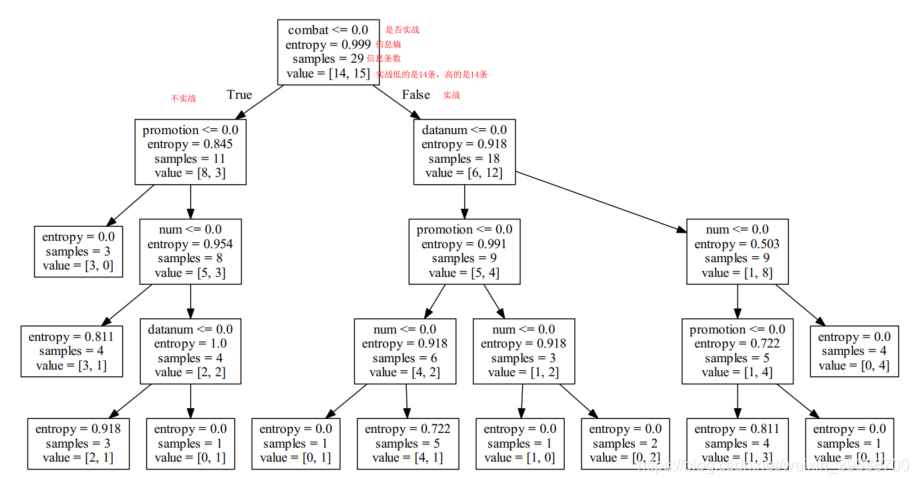
# 可视化决策树:决策树往左看是正能量,往右看是负能量
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
with open("data/dtc.dot","w") as file:
export_graphviz(dtc,feature_names=["combat","num","promotion","datanum"],out_file=file)
最后,通过Graphviz2.38转化得到是可视化决策树如下:
2、聚类概述
物以类聚,人以群分,是一种无监督学习。参考链接:聚类
3、聚类常见算法
常见的六大聚类算法
各种聚类算法(原理+代码+对比分析)最全总结
4、聚类三法
- 划分(分裂)法
- 层次分析法
- 密度分析法
- 网格法
- 模型法
5、K-means算法概述
参考学习:5 分钟带你弄懂 k-means 聚类
k-means算法的步骤:
1、随机选择k个点作为聚类中心;
2、计算各个点到这k个点的距离;
3、将对应的点聚到与他最近的这个聚类中心;
4、重新计算聚类中心;
5、比较当前聚类中心,如果是通一个人点,得到聚类结果,若为不同点,则重复2-5。
6、K-means算法实战
python">'''
k-means算法的步骤:
1、随机选择k个点作为聚类中心;
2、计算各个点到这k个点的距离;
3、将对应的点聚到与他最近的这个聚类中心;
4、重新计算聚类中心;
5、比较当前聚类中心,如果是通一个人点,得到聚类结果,若为不同点,则重复2-5。
'''
# k-means算法
'''
# 通过程序实现录取学生的聚类
import numpy as np
import pandas as pd
import matplotlib.pylab as pyl
fname="data/luqu.csv"
dataf=pd.read_csv(fname) # 得到的是数据框
# print(dataf)
x=dataf.iloc[:,1:4].values # 提取数据
# print(x)
# 聚类
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
kms=KMeans(n_clusters=2)
y=kms.fit_predict(x)
# print(y)
# x代表学生序号,y代表学生类别
s=np.arange(0,len(y))
# print(s)
pyl.plot(s,y,"o")
pyl.show()
'''
# 通过程序实现商品的聚类
import pandas as pd
import numpy as np
import matplotlib.pylab as pyl
import pymysql
# 导入数据
conn = pymysql.connect(host="127.0.0.1", user="root", passwd="123456", db="csdn")
sql = "select price,comment from taob limit 300"
dataf = pd.read_sql(sql, conn)
# print(dataf)
# 取出数据
x = dataf.iloc[:, :].values
# 聚类
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=3)
y = kms.fit_predict(x)
print(y)
for i in range(0, len(y)):
if (y[i] == 0):
pyl.plot(dataf.iloc[i:i + 1, 0:1].values, dataf.iloc[i:i + 1, 1:2].values, "*r")
elif (y[i] == 1):
pyl.plot(dataf.iloc[i:i + 1, 0:1].values, dataf.iloc[i:i + 1, 1:2].values, "sy")
elif(y[i] == 2):
pyl.plot(dataf.iloc[i:i + 1, 0:1].values, dataf.iloc[i:i + 1, 1:2].values, "pk")
pyl.show()
'''
# 作业:使用聚类来实现文本的聚类
1、用爬虫去爬100个百度百科的词条内容
2、将这些内容分别存入各文件中
3、进行分词,计算tf-idf
4、进行聚类
5、对文档进行分类,k=3
'''
下一篇: