文章目录
- 介绍
- 函数介绍
- 实例
作者:张双双
介绍
K-center聚类和K-means聚类类似,都是通过迭代类中心点直至收敛,不同的是K-center的中心点必须是一个真实的样本点,而K-means并不需要。
函数介绍
python">class Kmedoid:
def __init__(self, data, k):
self.data = data
self.k = k
def randCent(self): # 随机选取一个点
random_index = random.randint(0, self.data.shape[0]-1)
return random_index, self.data[random_index, :]
def distance(self, vecA, vecB): # 计算曼哈顿距离
return sum(abs(vecA - vecB))
def run(self):
init_centers = [] # 初始化中心的列表
init_indexs = [] # 被选中作为中心的点的下标
while len(init_centers) < self.k:
index, center = self.randCent()
if index not in init_indexs: # 保证选点不重复
init_centers.append(center)
init_indexs.append(index)
else:
continue
while True:
cluster_category = [] # 记录聚类结果
for i in range(self.data.shape[0]): # 遍历每一个点
minv = np.inf # 最小距离,初始为正无穷
cluster_index = 0 # 所属簇的下标
for index, center in enumerate(init_centers): # 遍历每个中心
# 选取离得最近的中心作为归属簇
dist = self.distance(center, self.data[i, :])
if dist < minv:
minv = dist
cluster_index = index
cluster_category.append(cluster_index)
# 重新计算中心点
new_indexs = [0 for i in range(len(init_centers))] # 更新被选中作为中心的点的下标
min_dists = [np.inf for i in range(len(init_centers))] # 中心点对应最小距离
for i in range(self.data.shape[0]):
min_dist = 0 # 求与当前簇其他点的距离之和
for j in range(self.data.shape[0]): # 遍历每一个点
if cluster_category[i] == cluster_category[j]: # 属于同一个簇才进行累加
min_dist += self.distance(self.data[i, :], self.data[j, :])
if min_dist < min_dists[cluster_category[i]]: # 保存数据到列表
min_dists[cluster_category[i]] = min_dist
new_indexs[cluster_category[i]] = i
init_centers = [] # 新的聚类中心
for index in new_indexs:
init_centers.append(self.data[index, :])
if new_indexs == init_indexs: # 如果新的中心与上次相同则结束循环
return cluster_category, init_centers
else:
init_indexs = new_indexs # 更新聚类中心下标
实例
python">import random
import numpy as np
from sklearn.datasets import make_blobs
from matplotlib import pyplot
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
ir = datasets.load_iris()
y = ir.data[:, :4] # #表示我们取特征空间中的4个维度
model = Kmedoid(data=y, k=3)
cluster_category, init_centers=model.run()
dat=np.concatenate([y,np.array(cluster_category).reshape(-1,1)],axis=1)
columns=ir.feature_names
columns.append('result')
X=pd.DataFrame(dat,columns=columns)
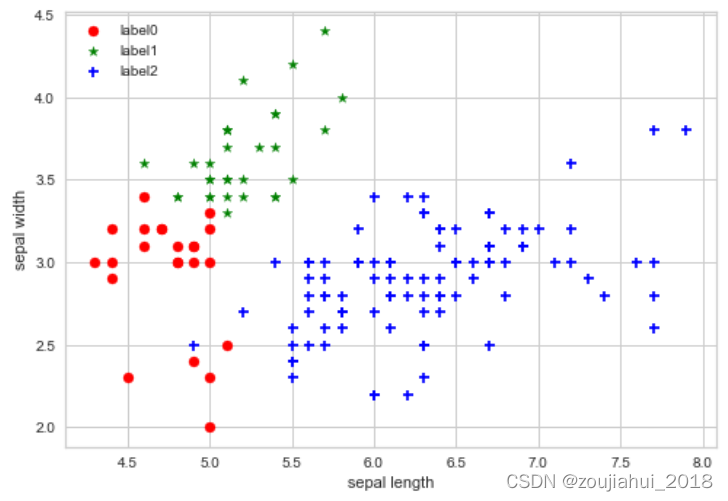
# 绘制结果
x0 = X[X['result'] == 0]
x1 = X[X['result'] == 1]
x2 = X[X['result'] == 2]
plt.scatter(x0['sepal length (cm)'], x0['sepal width (cm)'], c="red", marker='o', label='label0')
plt.scatter(x1['sepal length (cm)'], x1['sepal width (cm)'], c="green", marker='*', label='label1')
plt.scatter(x2['sepal length (cm)'], x2['sepal width (cm)'], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()