聚类">使用K-means进行像素聚类
python通过使用k-means对像素聚类以此进行图像分割">python通过使用K-means对像素聚类以此进行图像分割
聚类简介">K-means聚类简介:
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
因此,简单来说Kmeans是一种将输入数据划分为k个族的简单的聚类算法。
算法步骤(基本K-means):
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数 步骤
(1)适当选择k个类的初始中心;一般是采用随机或猜测的方式初始化类中心,(注:采用随机的方法实现简单,但是族的质量往往比较差,所以有好几种关于中心选取的解决方案,比如先使用层次聚类进行聚类,从层次聚类中提取K个簇,并用这些簇的质心作为初始质心。也有通过使类内总方差最小的方式,选择方差最小的类中心。这篇博客不是讨论算法本身,所以这里就不过多叙述,感兴趣的同学可以去查一些资料。)
(2)对任意一个样本,求其到k个中心的距离,将该样本归到距离最短的中心所在的类;(注:常用的距离度量方法包括:欧几里得距离和余弦相似度。两者都是评定个体间差异的大小的。欧几里得距离度量会受指标不同单位刻度的影响,所以一般需要先进行标准化。余弦相似度倾向给出更优解)
(3)对所有属于该类的数据点求平均,将平均值作为新的类中心;(取平均即向量各维取平均)
(4)重复步骤(2)(3)直到收敛。
该算法的最大优势在于简洁和快速,最重要的是容易实现与可并行。最大的缺陷在于要预先设定聚类数k,选择不当则会导致聚类效果很差。算法的关键在于初始中心的选择和距离公式。
算法复杂度:
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数
空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数
使用scipy中的K-means:
尽 管 K-means 算 法 很 容 易 实 现, 但 我 们 没 有 必 要 自 己 实 现 它。 SciPy 矢 量 量 化 包
scipy.cluster.vq 中有 K-means 的实现,下面是使用方法。
scipy K-means 的简单实例:
python"># -*- coding: utf-8 -*-
#导入scipy中K-means的相关工具
from scipy.cluster.vq import *
#randn是NumPy中的一个函数
from numpy import *
from pylab import *
#生成简单的二维数据:生成两类二维正态分布数据。
class1 = 1.5 * randn(100,2)
class2 = randn(100,2) + array([5,5])
features = vstack((class1,class2))
#用 k=2 对这些数据进行聚类:
centroids,variance = kmeans(features,2)
"""
由于 SciPy 中实现的 K-means 会计算若干次(默认为 20 次),并为我们选择方差最
小的结果,所以这里返回的方差并不是我们真正需要的。
"""
#用 SciPy 包中的矢量量化函数对每个数据点进行归类:通过得到的 code ,我们可以检查是否有归类错误
code,distance = vq(features,centroids)
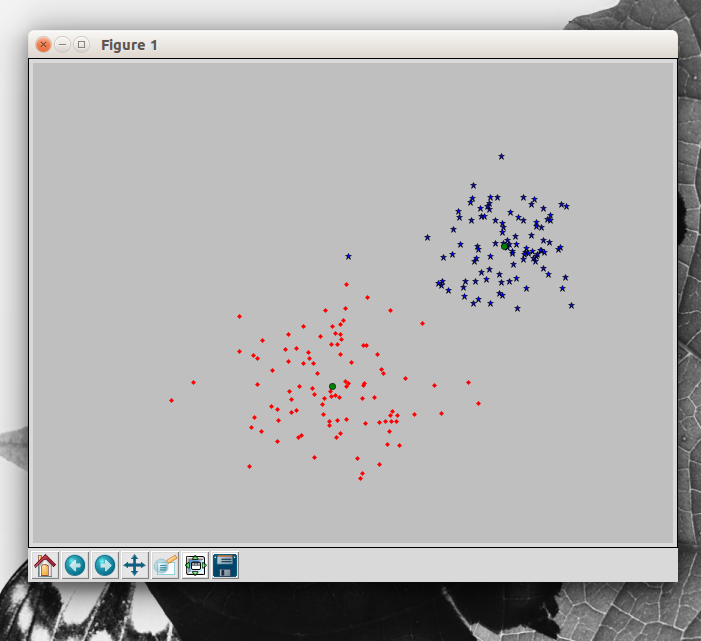
#可视化结果:画出这些数据点及最终的聚类中心:函数 where() 给出每个类的索引
figure()
ndx = where(code==0)[0]
plot(features[ndx,0],features[ndx,1],'*')
ndx = where(code==1)[0]
plot(features[ndx,0],features[ndx,1],'r.')
plot(centroids[:,0],centroids[:,1],'go')
axis('off')
show()
绘制结果:
聚类">K-means像素聚类
将图像区域或像素合并成有意义的部分称为图像分割。单纯在像素水平上应用 K-means可以用于一些简单图像的图像分割,但是对于复杂图像得出的结果往往是毫无意义的。对于复杂图像的图像分割往往需要更复杂的类模型而非平均像素色彩或空间一致性。
下面在 RGB 三通道的像素值上运用 K-means 进行聚类:
聚类"> K-means RGB三通道像素聚类
对像素进行聚类首先要降分辨率处理,否则像素的值太多,运行效率会相当差,噪点也一定很多,一般情况下传统的方式会以steps×steps个方格为单位对每个方格中的像素值进行均化以达到降低分辨率的目的,但是如果图像不是正方形或者step值不合适的话,结果就会出现严重的变形,因此我将原本step×step的方式改为了stepX*stepY并且根据输入的step自动计算合理step值,成功解决了这个问题,以下代码中clusterpixels_square为传统的像素聚类,clusterpixels_rectangular是我改进之后的聚类方法,希望对大家有所帮助:
python"># -*- coding: utf-8 -*-
"""
对像素进行聚类。
在像素级水平进行聚类可以用在一些很简单的图像
载入图像,并将其下采样到一个较低的分辨率,然后对这些区域用k-means进行聚类
K-means 的输入是一个有 stepsX × stepsY 行的数组,数组的每一行有 3 列,各列分别为区域块 R、G、B 三个通道的像素平均值。
为可视化最后的结果 , 我们用 SciPy 的imresize() 函数在原图像坐标中显示这幅图像。
参数 interp 指定插值方法;我们在这里采用最近邻插值法,以便在类间进行变换时不需要引入新的像素值。
"""
from scipy.cluster.vq import *
from scipy.misc import imresize
from pylab import *
from PIL import Image
#steps*steps像素聚类
def clusterpixels_square(infile, k, steps):
im = array(Image.open(infile))
#im.shape[0] 高 im.shape[1] 宽
dx = im.shape[0] / steps
dy = im.shape[1] / steps
# 计算每个区域的颜色特征
features = []
for x in range(steps):
for y in range(steps):
R = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 0])
G = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 1])
B = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 2])
features.append([R, G, B])
features = array(features, 'f') # 变为数组
# 聚类, k是聚类数目
centroids, variance = kmeans(features, k)
code, distance = vq(features, centroids)
# 用聚类标记创建图像
codeim = code.reshape(steps, steps)
codeim = imresize(codeim, im.shape[:2], 'nearest')
return codeim
#stepsX*stepsY像素聚类
def clusterpixels_rectangular(infile, k, stepsX):
im = array(Image.open(infile))
stepsY = stepsX * im.shape[1] / im.shape[0]
#im.shape[0] 高 im.shape[1] 宽
dx = im.shape[0] / stepsX
dy = im.shape[1] / stepsY
# 计算每个区域的颜色特征
features = []
for x in range(stepsX):
for y in range(stepsY):
R = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 0])
G = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 1])
B = mean(im[x * dx:(x + 1) * dx, y * dy:(y + 1) * dy, 2])
features.append([R, G, B])
features = array(features, 'f') # 变为数组
# 聚类, k是聚类数目
centroids, variance = kmeans(features, k)
code, distance = vq(features, centroids)
# 用聚类标记创建图像
codeim = code.reshape(stepsX, stepsY)
codeim = imresize(codeim, im.shape[:2], 'nearest')
return codeim
#计算最优steps 为保证速度以及减少噪点 最大值为maxsteps 其值为最接近且小于maxsteps 的x边长的约数
def getfirststeps(img,maxsteps):
msteps = img.shape[0]
n = 2
while(msteps>maxsteps):
msteps = img.shape[0]/n
n = n + 1
return msteps
#Test
#图像文件 路径
infile = './data/10.jpg'
im = array(Image.open(infile))
#参数
m_k = 10
m_maxsteps = 128
#显示原图empire.jpg
figure()
subplot(131)
title('source')
imshow(im)
# 用改良矩形块对图片的像素进行聚类
codeim= clusterpixels_rectangular(infile, m_k,getfirststeps(im,m_maxsteps))
subplot(132)
title('New steps = '+str(getfirststeps(im,m_maxsteps))+' K = '+str(m_k));
imshow(codeim)
#方形块对图片的像素进行聚类
codeim= clusterpixels_square(infile, 15, 200)
subplot(133)
title('Old steps = 200 K = '+str(m_k));
imshow(codeim)
show()
聚类结果">聚类结果:
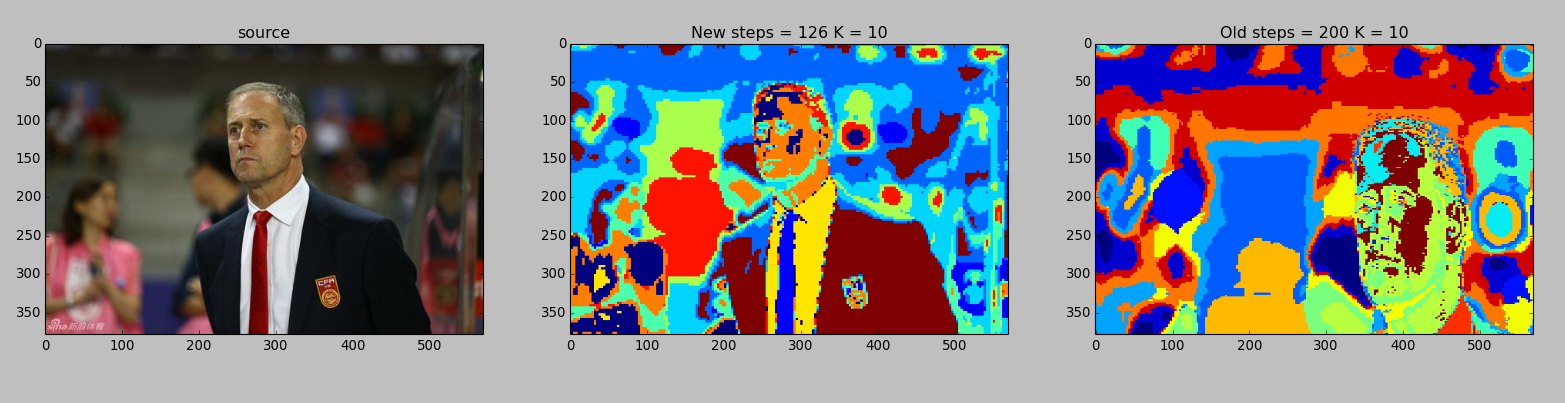
我们看到,使用xy方向步数相等的方式出现了严重的图像变形缺失,使用我改良的方法则解决了这个问题
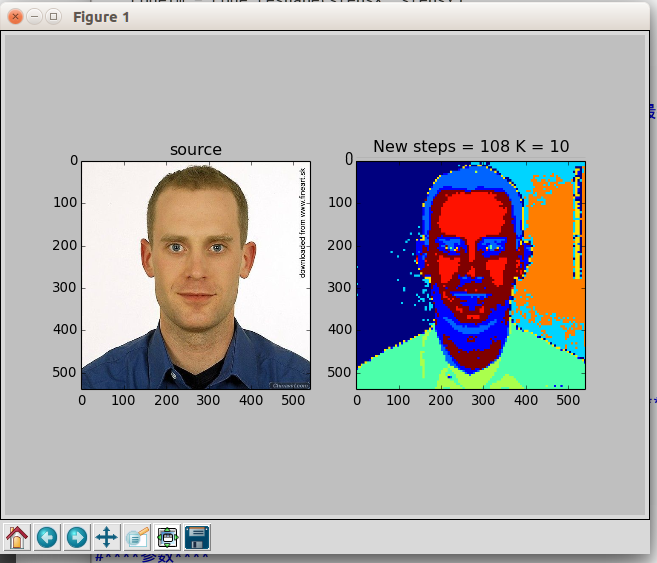
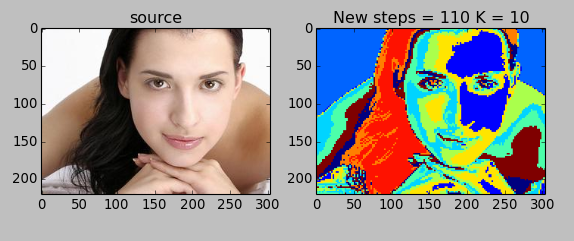
聚类效果方面,对于人物这种简单图片效果还是不错的。
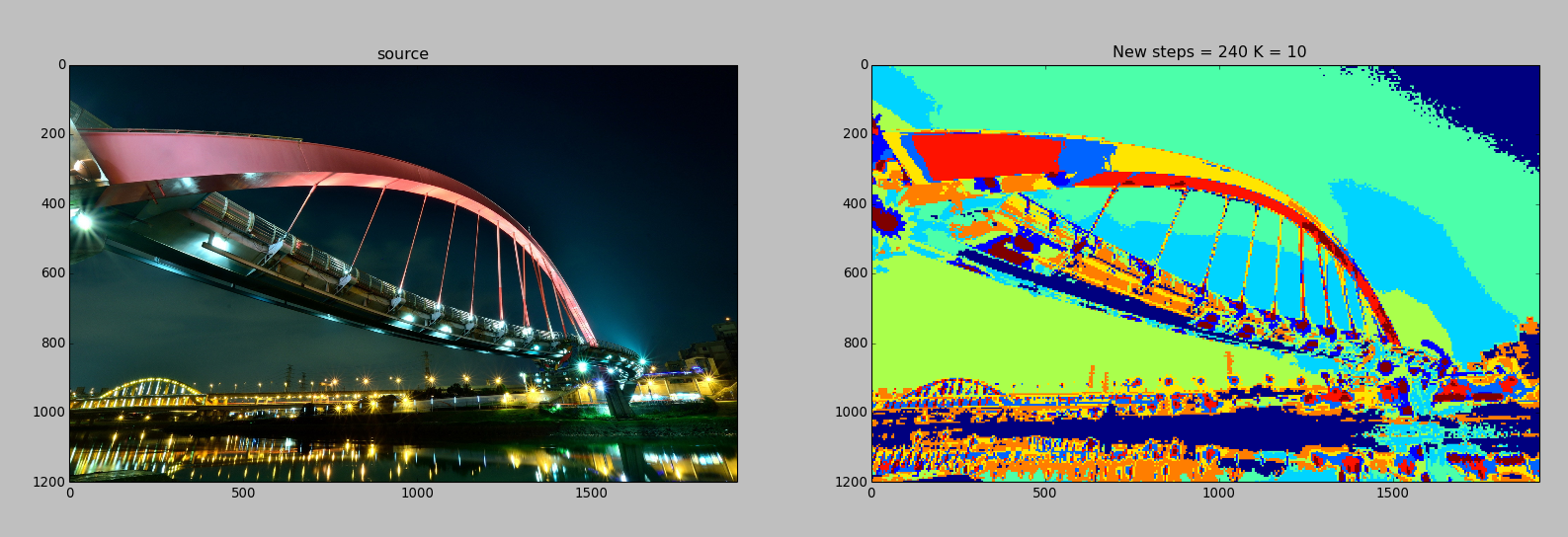

但是对于风景这种复杂图片效果就比较一般了,可能采取分水岭这种专门的分割算法能达到一个比较好的效果。