需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、聚类任务
设样本集S={x_1,x_2,…,x_m}包含m个未标记样本,样本x_i=(x_i^(1),x_i^(2),…,x_i^(n))是一个n维特征向量。
聚类在分簇过程的任务是建立簇结构,即要将S划分为k(有的聚类算法将k作为需事先指定的超参数,有的聚类算法可自动确定k的值)个不相交的簇C_1,C_2,…,C_k,C_l∩C_l^′=∅且⋃_l=1^k▒C_l=S,其中1≤l,l^′≤k,l≠l^′。记簇C_l的标签为y_l,簇标签共有k个,且互不相同。
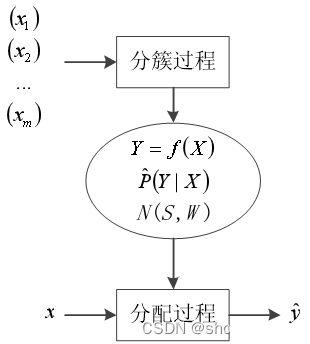
记测试样本为x=(x^(1),x^(2),…,x^(n))。聚类在分配阶段的任务是根据簇结构将测试样本x分配到一个合适的簇(簇标签为y ̂)中
可以从决策函数、概率和神经网络三类模型来描述分簇过程和分配过程。
在分簇过程,决策函数聚类模型要建立起合适的从样本到簇标签的映射函数Y=f(X),X是定义域,它是所有样本特征向量的集合,Y是值域,它是所有簇标签的集合(在聚类算法里,簇标签没有实际含义,一般只是算法自动产生的簇的编号);
概率聚类模型要建立起正确的条件概率P ̂(Y|X);
神经网络聚类模型要利用一定的网络结构N,生成能够反映分簇结构的网络参数W,即得到合适的网络模型N(S,W)。
在分配过程,决策函数聚类模型依据决策函数Y=f(X)给予测试样本x一个簇标签y ̂;概率聚类模型依据条件概率P ̂(Y|X)计算在给定x时取每一个y ̂的条件概率值,取最大值对应的y ̂作为输出;神经网络聚类模型将x馈入已经训练好的网络N(S,W),从输出得到标签y ̂。
决策函数聚类模型有kmeans、DBSCAN、OPTICS、Mean Shift等。
用于聚类的神经网络有自组织特征映射(Self-Organizing Feature Map,SOM)网络。
聚类不仅可以是单独的任务,也可以对数据进行预处理,作为其它机器学习任务的前驱任务。
二、聚类算法评价指标
1:内部结构
内部指标关注分簇后的内部结构,目标是衡量簇内结构是否紧密、簇间距离是否拉开等。
设样本集为S={x_1,x_2,…,x_m}。若某聚类算法给出的分簇为C={C_1,C_2,…,C_k},定义:
1.样本x_m与同簇C_i其它样本的平均距离:
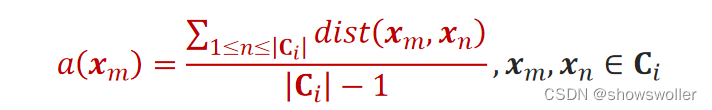
2.样本x_m与不同簇C_j内样本的平均距离:
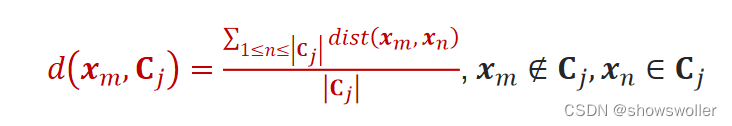
3.样本x_m与簇的最小平均距离:
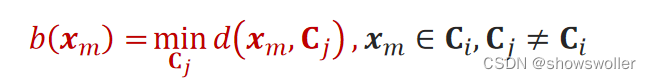
4. 簇内样本平均距离:
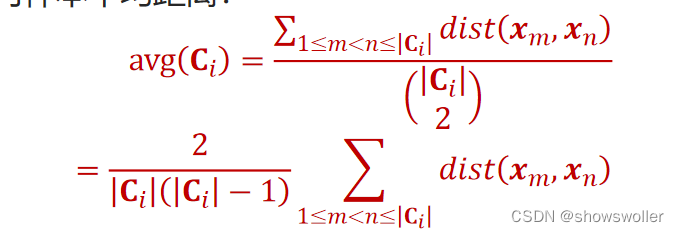
5. 簇中心距离:

2:轮廓系数(Silhouette Coefficient SC)
单一样本x_m的轮廓系数为:
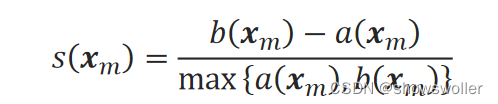
一般使用的轮廓系数是对所有样本的轮廓系数取均值。SC值高表示簇内密集,簇间疏散。
该指标在slkearn.metrics包中有实现,函数原型为:silhouette_score()。
3:DB指数(Davies-Bouldin Index DBI)
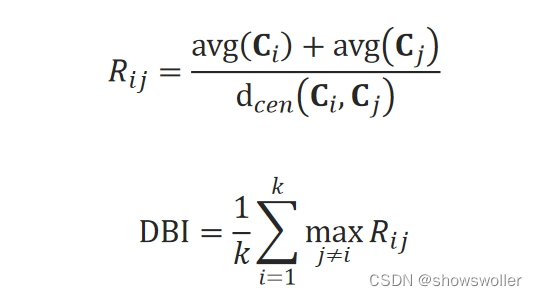
R_ij的分子是两个簇内样本平均距离之和,分母是两簇的中心距离,因此该指数越小说明簇内样本点更紧密、簇就间隔的越远。
该指标在slkearn.metrics包中也有实现,函数原型为:davies_bouldin_score()。
4:凸集与非凸集
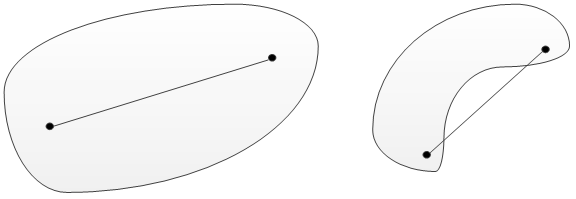
在欧式空间中,凸集在直观上就是一个向四周凸起的图形。在一维空间中,凸集是一个点,或者一条连续的非曲线(线段、射线和直线);在二维空间中,就是上凸的图形,如锥形扇面、圆、椭圆、凸多边形等;在三维空间中,凸集可以是一个实心的球体等。总之,凸集就是由向周边凸起的点构成的集合。
5:凸簇与非凸簇
簇的成员的集合为凸集的簇,称为凸簇,否则,称为非凸簇

同簇内的样本间的距离很大,也就是说,簇内平均不相似度a(x_m)可能比b(x_m)还大,所以,SC甚至可能取负值。
衡量聚类效果的有两个方面的因素,分别是簇内密集程度和簇间隔程度。因为非凸簇的分布特点,簇内密集程度不再适合用簇内所有样本间的距离来衡量,簇间隔程度也不再适合用簇中心的距离来衡量。
6:ZQ系数
定义众距离Z来衡量簇内密集程度。记MinPts_distance(x_m)为样本点x_m到它的第MinPts近邻居样本点的距离,则簇C_i的众距离Z_i为:
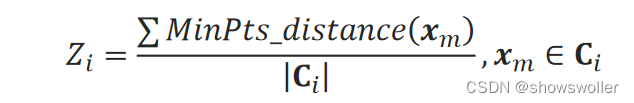
MinPts可以根据样本密集程度取1、2、…等值。
定义群距离Q来衡量簇的间隔程度。
1)两个簇的群距离Q是他们的样本点之间的距离的最小值:
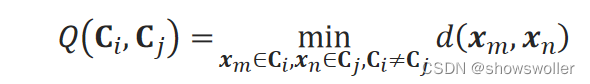
2)也可以用点到簇的距离来定义群距离,记样本x_m到不同簇C_j的距离为:
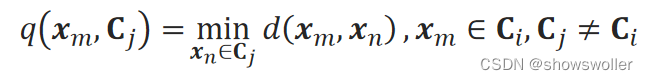
即样本点到不同簇内点的最小值。簇C_i到C_j的群距离Q(C_i,C_j)为他们的均值:
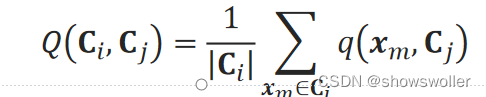
用所有簇的众距离的均值除以所有簇间群距离的均值的结果作为评价聚类效果的指标,称为ZQ系数:
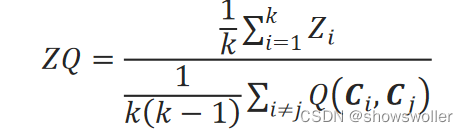
ZQ系数小表示簇内密集、簇间疏散
三、聚类算法内部评价指标实战
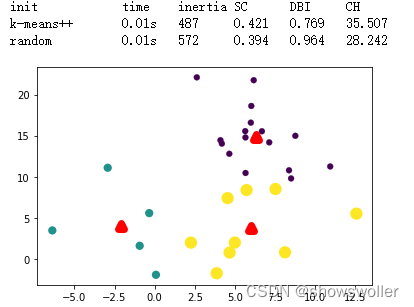
SC DBI CH评价指标示例 效果如下图
代码如下
import numpy as np
from time import time
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.cluster import KMeans
#np.random.seed(719) # 指定随机数种子,以确保每次运行可重复观察
samples = np.loadtxt("kmeansSamples.txt") # 加载数据集
print(54 * '_')
print('init\t\ttime\tinertia\tSC\tDBI\tCH') # 打印表头
n_init = 1 # 指定kmeans算法重复运行次数
estimator = KMeans(init='k-means++', n_clusters=3, n_init=n_init) # k-means++方式指定初始簇中心
t0 = time() # 开始计时
estimator.fit(samples)
print('%-9s\t%.2fs\t%i\t%.3f\t%.3f\t%.3f'
% ('k-means++', (time() - t0), estimator.inertia_,
metrics.silhouette_score(samples, estimator.labels_, metric='euclidean'),
estimator.fit(samples)
print('%-9s\t%.2fs\t%i\t%.3f\t%.3f\t%.3f'
% ('random', (time() - t0), estimator.inertia_,
metrics.silhouette_score(samples, estimator.labels_, metric='euclidean'),
metrics.davies_bouldin_score(samples, estimator.labels_),
metrics.calinski_harabasz_score(samples, estimator.labels_)))
plt.scatter(samples[:,0],samples[:,1],c=estimator.labels_,linewidths=np.power(estimator.labels_+0.5, 2)) # 用不同大小的点来表示不同簇的点
plt.scatter(estimator.cluster_centers_[:,0],estimator.cluster_centers_[:,1],c='r',marker='^',linewidths=7) # 打印簇中心
plt.show()ZQ评价指标示例
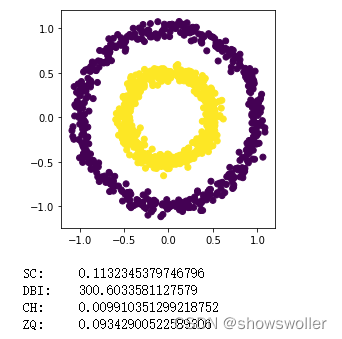
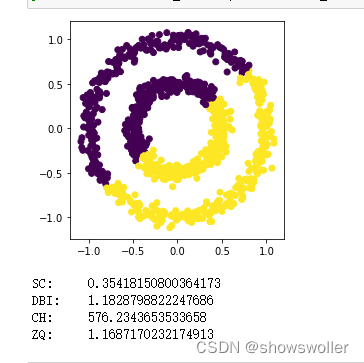
部分代码如下
from zqscore import ZQ_score
from sklearn.datasets import make_circles
noisy_circles = make_circles(n_samples=1000, factor=.5, noise=.05, random_state=15)
X = noisy_circles[0]
plt.axes(aspect='equal')
plt.scatter(X[:, 0], X[:, 1], marker='o', c=noisy_circles[1])
plt.show()
print("SC:\t"+str(metrics.silhouette_score(X, noisy_circles[1], metric='euclidean')))
print("DBI:\t"+str(metrics.davies_bouldin_score(X, noisy_circles[1])))
print("CH:\t"+str(metrics.calinski_harabasz_score(X, noisy_circles[1])))
print("ZQ:\t"+str(ZQ_score(X, noisy_circles[1])))创作不易 觉得有帮助请点赞关注收藏~~~