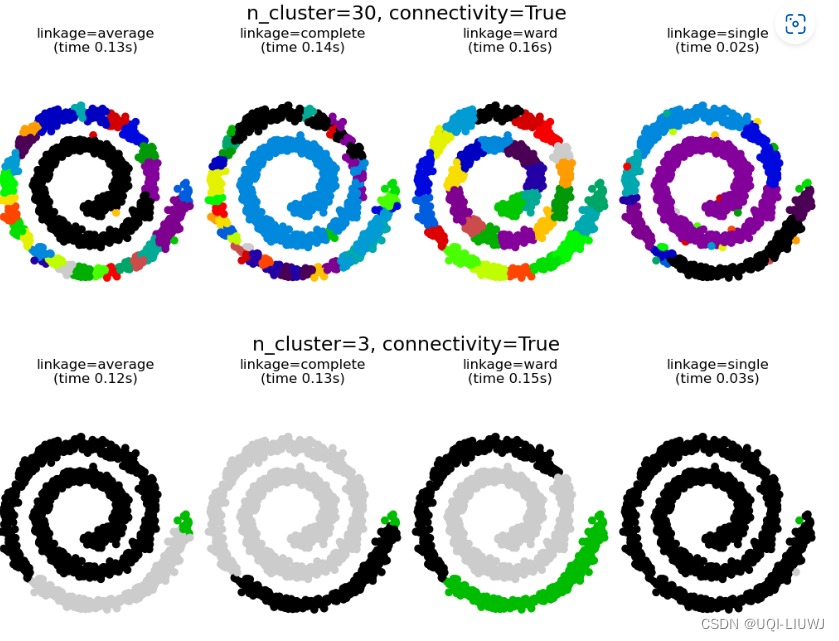
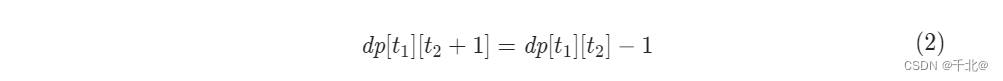- 这个blog显示了使用连接图来捕获数据中的局部结构。在有局部结构的情况下凝聚分层聚类的结果
1 使用数据结构后,凝聚分层聚类的特点
- 使用数据结构后,会有以下的特点:
- 首先,没有连接矩阵的聚类比有连接矩阵的聚类要快。
- 其次,当使用连接矩阵时,single linkage,average linkage, complete linkage的结果是不均衡的,往往会创建一些非常大的簇。
- 在没有连接矩阵时:
- single linkage仅考虑簇之间的最短距离,这可能导致两个不相近的簇因为极端点的相近,而被合并在一起
- average linkage, complete linkage通过在合并时考虑两个簇之间的所有距离来对抗这种不合理的合并行为。

- 使用了连接矩阵后:
- 连接矩阵打破了average linkage和complete linkage的这种对抗机制,使它们类似于更脆弱的单一链接。
- 尤其是对于非常稀疏的图(减少 kneighbors_graph 中的邻居数量,这种效果更为明显。
- 图中的邻居数量非常少,会强加一个接近于single linkage的几何形状.
- ——>使得average linkage和complete linkage退化成了single linkage
- 尤其是对于非常稀疏的图(减少 kneighbors_graph 中的邻居数量,这种效果更为明显。
- 连接矩阵打破了average linkage和complete linkage的这种对抗机制,使它们类似于更脆弱的单一链接。
- 在没有连接矩阵时:
2 举例
2.1 数据集
python">import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import kneighbors_graph
# Generate sample data
n_samples = 1500
np.random.seed(0)
t = 1.5 * np.pi * (1 + 3 * np.random.rand(1, n_samples))
x = t * np.cos(t)
y = t * np.sin(t)
x.shape,y.shape
#((1, 1500), (1, 1500))
X = np.concatenate((x, y))
X.shape
#(2,1500)
X += 0.7 * np.random.randn(2, n_samples)
#加上一点噪声
X = X.T
plt.scatter(X[:,0],X[:,1])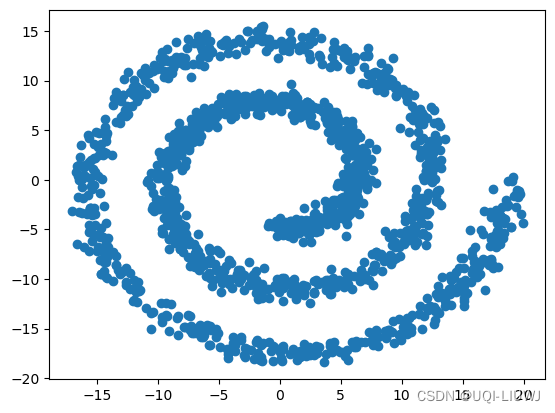
2.2 创建联通图
python">knn_graph = kneighbors_graph(X, 30, include_self=False)
#每个点只和30个邻居连接2.3 凝聚型分层聚类
2.3.1 20个cluster,有无数据结构的对比
python">plt.figure(figsize=(10, 4))
for connectivity in (None, knn_graph):
plt.figure(figsize=(10, 4))
for index, linkage in enumerate(("average", "complete", "ward", "single")):
plt.subplot(1, 4, index + 1)
model = AgglomerativeClustering(
linkage=linkage,
connectivity=connectivity,
n_clusters=30
)
t0 = time.time()
model.fit(X)
elapsed_time = time.time() - t0
plt.scatter(X[:, 0], X[:, 1], c=model.labels_)
plt.title(
"linkage=%s\n(time %.2fs)" % (linkage, elapsed_time),
fontdict=dict(verticalalignment="top"),
)
plt.axis("equal")
#x,y坐标等长
plt.axis("off")
#不显示x,y坐标
plt.subplots_adjust(bottom=0, top=0.83, wspace=0, left=0, right=1)
plt.suptitle(
"n_cluster=%i, connectivity=%r"
% (n_clusters, connectivity is not None),
size=17,
)
有数据结构后,average linkage和complete linkage效果都变差了
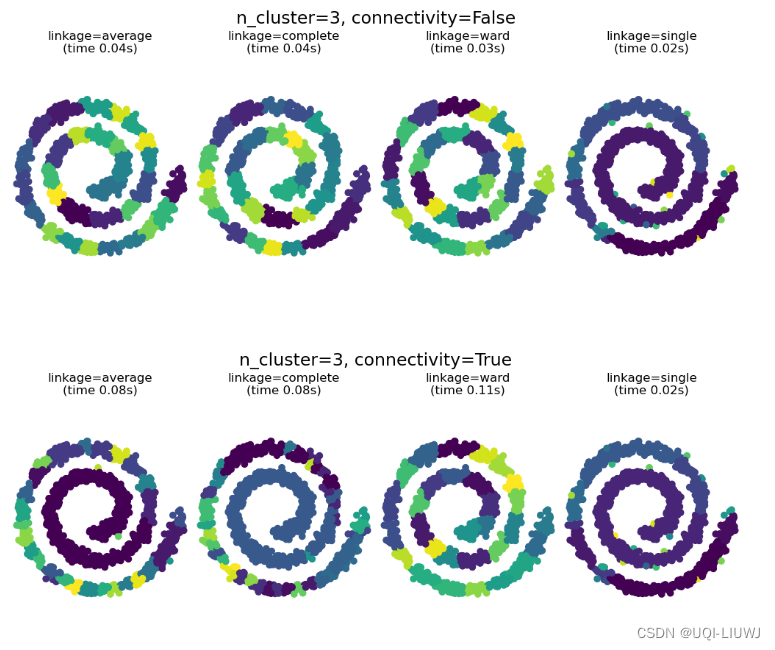
2.3.2 3个cluster

参考内容:Agglomerative clustering with and without structure — scikit-learn 1.2.2 documentation