问题描述:
- 数据放在数据文件中(不得放在程序中),第一行是数据的个数,以后各行是各个点的x,y,z坐标。
- 读取文本文件数据,并用K-means方法输出聚类中心
- k-means 算法接受输入量k;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
算法过程
首先从n个数据对象任意选择k个对象作为初始聚类中心,而对于所剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类。然后,再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值),不断重复这一过程直到标准测度函数开始收敛为止。采用均方差作为标准测度函数。
聚类标准旨在使所获得的k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
Step 1.读取数据组,从N个数据对象任意选择k个对象作为初始聚类中心;
Step 2.循环Step 3到Step 4直到每个聚类不再发生变化为止;
Step 3.根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分;
Step 4.重新计算每个(有变化)聚类的均值(中心对象)。
代码
数据可以选择由程序生成,也可以自行导入,第一行是数据的个数,以后各行是各个点的x,y,z坐标。
import numpy as np
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
import random
class KMeans:
def __init__(self, data, k=3):
self.data = data
self.k = k
@staticmethod
def __euclidean_distance(a, b):
c = a - b
d = np.power(a - b, 2)
return np.sqrt(np.sum(np.power(a - b, 2), axis=1))
def get_labels(self):
data = self.data
idx = random.sample(list(range(len(self.data))), self.k)
clusters = self.data[idx]
labels = np.zeros((len(self.data),))
while True:
cnt = 0
for i, d in enumerate(self.data):
_distance = self.__euclidean_distance(d, clusters)
min_idx = np.argmin(_distance)
if labels[i] != min_idx:
cnt += 1
labels[i] = min_idx
if cnt == 0:
break
for label in range(self.k):
points = self.data[labels == label]
centroid = np.mean(points, axis=0)
clusters[label] = centroid
return labels
def make_blobs_txt(centers=3, n_features=3, n_samples=100, savepath="blobs.txt"):
data, label = make_blobs(n_features=n_features, n_samples=n_samples, centers=centers, random_state=7)
f = open(savepath, 'w')
f.write(str(centers))
np.savetxt(savepath, data, fmt='%f', delimiter=',')
def read_txt(path="data.txt"):
f = open(path, 'r')
data = []
for line in f:
if len(line) == 2:
continue
data.append([float(line.split(',')[0]), float(line.split(',')[1]), float(line.split(',')[2])])
data = np.array(data)
return data
def visulization(dataset, labels):
ax = plt.figure().add_subplot(projection='3d')
# for i in range(len(labels)):
# ax.scatter(dataset[i][0], dataset[i][1], dataset[i][2], c=labels[i], cmap="bwr_r")
ax.scatter(dataset[:, 0], dataset[:, 1], dataset[:, 2], c=labels)
plt.show()
if __name__ == "__main__":
make_blobs_txt(savepath="blobs.txt", centers=3, n_features=3, n_samples=100)
dataset = read_txt(path="blobs.txt")
K = int(input("输入k:"))
kmeans = KMeans(dataset, k=K)
labels = kmeans.get_labels()
print(labels)
visulization(dataset, labels)
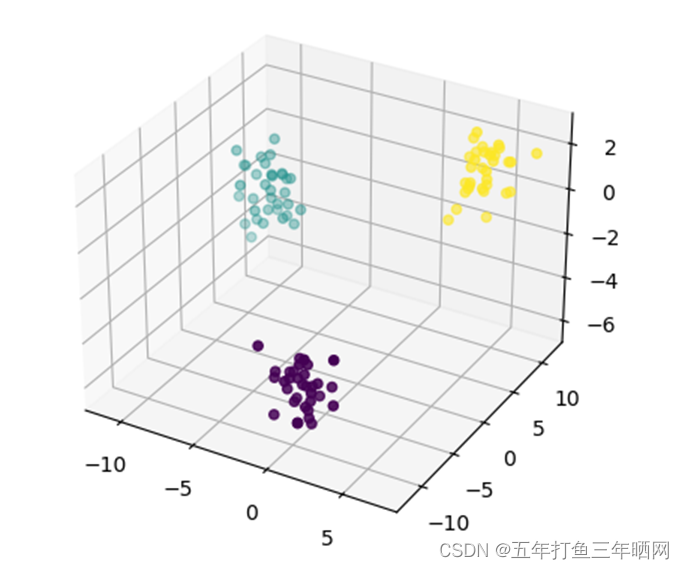
运行示例


![[前端必刷75题]41.使用arguments](/images/no-images.jpg)

![[Vue框架学习笔记]用户列表的搭建](https://img-blog.csdnimg.cn/b9b25d80a07a40f8b77f7d57f7459648.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA6ZKn5qGQ,size_20,color_FFFFFF,t_70,g_se,x_16)