https://colab.research.google.com/drive/1F-1Ej7T2xnUKXSmDPjjOChNbBTvQlpnM?usp=sharing
考试
https://colab.research.google.com/drive/1hSRxzFL9cx7PYrHYZeEnT3jRSn8LmQcx?usp=sharing
第一题要求
- 聚类选定的新闻数据。此时,请考虑以下事项。(2分:每项0.5分)
- 创建并应用您自己的停用词处理列表。(0.5 分)
- 执行内聚聚类时,请使用 Ward 技术以外的技术。(0.5 分)
- 使用轮廓分数来确定理想的簇数。(0.5 分)
- 使用散点图可视化聚类结果。(PCA 或 TSNE)(0.5 分)
你今天会学到什么
1.文档聚类
2.主题建模
2.主题建模
主题建模是使用表示文档中潜在主题的词。
它是一种自然语言处理技术,可以自动选择和呈现文档中的文档。
给定大量文档,很难找出这些文档涵盖的主题。
这是一个有用的技能。
但是,需要一个人在分析时判断目标文档分为多少个主题。
另外,主题模型呈现的主题并没有作为完美主题提供,
由于它是从文档中提取的关键词,因此主题的解释留给了人类。
主题建模基于长文档而不是短文档(句子),例如推文或评论。
他们往往会给出有意义的结果。
主题模型也对应词袋模型,因为它不考虑词的顺序。
在刚刚学习的聚类中,一个文档被归为一个簇。
在主题建模中,一个文档可以有多个主题。
在这种实践中,各种主题建模技术之一
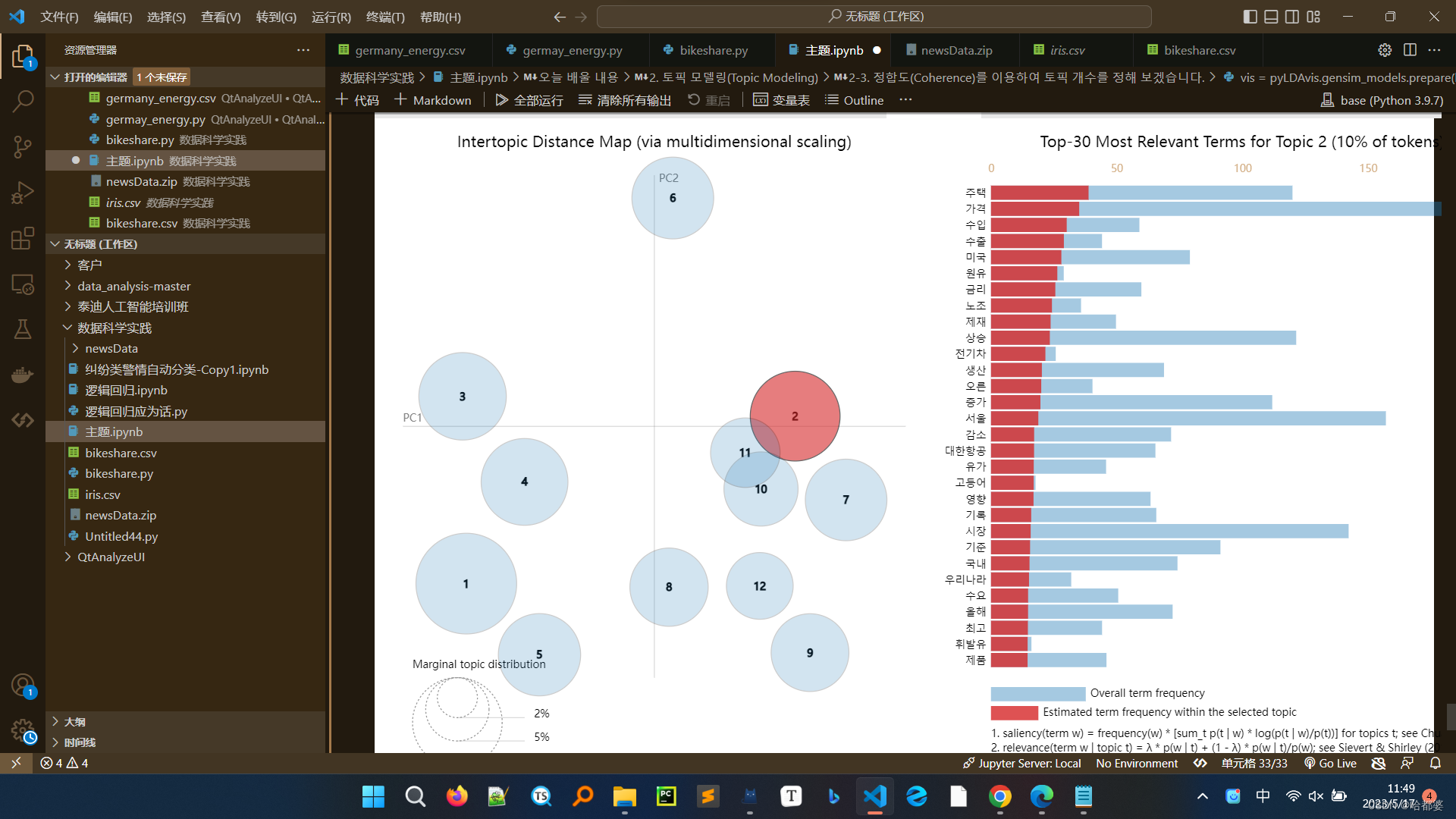
让我们看看一种称为Latent Dirichlet Allocation (LDA)的技术。
为此,使用了一个名为gensim的主题建模 Python 库,
为了可视化结果,我们将使用一个名为pyLDAvis的库。
- gensim:用于构建主题模型的 Python 库
models.ldamodel – Latent Dirichlet Allocation — gensim
- pyLDAvis:用于可视化主题模型结果的 Python 库
Welcome to pyLDAvis’s documentation! — pyLDAvis 2.1.2 documentation
在主题建模实践中,对200篇经济文章进行韩文预处理后,
让我们创建一个主题模型并可视化结果是什么。
您还将学习如何确定主题的数量。
代码解析
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore", category=DeprecationWarning)
import glob
news_file = []
for file in glob.glob('/content/econ_news/*NewsData.txt'):
# print(file)
news_file.append(file)
news_file.sort()
news_file
from konlpy.tag import Okt
okt = Okt()
stopwords = ['가가', '가지', '각각', '거나', '게다가', '경우', '관련', '그동안', '기자', '다른',
'다만', '다시', '다음', '당시', '대상', '대신', '대해', '더욱', '따라서', '때문',
'또한', '라며', '로부터', '로서', '만약', '만큼', '면서', '모두', '모든', '반면',
'별로', '사이', '생각', '앞서', '앵커', '얘기', '여기', '여부', '우리', '위해',
'이란', '이번', '이후', '일부', '작년', '정도', '지금', '지난', '지난달', '지난해',
'최근', '통해', '현재']
news_raw_texts = [] # 뉴스 기시 본문을 담는 리스트
news_nouns = [] # 명사 리스트 획득
news_data = [] # tfidf.vectorizer에 입력할 데이터
for file in news_file:
with open(file, 'r') as f:
news_text = f.read()
news_raw_texts.append(news_text)
noun_list = okt.nouns(news_text)
cleaned_nouns = [n for n in noun_list if (len(n) > 1) and (n not in stopwords)] # 한 글자로 된 명사를 제거 & stopwords 제거
news_data.append(' '.join(cleaned_nouns))
news_nouns.append(cleaned_nouns)
len(news_nouns)
import glob
news_file = [] # 存储经济新闻文本文件名的列表
for file in glob.glob('/content/econ_news/*NewsData.txt'): # 获取所有以 "NewsData.txt"结尾的文件的文件名
news_file.append(file)
#---
from konlpy.tag import Okt
okt = Okt() # 初始化Konlpy的Okt分词器
# 设置需要去除的停用词
stopwords = ['가가', '가지', '각각', '거나', '게다가', '경우', '관련', '그동안', '기자', '다른',
'다만', '다시', '다음', '당시', '대상', '대신', '대해', '더욱', '따라서', '때문',
'또한', '라며', '로부터', '로서', '만약', '만큼', '면서', '모두', '모든', '반면',
'별로', '사이', '생각', '앞서', '앵커', '얘기', '여기', '여부', '우리', '위해',
'이란', '이번', '이후', '일부', '작년', '정도', '지금', '지난', '지난달', '지난해',
'최근', '통해', '현재']
news_raw_texts = [] # 存储新闻文本的列表
news_nouns = [] # 存储新闻文本中提取出的名词的列表
news_data = [] # 存储将新闻文本中提取出的名词转化为字符串的列表,以便传递给tfidf.vectorizer
# 遍历每一个新闻文件
for file in news_file:
with open(file, 'r') as f:
news_text = f.read() # 读取新闻文本
news_raw_texts.append(news_text) # 将新闻文本存入news_raw_texts列表中
noun_list = okt.nouns(news_text) # 使用Okt分词器对新闻文本进行分词,并只保留名词
cleaned_nouns = [n for n in noun_list if (len(n) > 1) and (n not in stopwords)] # 去除长度为1的名词和停用词
news_data.append(' '.join(cleaned_nouns)) # 将处理后的名词列表转化为以空格分隔的字符串,以便传递给tfidf.vectorizer
news_nouns.append(cleaned_nouns) # 将处理后的名词列表存入news_nouns列表中
#---
corpora语料库
from gensim import corpora
dictionary = corpora.Dictionary(news_nouns) # 使用gensim库的corpora模块创建一个词典
corpus = [dictionary.doc2bow(text) for text in news_nouns] #
这段代码的作用是使用gensim库的corpora模块将文档中的名词列表news_nouns转换为字典dictionary,然后使用该字典 将语料库corpus创建出来。
在这里,corpus是一个包含每个文档的 单词索引和词频信息的列表的列表。例如,corpus[1]是一个包含第二篇新闻单词索引和词频信息的列表。
因此,print(corpus[1])的代码输出了第二篇新闻的索引和词频信息。在Python中,索引从0开始,因此第一篇文档的索引是0。
PCA进行降维
以下是使用散点图可视化聚类结果的示例代码,其中使用了PCA进行降维:
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 假设有聚类结果的数据集或特征集
cluster_data = ...
# 使用PCA进行降维
pca = PCA(n_components=2)
reduced_features = pca.fit_transform(cluster_data)
# 假设每个数据点对应的聚类标签为labels
labels = ...
# 绘制散点图
plt.scatter(reduced_features[:, 0], reduced_features[:, 1], c=labels)
plt.xlabel("Component 1")
plt.ylabel("Component 2")
plt.title("Clustering Results")
plt.show()
在这段代码中,首先导入matplotlib.pyplot和sklearn.decomposition.PCA。然后,假设有一个聚类结果的数据集或特征集存储在cluster_data中。接下来,使用PCA进行降维,将数据集降低到2维。通过创建PCA对象并调用fit_transform方法,将cluster_data转换为降维后的特征矩阵reduced_features。
假设每个数据点对应的聚类标签存储在labels中。最后,使用plt.scatter绘制散点图,将降维后的特征矩阵的第一维和第二维作为横纵坐标,通过指定c参数为labels,将不同聚类标签的数据点着色。
请注意,在使用此代码之前,需要根据实际情况提供合适的数据集或特征集,并根据需要选择PCA或TSNE进行降维。
可用于分析舆情主题,自然语言处理,非常高级