目录
聚类分析是什么
一、 定义和数据类型
聚类应用
聚类分析方法的性能指标
聚类分析中常用数据结构有数据矩阵和相异度矩阵
聚类分析方法分类
二、K-means聚类算法
K-Means算法流程:
K-means聚类算法的特点
三、k-medoids算法
基本思想
K-medoids算法特点
四、送书活动
五、抽奖规则
聚类分析是什么
聚类分析是一种寻找数据之间内在结构的技术,将数据对象的集合分组为由类似的对象组成的多个类的分析过程。聚类把全体数据实例组织成一些相似组,而这些相似组被称作簇。处于相同簇中的数据实例彼此相同,处于不同簇中的实例彼此不同。聚类技术通常又被称为无监督学习,与监督学习不同的是,在簇中那些表示数据类别的分类或者分组信息是没有的。
一、 定义和数据类型
聚类应用
- 市场营销: 帮助营销人员帮他们发现顾客中独特的群组,然后利用他们的知识发展目标营销项目
- 土地利用: 在土地观测数据库中发现相似的区域
- 保险: 识别平均索赔额度较高的机动车辆保险客户群组
- 城市规划: 通过房屋的类型、价值、地理位置识别相近的住房
- 地震研究: 沿着大陆断层聚类地震的震中
聚类分析方法的性能指标
- 可扩展性
- 自适应性
- 鲁棒性
- 可解释性
聚类分析中常用数据结构有数据矩阵和相异度矩阵


聚类分析方法分类
基于划分、基于分层、基于密度、基于网络、基于模型
二、K-means聚类算法
划分聚类方法对数据集进行聚类时包含三个要点
选定某种距离作为数据样本间的相似性度量
选择评价聚类性能的准则函数
选择某个初始分类,之后用迭代的方法得到聚类结果,使得评价聚类的准则函数取得最优值
标准测试函数:
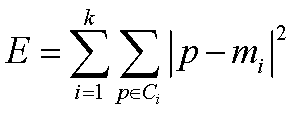
均值:
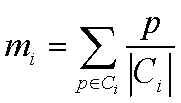
K-Means算法流程:
输入:包含n个对象的数据集聚类个数k,最小误差e
输出:满足方差最小标准的k个聚类
①从n个数据对象中随机选出k个对象作为初始聚类的中心
②将每个类簇中的平均值作为度量基准,重新分配数据库中的
数据对象
③计算每个类簇的平均值,更新平均值
④循环(2)(3),直到每个类簇不在发生变化或者平均误差小于e
K-means聚类算法的特点
优点
简单、快速
算法尝试找出使平方误差函数值最小的k个划分据集
对处理大数据集,该算法是相对可伸缩的和高效率的
缺点
不适合于发现非凸面形状的簇,或者大小差别很大的簇
要求用户必须事先给出要生成的簇的数目K
对于“噪声”和孤立点数据敏感
对初值敏感
三、k-medoids算法
基本思想
k-medoids算法是一种聚类算法,与k-means算法相似,但它选择的中心点是簇中实际的数据点,而不是像k-means那样选择簇中心点的均值。
其基本思想是,给定一个数据集和聚类数k,随机选择k个点作为初始中心点,然后迭代以下两个步骤直到收敛:
1. 对于每个数据点,计算其与各中心点的距离,并将其划分到距离最近的簇中。
2. 对于每个簇,选择一个代表点(即中心点)来替换原来的中心点,使得代表点到簇中其他点的距离之和最小。
这个过程是一种优化过程,每次迭代会使得簇内的样本距离代表点更近,而簇间的距离更远,最终达到收敛。
与k-means算法不同,k-medoids算法不是适用于高维数据集,因为在高维空间中,欧几里得距离的性质会失效,需要使用更加复杂的距离度量方式。
K-medoids算法特点
优点:
1. 鲁棒性强:K-medoids算法采用一组代表性点(medoids)代表聚类簇,因此在数据噪声较大或者存在离群点的情况下,比k-means更加鲁棒。
2. 可解释性好:由于medoids是实际存在于数据集中的点,所以聚类结果更容易被理解和解释。
3. 适用于非凸数据集:相比k-means算法只适用于凸数据集,K-medoids算法可以处理非凸数据集的聚类问题。
缺点:
1. 运算速度慢:由于K-medoids算法需要计算每个点到medoid的距离,因此计算复杂度较高,时间复杂度为O(K*N^2),其中K为聚类簇数,N为数据点数。
2. 对初始值敏感:K-medoids算法的聚类结果取决于初始medoid的选择,因此需要多次随机初始化来获得更好的聚类结果。
3. 不适用于大数据分析:由于计算复杂度较高,K-medoids算法不适合处理大数据集。
四、送书活动
618,清华社 IT BOOK 多得图书活动开始啦!活动时间为 2023 年 6 月 7 日至 6 月 18 日,清华
社为您精选多款高分好书,涵盖了 C++、Java、Python、前端、后端、数据库、算法与机器学习等多
个 IT 开发领域,适合不同层次的读者。全场 5 折,扫码领券更有优惠哦!快来京东点击链接 IT BOOK
多得(或扫描京东二维码)查看详情吧!

详情了解:《Python从入门到精通(微课精编版)(软件开发视频大讲堂)》(前沿科技)【摘要 书评 试读】- 京东图书

五、抽奖规则
活动时间: 截止到2023-06-18 12: 00
参与方式: 点赞、收藏本文章,并评论
抽奖时间: 2023.06.18
公布时间: 2023.06.20
通知方式: 私信和动态通知(一共50本书)
获奖名单:
i阿极
不是笨小孩i.
Ja_小浩