实验目的
实验内容
实验步骤
1、层次聚类算法
1.1 层次聚类算法的基本思想
层次聚类(Hierarchical Clustering)是一种基于样本之间的相似度或距离度量进行自下而上聚合的聚类方法。其基本思想是将每个数据点视为一个单独的簇,然后通过计算不同簇之间的相似度或距离,逐步合并相似度高的簇,直到达到指定的聚类簇数或者某个合并条件不再满足为止。
1.2 层次聚类的聚类过程
- 计算样本之间的距离。这里涉及到距离度量的选择,可以使用欧式距离、曼哈顿距离等。
- 将每个样本看作一个簇。初始化时,每个簇内都只包含一个样本点。
- 寻找距离最近的两个簇,并将其合并成一个新的簇。这里有两种合并方式,分别是单链接和全链接。单链接是将两个簇中距离最近的样本点之间的距离作为两个簇之间的距离,而全链接则是将两个簇中距离最远的样本点之间的距离作为两个簇之间的距离。
- 更新距离矩阵。在新得到的簇中,计算所有样本与其他样本的距离,并将其更新到距离矩阵中。
- 重复步骤3、4,直到满足终止条件。可以通过设定聚类的簇数或者距离阈值来控制聚类的终止条件。其中距离阈值是指在聚类过程中,两个簇之间的距离超过该阈值时停止合并。
- 最终得到聚类结果。将所有样本根据聚类结果进行标记,并输出聚类簇数以及各簇内的样本数量和均值等信息。
如讲义中展示的,假设有五条数据,对这5条数据通过上述步骤构造的树。图1展示了通过上述步骤构造的树。
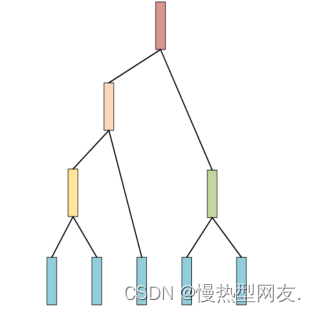
需要注意的是,层次聚类的效率通常较低,在处理大规模数据集时可能会遇到内存不足等问题。此外,由于层次聚类是一种贪心算法,所以其最终结果可能受到初始状态和合并顺序的影响。因此,在使用层次聚类时,需要选择合适的距离度量和合并方式,并尽量对原始样本进行预处理以提高聚类的准确度。
2、使用Python语言编写层次聚类的源程序代码并分析其分类原理
2.1 层次聚类 Python代码
2.1.1 计算欧式距离函数euler_distance
用于计算两个样本点之间的距离:
(1)point1和point2都表示样本点,分别为两个向量,可以是任意维度的。
(2)首先计算两个向量中所有对应位置上元素差的平方的和,即,其中nn为向量的维度。
(3)对该和进行开方运算,得到样本之间的欧氏距离dd。图2为欧式距离函数的具体实现:

2.1.2 层次聚类的类
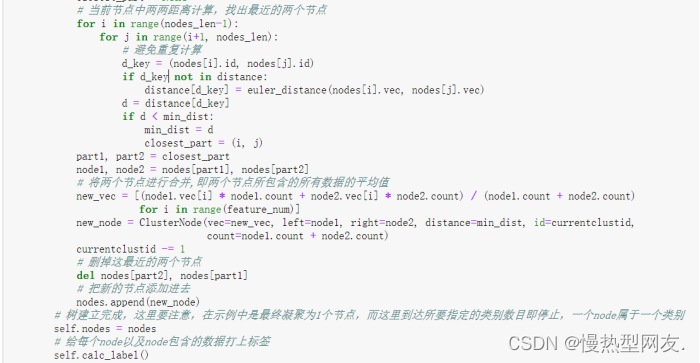
该类中的fit()方法即为训练模型并聚类的过程,主要流程如下:
(1)首先将每个样本点看做一个独立的簇,将其封装成ClusterNode对象,并将这些节点放在列表中。
(2)不断循环直到达到所要指定的类别数目或者只剩下一个节点(即聚为一类):
计算任意两个节点之间的距离,并找出距离最近的两个节点。
合并这两个节点,生成一个新的节点,并将其加入到节点列表中。
删除已经被合并的两个节点,并将新的节点加入到列表中。
(3)给每个节点以及节点包含的数据打上标签,即将每个节点对应的标签赋给其中的数据。
图3展示了fit()方法中的核心部分。
2.1.3 使用 sklearn自带的鸢尾花的数据集进行测试
使用sklearn库中的load_iris函数生成一个鸢尾花数据集,并使用自己实现的层次聚类算法和sklearn库中的基于KMeans算法的聚类方法对该数据集进行聚类,最终将聚类结果可视化展示出来。图4展示了两个聚类结果的可视化。
 聚类结果的可视化" />
聚类结果的可视化" />
通过对比两种聚类方法的结果,可以看出它们对于数据集的划分存在差异,因为聚类算法的性能和效果受到很多因素的影响,选择适当的聚类算法和参数对于得到理想的聚类结果很关键。
2.1.4 绘制层次聚类树
通过使用sklearn库中的AgglomerativeClustering函数和MinMaxScaler函数对鸢尾花数据集进行聚类和数据归一化处理,并使用scipy库中的linkage和dendrogram函数绘制层次聚类树。图5展示了绘制出的层次聚类树。
 聚类树" />
聚类树" />
层次聚类的优缺点
优点:
缺点:
1、计算复杂度太高,其复杂度为 O ( n^3m ) ,其中m是样本的维数,n是样本个数。
2、奇异值也能产生很大影响
3、算法很可能聚类成链状
2.2 DBSCAN算法Python代码
2.2.1 搜索邻域内点函数find_neighbor
具体实现过程如下:
- 使用欧式距离计算数据集中每个点与核心点的距离,并求和得到距离总和temp。
- 使用np.argwhere函数找出距离总和小于等于邻域半径eps的点的索引。
- 将索引展开为一维数组,并转换为列表形式,得到该核心点的邻域N。
函数的输出是核心点j的邻域N,即距离该核心点距离小于等于邻域半径eps的所有点的索引列表。图6为搜索邻域内点函数的具体实现:

2.2.2 聚类算法 DBSCAN
聚类算法 DBSCAN的具体实现过程如下:
- 初始化,将所有点标记为未处理状态,并保存它们的邻域和核心点。
- 随机选取一个核心点 j,以该点作为中心建立一个新簇 Ck。
- 将核心点从未处理点集合中删除,并将它的密度可达点加入待处理列表 Q。
- 循环处理待处理列表 Q 中的所有点,找出它们的密度可达点。
- 将所有密度可达点加入簇 Ck 中,并将它们从未处理点集合 gama 中删除。
- 重复步骤 2-5,直到所有核心点都被访问完毕。
- 返回聚类结果 cluster。图7为聚类算法DBSCAN的核心部分
 聚类算法DBSCAN的核心部分" />
聚类算法DBSCAN的核心部分" />
其中,eps 和 MinPts 是 DBSCAN 算法的两个关键参数,分别代表邻域半径和最密度,用于判断一个点是否属于核心点或边界点。如果一个点的邻域内包含至少 MinPts 个点,则它被认为是一个核心点;如果一个点不是核心点,但它的邻居中至少有一个核心点,则它被认为是一个边界点。如果一个点既不是核心点也不是边界点,则它被认为是噪声点。
2.2.3 DBSCAN对生成的样本数据进行聚类
使用 DBSCAN 算法对生成的样本数据进行聚类,并将结果可视化。其中,make_circles 和 make_blobs 是 sklearn.datasets 中的两个函数,用于生成不同形状的样本数据。X1 和 y1 代表圆形数据集,X2 和 y2 代表高斯分布数据集,两者合并在一起构成了总的数据集 X。
图8为使用 DBSCAN 算法聚类可视化后的图片。
 聚类可视化后的图片" />
聚类可视化后的图片" />
2.2.4 使用sklearn中的DBSCAN类对生成的样本数据进行聚类
这段代码与2.2.3中的代码类似,也是使用 DBSCAN 算法对数据集 X 进行聚类,并将结果可视化。不同的是,这里直接调用 sklearn.cluster 中的 DBSCAN 类来实现聚类。在实例化 DBSCAN 类时,通过设置 eps 和 min_samples 定义了核心点的邻域半径和最小密度阈值。同时,metric 参数指定了距离度量方法,algorithm 参数指定了最近邻搜索算法。图9为使用sklearn中的DBSCAN类聚类可视化后的图片。
 聚类可视化后的图片" />
聚类可视化后的图片" />
DBSCAN算法的优缺点
优点:
1、不必指定聚类的类别数量;
2、可以形成任意形状的簇,而 K-means 只适用于凸数据集;
3、对于异常值不敏感;
缺点:
1、计算量较大,对于样本数量和维度巨大的样本,计算速度慢,收敛时间长,这时可以采用 KD 树进行改进;
2、 对于 eps 和MinPts 敏感,调参复杂,需要联合调参;
3、 样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN算法一般不适合;
4、 样本同采用一组参数聚类,有时不同的簇的密度不一样;
5、 由于对噪声不敏感,在一些领域,如异常检测不适用。
实验小结
通过本次实验,我能够熟练叙述层次聚类算法的基本思想;描述层次聚类的整个聚类过程。可以根据实验内容完成使用Python语言编写层次聚类的源程序代码并分析其分类原理。在实验过程中遇到了很多硬件或者是软件上的问题,请教老师,询问同学,上网查资料,都是解决这些问题的途径。最终将遇到的问题一一解决最终完成实验。
常用的层次聚类方法主要有以下两种:
凝聚型层次聚类(AGNES):以距离为相似性度量,将每个样本视为一个簇,然后逐渐合并相邻的簇直到整个数据集都成为一个大的簇。具体而言,每次将距离最近的两个簇合并成一个新的簇,直到只剩下一个簇为止。
分裂型层次聚类(DIANA):与凝聚型层次聚类相反,它是从一个大簇开始,逐步将其分裂成多个小簇。在分裂过程中,先确定一个代表簇,然后将其他数据点与该代表簇进行距离度量,并将距离最远的点分裂出一个新的簇,直到达到预定的簇数。
这两种方法都可以用于处理不同形状和大小的簇,但它们的计算开销很大并且难以处理大规模数据集。因此,在实际应用中常用其他更高效的聚类算法,如 K-Means、DBSCAN、OPTICS 等。
源代码
import math
import numpy as np
def euler_distance(point1, point2):
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a-b, 2)
return math.sqrt(distance)
# 定义聚类树的节点
class ClusterNode:
def __init__(self, vec, left=None, right=None, distance=-1, id=None, count=1):
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
self.count = count
# 层次聚类的类
# 不同于文中所说的先构建树,再进行切分,而是直接根据所需类别数目,聚到满足条件的节点数量即停止
# 和k-means一样,也需要指定类别数量
class Hierarchical:
def __init__(self, k=1):
assert k > 0
self.k = k
self.labels = None
def fit(self, x):
# 初始化节点各位等于数据的个数
nodes = [ClusterNode(vec=v, id=i) for i, v in enumerate(x)]
distance = {}
point_num, feature_num = np.shape(x)
self.labels = [-1] * point_num
currentclustid = -1
while len(nodes) > self.k:
min_dist = np.inf
# 当前节点的个数
nodes_len = len(nodes)
# 最相似的两个类别
closest_part = None
# 当前节点中两两距离计算,找出最近的两个节点
for i in range(nodes_len-1):
for j in range(i+1, nodes_len):
# 避免重复计算
d_key = (nodes[i].id, nodes[j].id)
if d_key not in distance:
distance[d_key] = euler_distance(nodes[i].vec, nodes[j].vec)
d = distance[d_key]
if d < min_dist:
min_dist = d
closest_part = (i, j)
part1, part2 = closest_part
node1, node2 = nodes[part1], nodes[part2]
# 将两个节点进行合并,即两个节点所包含的所有数据的平均值
new_vec = [(node1.vec[i] * node1.count + node2.vec[i] * node2.count) / (node1.count + node2.count)
for i in range(feature_num)]
new_node = ClusterNode(vec=new_vec, left=node1, right=node2, distance=min_dist, id=currentclustid,
count=node1.count + node2.count)
currentclustid -= 1
# 删掉这最近的两个节点
del nodes[part2], nodes[part1]
# 把新的节点添加进去
nodes.append(new_node)
# 树建立完成,这里要注意,在示例中是最终凝聚为1个节点,而这里到达所要指定的类别数目即停止,一个node属于一个类别
self.nodes = nodes
# 给每个node以及node包含的数据打上标签
self.calc_label()
def calc_label(self):
# 调取聚类结果
for i, node in enumerate(self.nodes):
self.leaf_traversal(node, i)
def leaf_traversal(self, node: ClusterNode, label):
# 递归遍历叶子结点
if node.left is None and node.right is None:
self.labels[node.id] = label
if node.left:
self.leaf_traversal(node.left, label)
if node.right:
self.leaf_traversal(node.right, label)
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import MinMaxScaler
model = AgglomerativeClustering(n_clusters=4, affinity='euclidean', memory=None, connectivity=None,
compute_full_tree='auto', linkage='ward', pooling_func='deprecated')
data_array = np.array(load_iris().data[:50, :])
min_max_scalar = MinMaxScaler()
data_scalar = min_max_scalar.fit_transform(data_array)
model.fit(data_scalar)
from scipy.cluster.hierarchy import linkage, dendrogram
plt.figure(figsize=(20, 6))
Z = linkage(data_scalar, method='ward', metric='euclidean')
p = dendrogram(Z, 0)
plt.xlabel ('初始样本',fontname=('SimHei'))
plt.ylabel ('聚类水平',fontname=('SimHei'))
plt.grid(color="grey", linestyle="-.")# 网格
plt.show()
import numpy as np
import random
import matplotlib.pyplot as plt
import copy
from sklearn import datasets
# 搜索邻域内的点
def find_neighbor(j, x, eps):
"""
:param j: 核心点的索引
:param x: 数据集
:param eps:邻域半径
:return:
"""
temp = np.sum((x - x[j]) ** 2, axis=1) ** 0.5
N = np.argwhere(temp <= eps).flatten().tolist()
return N
def DBSCAN(X, eps, MinPts):
k = -1
# 保存每个数据的邻域
neighbor_list = []
# 核心对象的集合
omega_list = []
# 初始化,所有的点记为未处理
gama = set([x for x in range(len(X))])
cluster = [-1 for _ in range(len(X))]
for i in range(len(X)):
neighbor_list.append(find_neighbor(i, X, eps))
if len(neighbor_list[-1]) >= MinPts:
omega_list.append(i)
omega_list = set(omega_list)
while len(omega_list) > 0:
gama_old = copy.deepcopy(gama)
# 随机选取一个核心点
j = random.choice(list(omega_list))
# 以该核心点建立簇Ck
k = k + 1
Q = list()
# 选取的核心点放入Q中处理,Q中只有一个对象
Q.append(j)
# 选取核心点后,将核心点从核心点列表中删除
gama.remove(j)
# 处理核心点,找出核心点所有密度可达点
while len(Q) > 0:
q = Q[0]
# 将核心点移出,并开始处理该核心点
Q.remove(q)
# 第一次判定为True,后面如果这个核心点密度可达的点还有核心点的话
if len(neighbor_list[q]) >= MinPts:
# 核心点邻域内的未被处理的点
delta = set(neighbor_list[q]) & gama
delta_list = list(delta)
# 开始处理未被处理的点
for i in range(len(delta)):
# 放入待处理列表中
Q.append(delta_list[i])
# 将已处理的点移出标记列表
gama = gama - delta
# 本轮中被移除的点就是属于Ck的点
Ck = gama_old - gama
Cklist = list(Ck)
# 依次按照索引放入cluster结果中
for i in range(len(Ck)):
cluster[Cklist[i]] = k
omega_list = omega_list - Ck
return cluster
X1, y1 = datasets.make_circles(n_samples=2000, factor=.6, noise=.02)
X2, y2 = datasets.make_blobs(n_samples=400, n_features=2, centers=[[1.2, 1.2]], cluster_std=[[.1]], random_state=9)
X = np.concatenate((X1, X2))
eps = 0.08
min_Pts = 10
C = DBSCAN(X, eps, min_Pts)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=C)
plt.grid(color="grey", linestyle="-.")# 网格
plt.show()
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.08, min_samples=10, metric='euclidean', algorithm='auto')
model.fit(X)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=model.labels_)
plt.grid(color="grey", linestyle="-.")# 网格
plt.show()