Learning to cluster in order to transfer across domains and tasks (ICLR 2018)
摘要
这篇论文提出一个进行跨域/任务的迁移学除了习任务,并将其作为一个学习聚类的问题。除了特征,我们还可以迁移相似度信息,并且这是足以学习一个相似度函数和聚类网络来同时进行域自适应和跨任务迁移学习。首先,我们将分类信息弱化为两两约束,也就是只考虑两个样本是否属于同一类(两两语义相似度)。这种相似度是不知道类别的,并且可以通过相似度网络从源域数据中学到。我们接着展示了两种用这个相似度函数的新方法来进行迁移学习。第一,针对无监督的域自适应任务,我们设计了一种新的损失函数来正则化带有约束的聚类损失的分类,因此学习一个带有迁移相似度度量的聚类网络来生成训练输入。第二,针对跨任务学习(例如含有未知类别的无监督聚类),我们提出一个框架再次利用聚类网络来重构和估计语义簇的数量。因为相似度网络是具有噪声干扰的,因此关键是用一个强健的聚类算法。并且,我们展现了我们的构想是比一些可选择的带约束或者无约束的聚类方法更加稳定。使用该方法,我们首先展示针对具备挑战性的跨任务问题最先进的结果,应用在Omniglot和ImageNet数据集上。我们的实验结果说明我们可以以较高的准确率来重构语义簇。然后,我们使用来自Office-31和SVHN-MNIST的图像评估跨域迁移的性能,并在这两个数据集上显示了最高的准确性。我们的方法没有明确地处理域差异。如果结合域自适应损失,则显示出进一步的改进。
迁移学习任务
为了定义这项工作中的迁移学习任务,我们沿用了Pan和Yang的符号。迁移学习的目标是从源域数据 S = ( X S , Y S ) S=(X_S,Y_S) S=(XS,YS)迁移知识到目标域 T = ( X T , Y T ) T=(X_T,Y_T) T=(XT,YT),其中 X S X_S XS是数据样本集合, Y S Y_S YS是与之对应的类别标签。该学习过程是无监督的,因为 Y T Y_T YT是未知的。该场景被分为两只情况。一种是 { Y T } ≠ { Y S } \{Y_T\}\ne \{Y_S\} {YT}={YS},也就是说类别集合是不相同的,因此这种迁移被称为跨任务迁移;另一种是 { Y T } = { Y S } \{Y_T\}=\{Y_S\} {YT}={YS},但是存在域偏移,换句话说,输入数据的边缘概率分布是不同的,例如 P ( X T ) ≠ P ( X S ) P(X_T) \ne P(X_S) P(XT)=P(XS)。后者是一种跨域学习问题,也被称为直推式学习。最近获得极大关注的域自适应方法属于第二种例子。
为了对齐常用基准测试集来评估迁移学习的能力,我们继续使用辅助数据集的记法,并且将源数据分为两个部分
S
=
S
′
∪
A
S=S' \cup A
S=S′∪A,其中
S
′
=
(
X
S
′
,
Y
S
′
)
S'=(X'_S,Y'_S)
S′=(XS′,YS′)是仅在跨域迁移方案中使用,并且
{
Y
T
}
=
{
Y
S
′
}
\{Y_T\}=\{Y'_S\}
{YT}={YS′}。
A
=
(
X
A
,
Y
A
)
A=(X_A,Y_A)
A=(XA,YA)是辅助数据集,包含大量的标注数据和潜在类别,即可能包含
{
Y
T
}
\{Y_T\}
{YT}中的部分类别,也可能不包含。对跨任务场景,只使用
A
A
A和无标注的
T
T
T,而对跨域任务而言,则包含
A
,
S
′
A, S'
A,S′和
T
T
T。在接下来的章节都采用以上符号,并详细描述两类迁移学习任务。大意如图所示: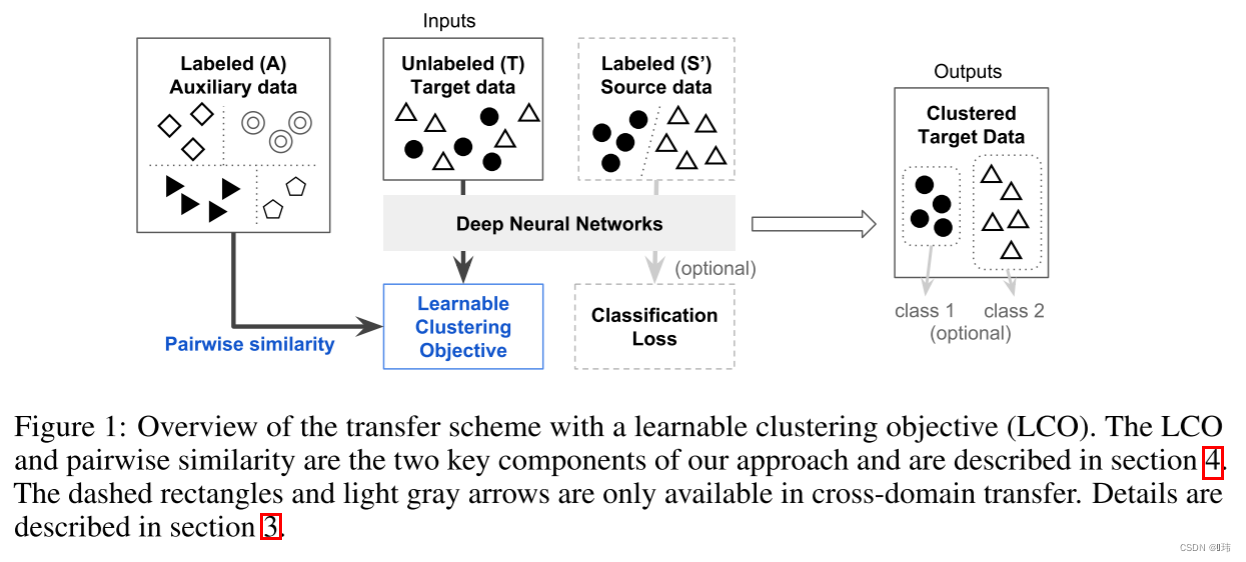
跨任务迁移
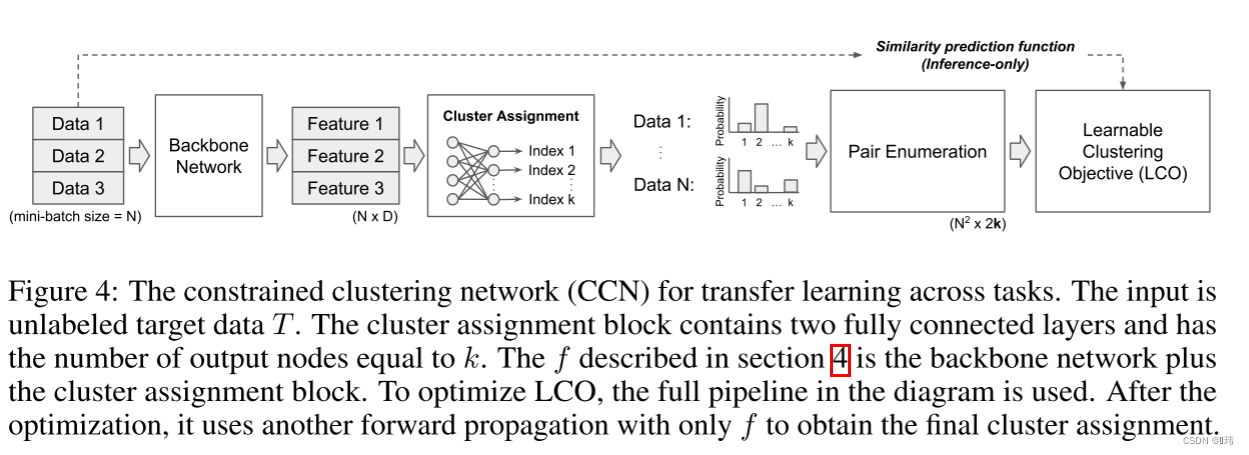
如果目标任务中含有不同的类别,我们不能直接从源域迁移分类器,并且我们是没有标注好的目标域的数据用来微调迁移特征。在此,我们首先提出要将分类问题简化为代理同任务问题,对于变形后的问题,我们直接使用了直推式迁移学习。目标域中的簇结构是通过变形后的任务的预测结果重构出来的。
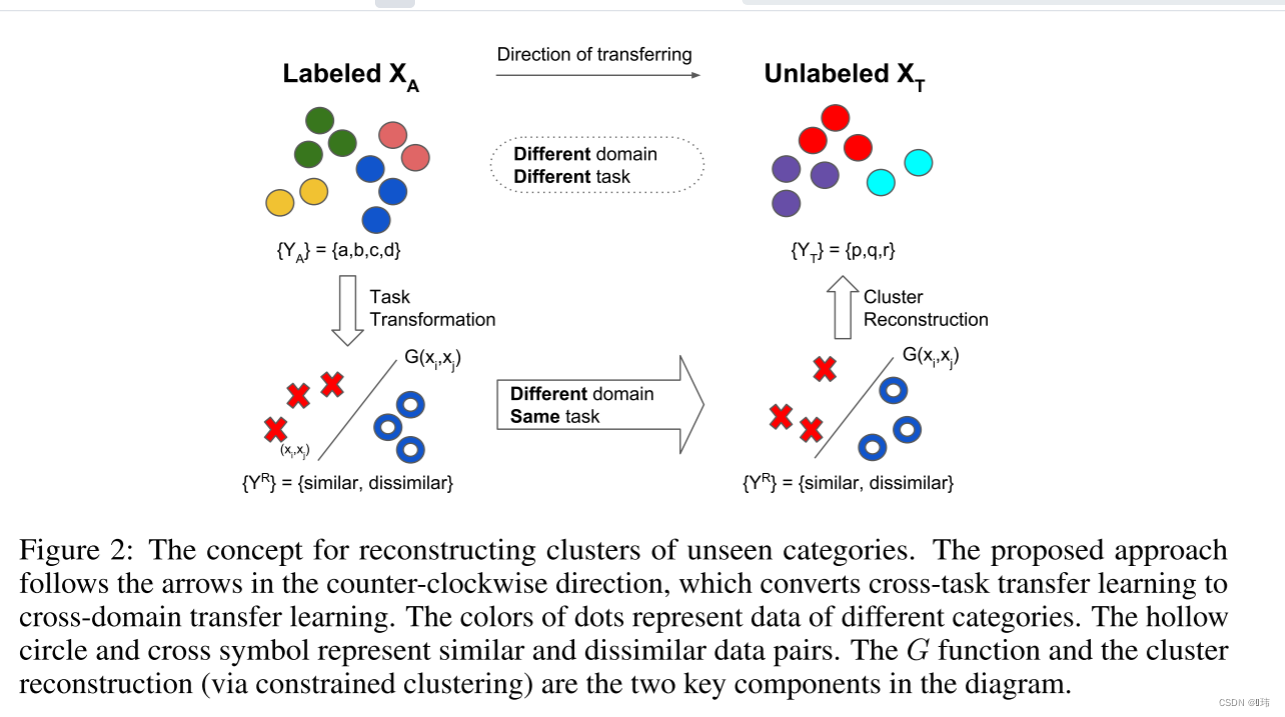
源数据包含一个标注好的辅助数据集 A A A,和一个未标注的目标数据集 T T T, Y T Y_T YT必须是可以推导的。在该场景下类别集合 { Y A } ≠ { Y T } \{ Y_A\} \ne \{Y_T\} {YA}={YT},并且 Y T Y_T YT是未知的。我们首先将分类问题转化为一个两两相似度预测问题。换句话说,我们指定了一个变换函数 R R R使得 R ( A ) = ( X A R , Y R ) R(A)=(X^R_A, Y^R) R(A)=(XAR,YR),其中 X A R = { ( x A , i , x A , j ) } ∀ i , j X^R_A=\{(x_{A,i},x_{A,j})\}_{\forall i,j } XAR={(xA,i,xA,j)}∀i,j包含所有组合,而 Y R = { d i s s i m i l a r , s i m i l a r } {Y^R}=\{dissimilar, similar\} YR={dissimilar,similar},对标注好的辅助数据的变换是很简单的。如果两个数据样本来自同一个类别,那么标签就是 s i m i l a r similar similar,反之亦然。我们用它去学习一个两两相似度预测函数 G ( x i , x j ) = y i , j G(x_i,x_j)=y_{i,j} G(xi,xj)=yi,j。通过在 T T T上应用 G G G,我们可以得到 G ( x T , i , x T , j ) = y T , i , j G(x_{T,i}, x_{T,j})=y_{T,i,j} G(xT,i,xT,j)=yT,i,j。下一步就是从 Y T R = { y T , i , j } ∀ i , j Y^R_T= \{y_{T,i,j}\}_{\forall i,j } YTR={yT,i,j}∀i,j中推导出 Y T Y_T YT,这个可以通过带约束的聚类算法解决,由于 Y T Y_T YT是未知的,所以算法只能推导出类别的索引,这可以说任意顺序。预期所得到的聚类结果将包含一致的语义类别。
跨域迁移
我们考虑该问题的设置等同于无监督的域自适应。按照标准的评估步骤,标注数据集 A A A是 I m a g e N e t ImageNet ImageNet, S ′ S' S′是 O f f i c e − 31 Office-31 Office−31数据集,未标注的 T T T是 O f f i c e − 31 Office-31 Office−31数据集中的另一个域。目标就是增强在 T T T上的分类性能,通过利用 A , S ′ , T A, S', T A,S′,T。
可学习聚类目标(LCO)
受在损失函数中加入两两之间信息的约束聚类的启发,我们方法的关键是设计一个学习目标来利用预测的两两相似度(含有噪声)。成对的信息称为必须连接/不能链接(must-link/cannot-link)或者相似/不相似对(similar/dissimilar),本文中使用的是后者。相应地,相似和不相似对之间的信息也被二值化为0和1。
尽管很多带约束的聚类算法已经被提出,但很少有算法可以根据成对关系的数量而伸缩的。进一步就是,没有一个可以轻松和深度神经网络相结合。受到Hsu和Kira工作的启发,我们构建出在softmax分类器上的概率输出上聚类的对比损失。但是,每一个输出节点不需要映射为一个固定的类别,而是每个输出节点表示一个数据点到一个簇的概率分配。输出结点和簇之间的分配是在优化过程中随机形成的,并且是以两两相似度指导的。如果这是一个相似对,那么它们的输出分布应该是一样的,反之亦然。
具体而言,我们用两两之间的KL散度来评估两个数据样本在
k
k
k个簇分配上的分布距离,并用预测的相似度来构建对比损失。
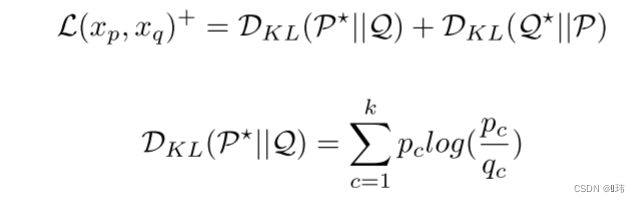
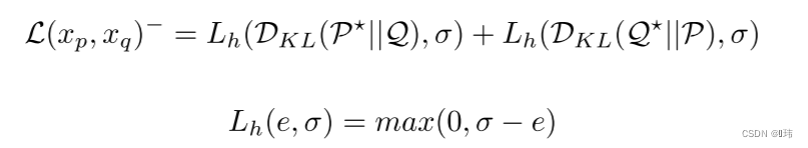
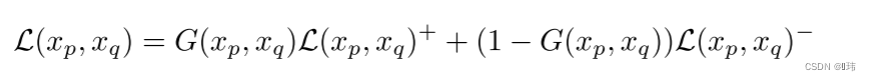
两两相似度网络
尽管没有限制
G
G
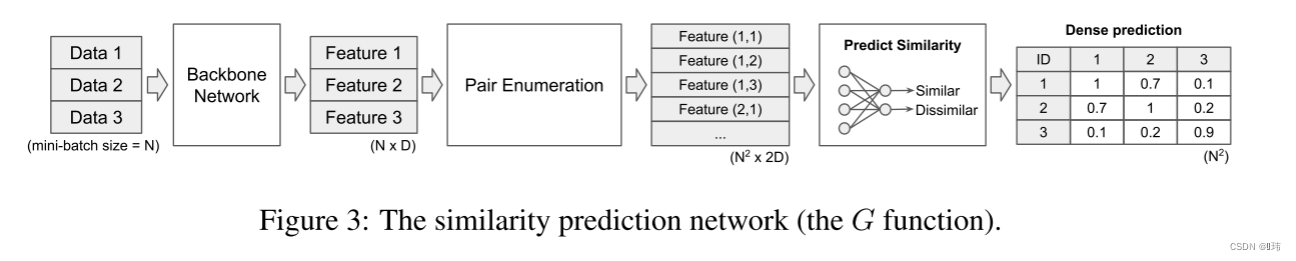
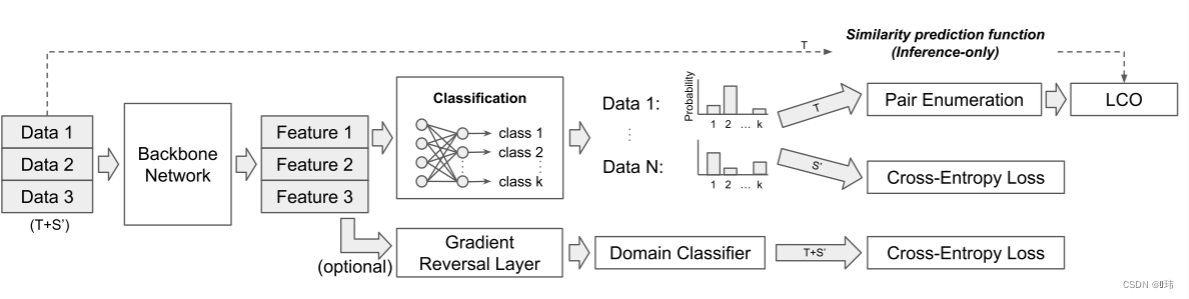
G应该如何建立,但我们还是因为在视觉任务中的有效性选择深度卷积网络。我们根据Zagoruko设计了一种网络架构,他们将其用于预测图片块之间的相似度,而我们用来预测图片级语义相似度。但是在他们的工作里孪生架构在训练和推理中并不是很有效,尤其是在两两信息是稠密的情况下。因此为了取代孪生网络,我们保持使用单个骨干网络但在特征提取网络之上增加了对枚举层。对枚举层枚举小批量中的所有特征对,并拼接特征。假设层的输入为10 × 512,小批量大小为10,特征尺寸为512,那么对枚举层的输出为100 × 1024(包括自身和自身组成的样本对)。
我们添加一个隐藏全连接层在枚举层的顶端和一个二值分类器在尾端。我们用一个标准交叉熵损失来端到端训练。通过将ground-truth类别标签转化为二元相似度,获得训练的监督。如果两个样本来自同一类,那么他们的标签将是相似的,否则不相似。推理也是端到端,它在一个小批处理中输出所有相似对之间的预测。具有1的输出概率
g
∈
[
0
,
1
]
g∈[0,1]
g∈[0,1]表示更相似。我们在0.5处对
G
G
G进行二值化,以获得离散的相似性预测。在下面的章节中,我们将两两相似度预测网络的符号简化为
G
G
G。一旦学习了
G
G
G,它就会在我们的实验中作为一个静态函数。
具有稠密相似度预测的目标函数
由于小批量的两两预测可以密集地从
G
G
G获取,为了高效利用这些成对的信息而不用多次将每一个数据传入模型,我们结合了前面所说的对枚举层和公式5。这样softmax的输出就可以逐对枚举。一个小批量的稠密聚类损失如下所示:
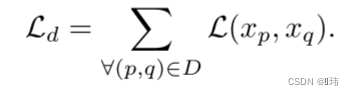
我们用该损失单独和深度神经网络结合来重构语义簇,并且用于跨任务迁移学习。该架构被称为约束聚类网络(CCN)。
联合其它目标函数
在跨域任务中,我们额外具有一些标注好的源数据。这个使得我们针对
T
T
T使用
L
C
O
LCO
LCO时也可以用
S
′
S'
S′训练分类损失。整个训练过程和之前的域自适应方法类似,都是小批量中混合源域数据和目标域数据,不同点就在于使用的损失。针对跨域迁移的损失函数如下:
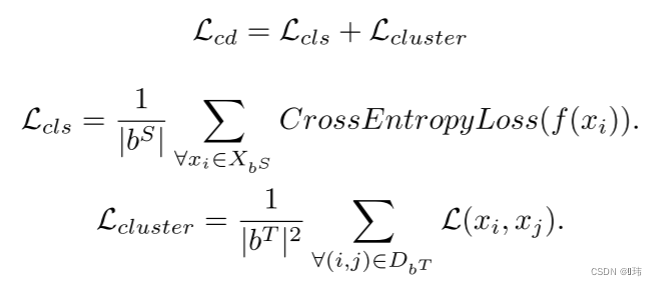
emmm···
这个方法觉得就挺不靠谱的,整个算法的性能很大程度上都依赖所谓的
G
G
G,也就是相似度预测模型,这么重要的组成部分仅仅是在辅助数据集
I
m
a
g
e
N
e
t
ImageNet
ImageNet训练完就固定了,而没有想办法在后续的训练过程继续去微调一下相似度预测模型,将在
A
A
A上训练的
G
G
G应用在
T
T
T上,这本身就是一个跨域迁移任务。而且,所提到的另一个重要模块
L
C
O
LCO
LCO,个人觉得基本和16年那篇论文一致,几乎没有改动。
简单总结一下就是:
跨任务迁移学习就用辅助数据训练一个二分类器给目标域数据一个相不相似的伪标签,然后用
L
C
O
LCO
LCO去训练。
跨域迁移学习就是在上面基础上加个分类损失。

