C# | DBSCAN聚类算法实现
聚类算法是一种常见的数据分析技术,用于将相似的数据对象归类到同一组或簇中。其中,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够有效地识别出不同形状和大小的簇,同时还能标识出噪声数据。本篇博客将介绍聚类算法的概念、DBSCAN算法的原理,并通过提供的C#代码逐步解析DBSCAN算法的实现过程。
什么是聚类算法
聚类算法是一种通过对数据对象进行分组,使得同一组内的对象彼此相似,而不同组之间的对象差异较大的算法。聚类算法的目标是发现数据中的内在结构,并根据对象之间的相似性进行分类。
聚类算法的应用
- 市场细分:将消费者分组为不同的市场细分,以便更好地理解其需求和行为模式。
- 图像分析:将相似的图像区域聚类在一起,以便进行图像分割、目标检测等任务。
- 生物信息学:将基因表达数据聚类,以便发现基因表达模式和生物过程。
什么是DBSCAN算法
DBSCAN算法是一种基于密度的聚类算法,其核心思想是将高密度区域划分为簇,并将低密度区域视为噪声。DBSCAN算法不需要预先指定聚类数量,能够自动发现不同形状和大小的簇,并且对数据分布的要求较低。
DBSCAN算法的思路
DBSCAN算法的过程如下:
- 初始化所有点的标签为-1,表示未分类。
- 遍历所有点,对每个未分类点进行处理。
- 如果点的邻居点数量小于设定的阈值minPts,则将该点标记为噪声点。
- 否则,将该点标记为一个新的簇,并将其邻居点加入扩展簇的邻居点列表中。
- 遍历扩展簇的邻居点列表,对每个邻居点进行处理。
- 如果邻居点未分类,则将其加入当前簇中,并获取其邻居点。
- 如果邻居点已经被分类为噪声点,则将其重新分类到当前簇中。
- 重复步骤5,直到扩展簇的邻居点列表为空。
使用C#实现DBSCAN聚类算法
核心代码
下面是使用C#实现的DBSCAN聚类算法的代码,我们将逐步解析其实现过程。
public static int[] Cluster(List<Point> points, int minPts, int eps)
{
int n = points.Count;
int[] labels = new int[n];
int clusterId = 0;
// 初始化所有点的标签为-1,表示未分类
for (int i = 0; i < n; i++)
{
labels[i] = -1;
}
// 遍历所有点
for (int i = 0; i < n; i++)
{
Point p = points[i];
// 如果点已经分类,则跳过
if (labels[i] != -1)
{
continue;
}
// 找到p的邻居点
List<Point> neighbors = GetNeighbors(points, p, eps);
// 如果邻居点数量小于minPts,则将p标记为噪声点
if (neighbors.Count < minPts)
{
labels[i] = 0;
continue;
}
// 新建一个簇
clusterId++;
labels[i] = clusterId;
// 扩展簇
ExpandCluster(points, labels, p, neighbors, clusterId, eps, minPts);
}
return labels;
}
public static void ExpandCluster(List<Point> points, int[] labels, Point p, List<Point> neighbors, int clusterId, int eps, int minPts)
{
// 遍历邻居点
for (int i = 0; i < neighbors.Count; i++)
{
Point q = neighbors[i];
int index = points.IndexOf(q);
// 如果邻居点未分类,则将其加入簇中
if (labels[index] == -1)
{
labels[index] = clusterId;
// 找到q的邻居点
List<Point> qNeighbors = GetNeighbors(points, q, eps);
// 如果邻居点数量大于等于minPts,则将其加入扩展簇的邻居点列表中
if (qNeighbors.Count >= minPts)
{
neighbors.AddRange(qNeighbors);
}
}
// 如果邻居点已经被分类为噪声点,则将其重新分类到当前簇中
else if (labels[index] == 0)
{
labels[index] = clusterId;
}
}
}
代码讲解
在给定的C#代码中,我们可以看到两个主要的方法:Cluster和ExpandCluster。Cluster方法是DBSCAN算法的入口点,而ExpandCluster方法负责扩展簇。
在Cluster方法中,我们首先对每个点的标签进行初始化,将其设置为-1,表示未分类。然后,我们遍历所有点,对每个未分类点进行处理。
接下来,我们检查当前点的邻居点数量是否小于设定的阈值minPts。如果小于minPts,则将该点标记为噪声点(标签为0),并继续处理下一个点。这里的GetNeighbors方法用于获取当前点的邻居点。
如果邻居点数量大于等于minPts,我们创建一个新的簇,并将当前点标记为该簇的一部分(使用clusterId标识)。然后,我们调用ExpandCluster方法来扩展簇,将邻居点加入扩展簇的邻居点列表中。
在ExpandCluster方法中,我们遍历扩展簇的邻居点列表,对每个邻居点进行处理。对于未分类的邻居点,我们将其加入当前簇,并获取其邻居点。对于已经被分类为噪声点的邻居点,我们将其重新分类到当前簇中。
整个过程将重复进行,直到扩展簇的邻居点列表为空,表示该簇无法再扩展。最终,Cluster方法返回每个点的标签数组labels,其中每个元素表示该点所属的簇。
以上是算法的实现思路,你可以根据需要将其应用于自己的数据集,并根据具体情况调整minPts和eps的取值,以达到最佳的聚类效果。
可视化演示
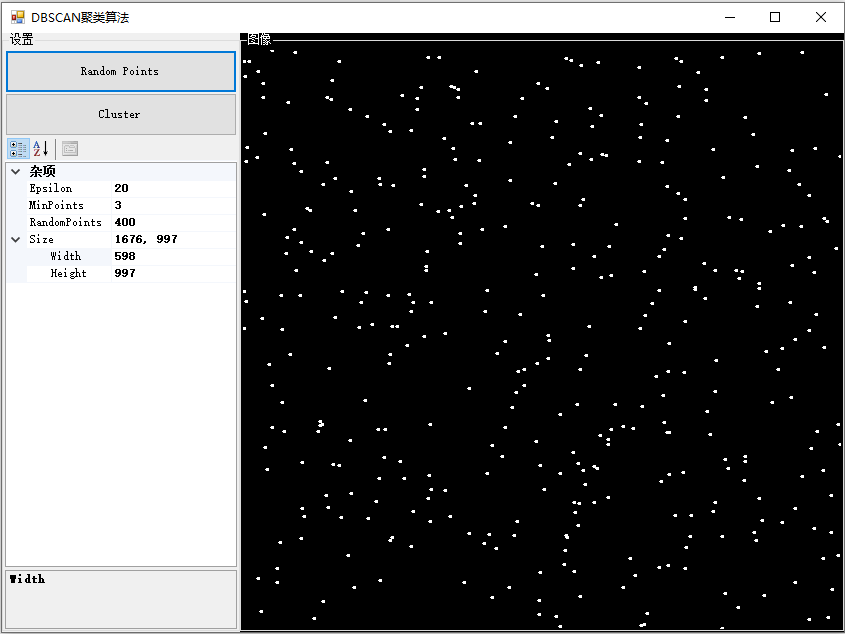
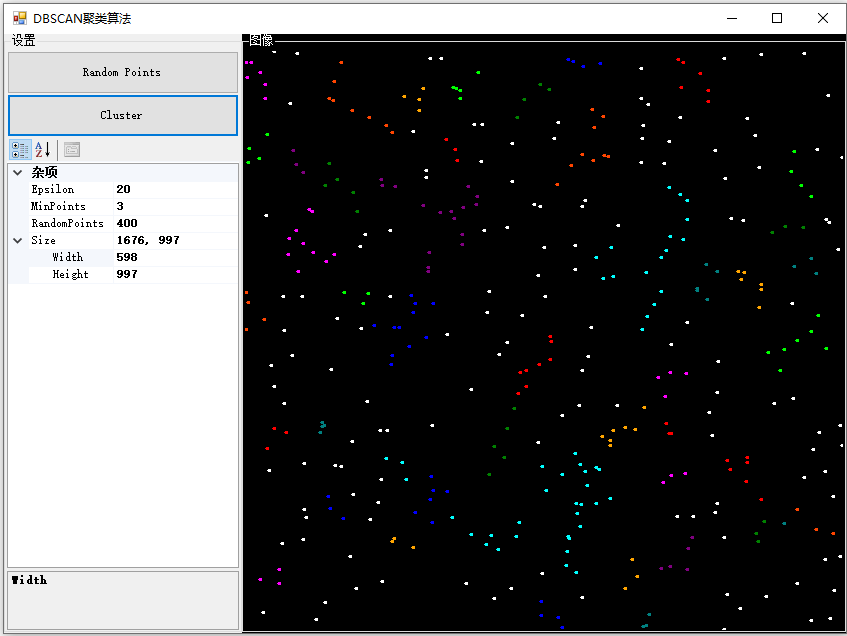
以下是基于上述代码实现的DBSCAN算法演示程序。
在这个演示中,我首先打开了程序界面,然后点击“Random Points”按钮,程序随机生成了一些点在界面上。接着,我调整了DBSCAN算法的参数,包括半径和最小点数,然后点击“Cluster”按钮,程序对生成的点进行了聚类。
注:多次调整参数后进行聚类,可以看到不同参数下聚类的效果不同。
演示程序下载地址:https://download.csdn.net/download/lgj123xj/88277383