一.聚类的概念
K-Means算法是最经典的聚类算法,几乎所有的聚类分析场景,你都可以使用K-Means,而且在营销场景上,它就是"King",所以不管从事数据分析师甚至是AI工程师,不知道K-Means是”不可原谅“的一件事情。在面试中,面试官也经常问关于K-Means的问题。虽然算法简单,但也有一些需要深入理解的点,这些都会在本章节所涉及到。
二.K-Means的迭代过程
在进入K-Means算法的细节之前,我们先了解一下它整个的计算过程,理解起来很简单。整个过程是迭代式的算法,每次迭代过程包含如下两步操作:
- 根据给定的中心点,计算出每一个样本的所属的类别(cluster),这个过程结束之后每一个样本都会有自己所属的类别。
- 之后把每一个类别所属的所有样本提取出来,计算平均值并作为新的中心点。
上述过程会不断循环,直到算法停止为止。
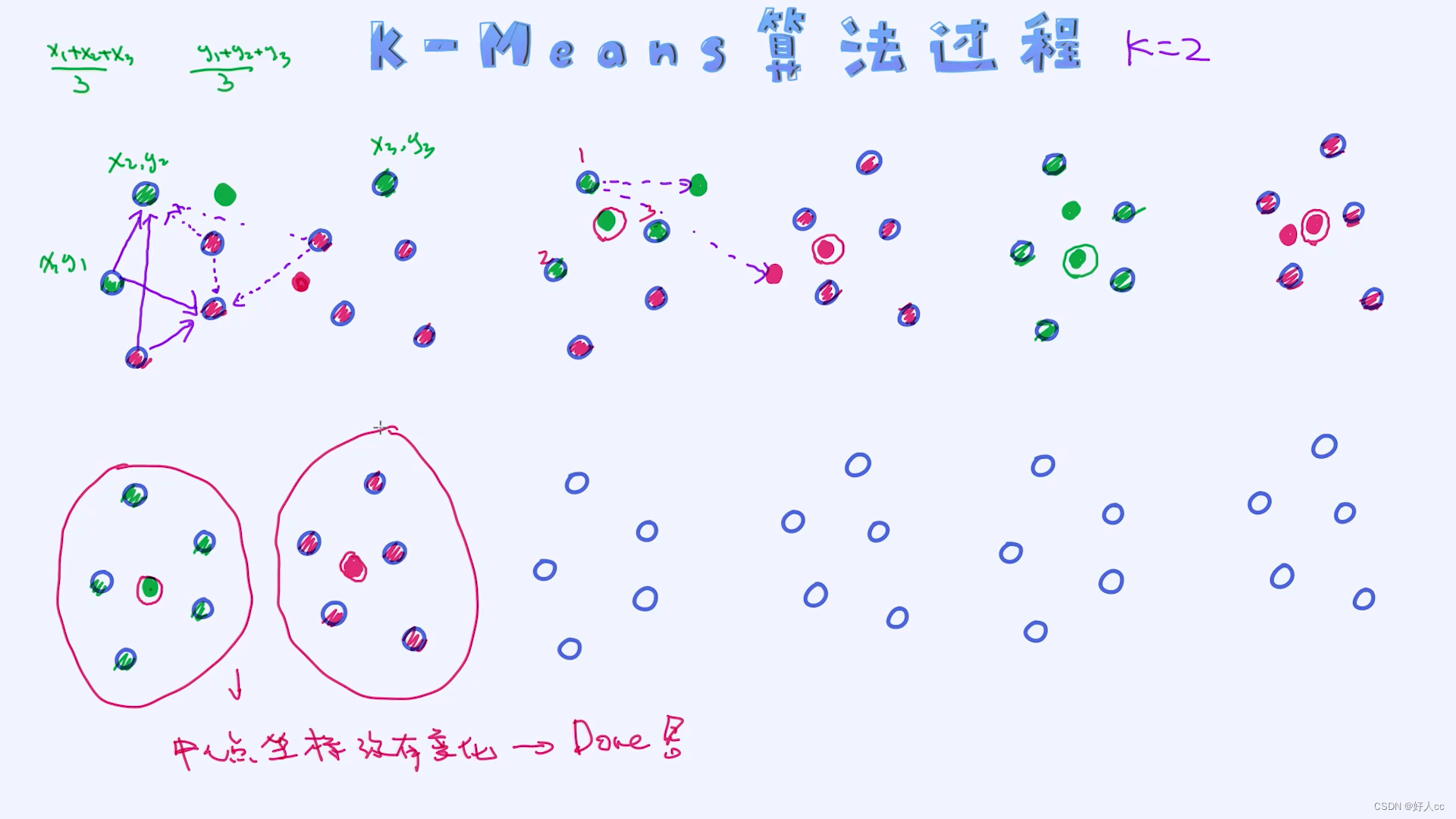


先第一步,固定uk也就是中点,去对样本做标记,标记完用标记后的样本求均值
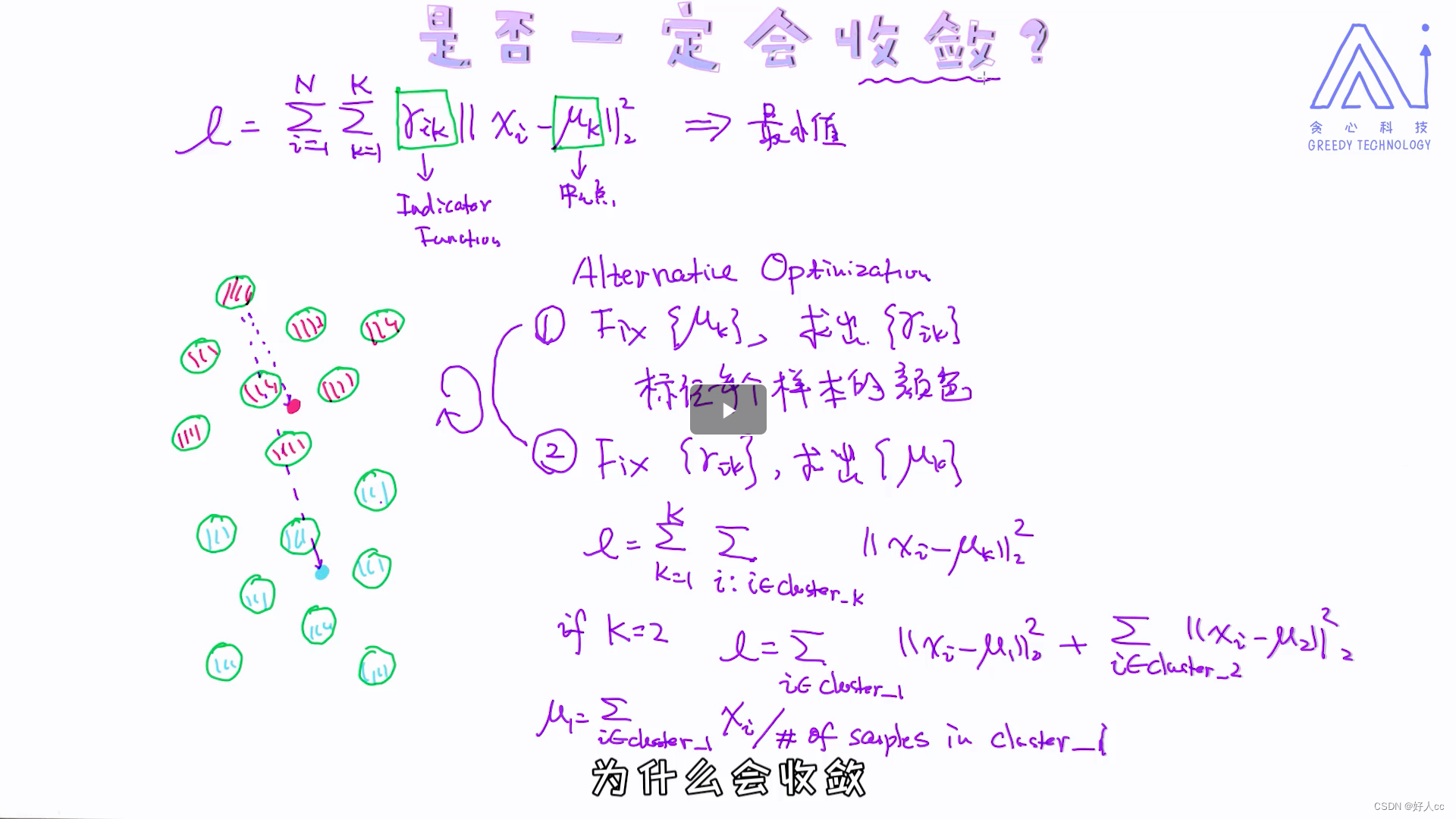
在第一节里我们已经讲过k-Means的实现细节,而且在实现细节上也有分两步骤循环迭代的过程,其实那个过程正好对应现在讲的优化方案:固定中心点,求出每一个样本所属的最佳中心点的过程为算法里的第一步; 固定每个样本的类别,重新计算中心点的过程为算法里的第二步。
三.不同初始化对参数的影响
那这个说明什么问题呢?问题的本质在于我们每次得到的不是全局最优解,而是局部最优解!类似的现象也会发生在神经网络当中,不同的初始化结果会带来不一样的结果。所以当我们使用神经网络的时候会通过一些技巧去更好地初始化参数的。因为,对于这类的模型,好的初始化值会带来更好的最终结果的,也相当于得到了更好的局部最优解。那为什么k-means只能得到局部最优解呢? 其核心是非凸函数。 如果一个目标函数是非凸函数,那我们其实不能保证或者没有办法得到全局最优解的!如果想深入理解这些理论,建议大家去学习一下凸优化理论,所有的细节都会在凸优化领域涉及到的。
四.层次聚类
在上一节为止,我们讨论了如何使用K-Means算法来做聚类。总体来讲,算法通过迭代的方式最后找出聚类的结果。在这里,我们来学习一下另外一种聚类方法叫作层次聚类,通过层次聚类我们可以对原有样本数据做层次上的划分。相反,K-Means算法本身是扁平化的,不具备任何层次的概念,而且使用K-Means的是需要提前指定K值的, 但很多时候我们并不能提前知道到底有分成多少个clusters。
层次聚类,另一方面,不需要提前指定K,而是在学习过程中动态地去选定一个合适的K值。
对于不规则的样本,K-Means算法的表现也会比较差。接下来,我们说一下层次关系。如上所述, K-Means算法在聚类时是不能捕获层次关系的。但层次关系有些时候还是挺有用的,比如通过观察人和人之间的关系来挖掘哪些是事件的发起者、组织是如何运作的。层次聚类算法的好处就是通过算法自动给数据做分层,数据之间的层次关系一目了然,当然这也取决于数据和算法的准确性了。通过层次聚类算法最终我们得到的是一个叫作Dendrogram的图,就是最后的结果。
4.1从下到上的层次聚类
我们来学习一下如何使用自下而上的方式来做层次聚类,这是两种层次聚类算法中最为常见的一种。它的核心思想是:一开始每一个点是一个cluster, 然后把类似的cluster慢慢做合并,到了最后就只剩一个cluster了,这个时候即可以停下来。等做完所有步骤之后,我们就可以从现有的结果中选择合理的聚类结果了。比如我们设定一个阈值,然后基于这个阈值就可以得到相应的clusters了。自下而上层次聚类过程的一个核心是:相似度的计算,因为涉及到了不同cluster之间的合并。下面给大家介绍三种常见的距离计算的方法:
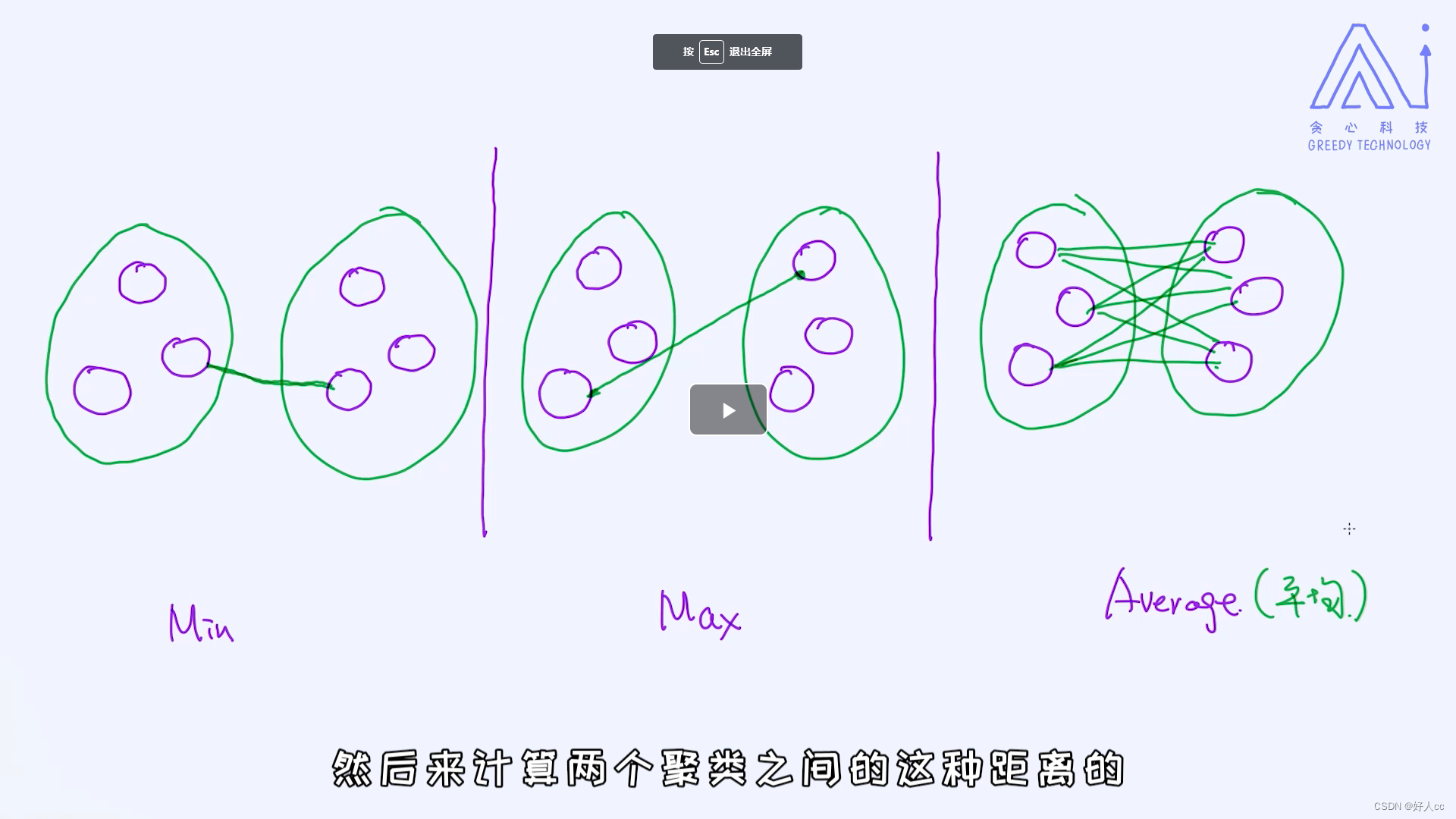
第一种情况是两个cluster的合并是基于最短距离来完成的,第二种情况是根据最长的距离,最后一种情况是通过平均距离来做合并的。
max还是根据最短的来合并,但是距离根据最大距离来算
4.2 从上到下的层次聚类
在这里,我们看另外一种层次聚类算法:自上而下的方法。这个方法恰恰跟自下而上的方法相反。一开始我们只有一个大的cluster, 由所有的样本组成,之后逐步把每一个cluster切分成更小的,直到每一个cluster只包含一个样本为止,这也意味着整个流程已完成。这个过程跟上节课里讲过的恰恰相反,每次需要考虑的是如何把一个大的cluster切分成两个clusters,所以这里的切分标准格外重要。但相比自下而上的方法,自上而下的聚类算法用的并不是那么多,大致了解一下就可以了。
在这里,我来介绍一个比较经典的自上而下的方法。 这个方案基于大家所熟悉的图算法,叫作最小生成树(minimum spanning tree)。

感觉连错了
对于最小生成树,有几个比较常见的算法,分别是Prime和Kruskal算法。具体细节不在这里做详细阐述,感兴趣的朋友们可以自行去查看这两种算法。理解了MST之后,我们就可以开始谈论自上而下的方法了。其实之后的操作非常简单,请看下面的一段视频。
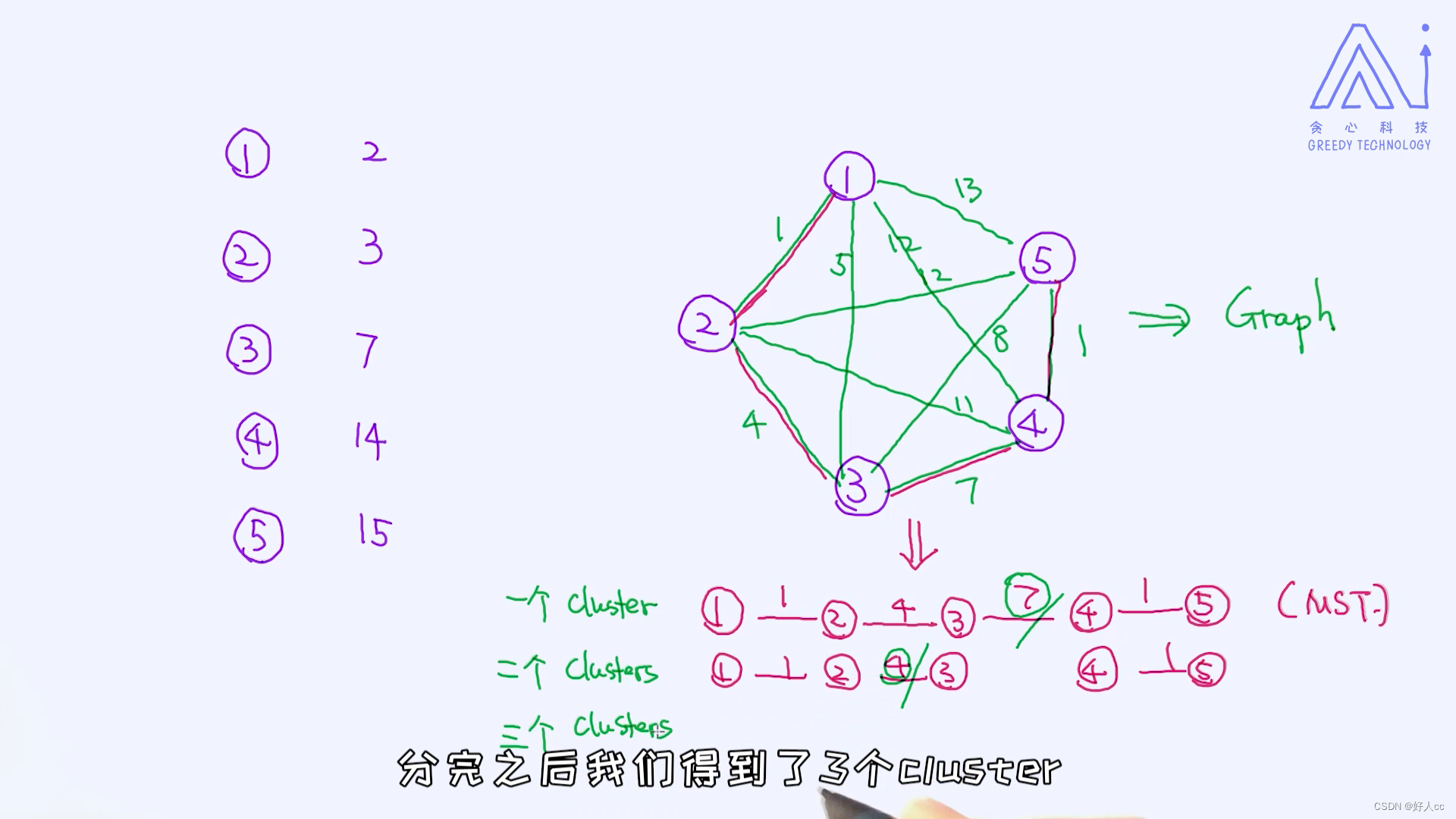
把最大的砍掉。