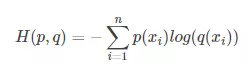参考http://blog.sina.com.cn/s/blog_65c8baf901016flh.html
用途:聚类算法中评估判断簇的个数是否合适(用来选择k)
原理:计算所有簇的类内距离和类间距离的比值(类内/类间),比值越小越好。即希望类间距离越大,类内距离越小(数据越集中)越好
公式:
(1)分散度(类内距离)Si:表示第i个类中,度量数据点的分散程度
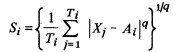
(2)类间距离Mij:表示第i类中心与第j类中心的距离
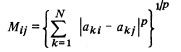
(3)两类的相似度:其实就是分散度/类间距离
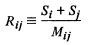
越分散,类间距离越小,相似度越大
(4)每个类找与它最相似的类的相似度作为其权重,所有相似度加和求平均
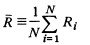
总的来说,这个DBI就是计算类内距离之和与类外距离之比,来优化k值的选择,避免K-means算法中由于只计算目标函数Wn而导致局部最优的情况。