密度聚类是一种无需预先指定聚类数量的聚类方法,它依赖于数据点之间的密度关系来自动识别聚类结构。
本文中,演示如何使用密度聚类算法,具体是DBSCAN(Density-Based Spatial Clustering of Applications with Noise)来对一个实际的数据集进行聚类分析。
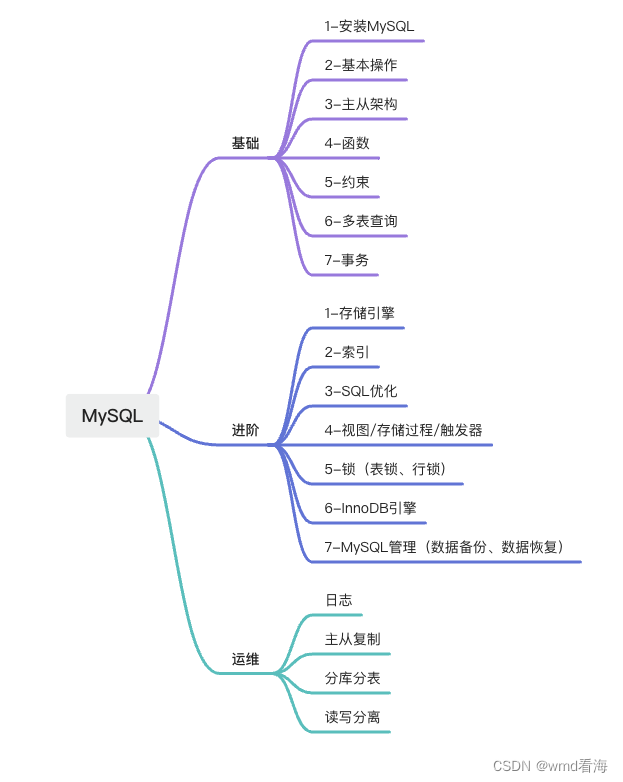
一、基本介绍
密度聚类的核心思想是将数据点分为高密度区域和低密度区域。高密度区域内的数据点被认为属于同一簇,而低密度区域的数据点被视为噪声或离群点。
核心点(Core Point):在半径ε内至少包含MinPts个数据点的数据点被称为核心点。
边界点(Border Point):在半径ε内包含少于MinPts个数据点但位于核心点邻域内的数据点被称为边界点。
噪声点(Noise Point):既不是核心点也不是边界点的数据点被称为噪声点。
DBSCAN算法的主要步骤如下:
1、从数据集中选择一个未被访问的数据点。
2、如果该数据点是核心点,则以该点为种子开始构建一个聚类簇。
3、通过扩展核心点的邻域,将相邻的核心点和边界点加入到聚类簇中。
4、重复步骤1-3,直到没有更多的核心点可以被添加到聚类簇中。
5、转到下一个未被访问的数据点,重复上述过程,直到所有数据点都被访问。
二、 模型原理
DBSCAN使用两个参数来定义聚类的性质:半径(ε)和最小数据点数(MinPts)。
ε(epsilon):半径参数定义了一个数据点的邻域范围。数据点在ε半径范围内的其他数据点将被认为是其邻居。
MinPts:最小数据点数参数定义了一个核心点所需的邻居数量。如果一个数据点拥有至少MinPts个邻居,它将被视为核心点。
DBSCAN将数据点分为三个类别:核心点、边界点和噪声点,根据以下公式:
核心点:如果数据点p在半径ε内至少有MinPts个数据点,即N§ >= MinPts,其中N§表示p的邻居数量。
边界点:如果数据点q在半径ε内包含少于MinPts个数据点,但位于某个核心点的半径ε内,即N(q) < MinPts 且q至少属于某个核心点的邻域。
噪声点:既不是核心点也不是边界点的数据点。
源码设计
本案例使用Python和Scikit-Learn库来对一个示例数据集进行DBSCAN聚类分析。
使用一个模拟的数据集并设置适当的参数。
-
导入所需的库
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt -
生成示例数据集
np.random.seed(0)
X = np.random.randn(300, 2) -
训练DBSCAN模型
dbscan = DBSCAN(eps=0.3, min_samples=5)
labels = dbscan.fit_predict(X)
现在,让我们使用Matplotlib来可视化DBSCAN的聚类结果。
把核心点、边界点和噪声点分别用不同的颜色标记。
- 绘制聚类结果
python">core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[dbscan.core_sample_indices_] = True
- 噪声点为-1,簇标记从0开始
n_clusters = len(set(labels)) - (1 if -1 in labels else 0)
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# 噪声点为黑色
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title(f'Estimated number of clusters: {n_clusters}')
plt.show()
上述代码将生成一个可视化图形,其中不同的颜色代表不同的聚类簇,黑色点代表噪声点。
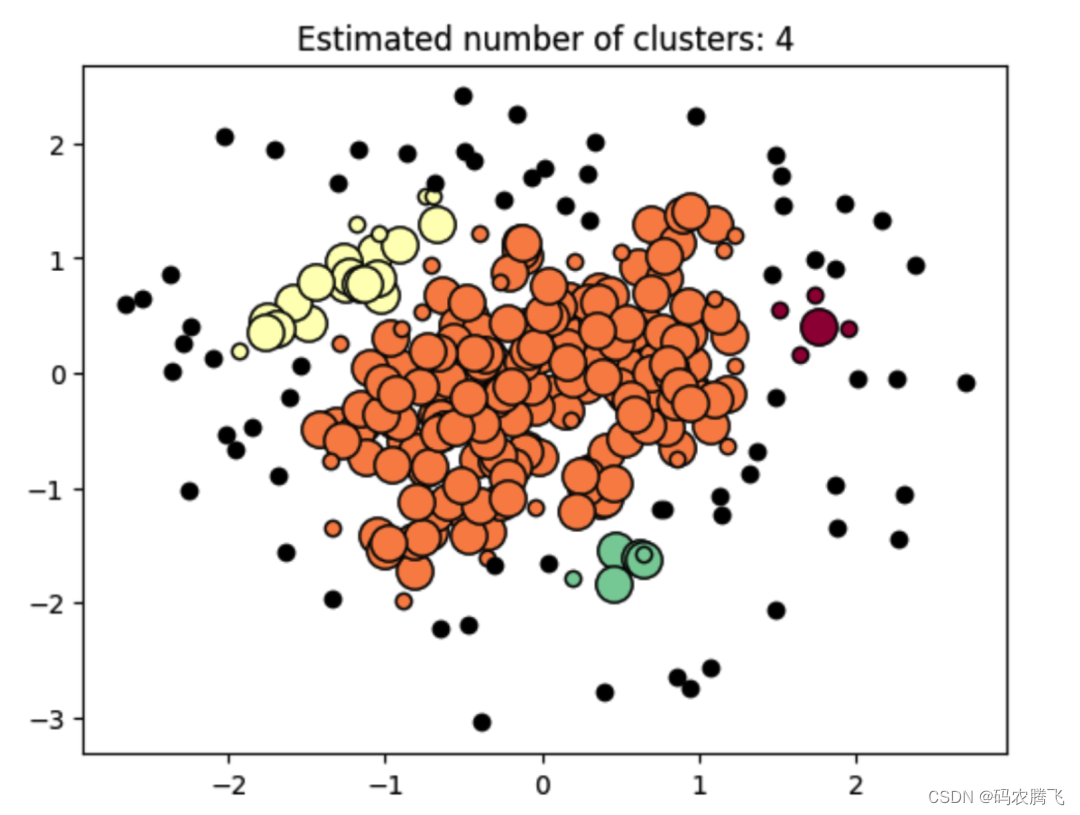
通过密度聚类,DBSCAN可以自动发现聚类的形状和大小,而不需要预先指定簇的数量。这使得DBSCAN在处理各种实际应用中非常有用,如异常检测、图像分割和地理空间分析。
这个例子提供了一个完整的密度聚类实际案例,包括了原理、公式解释、模型训练和可视化结果。密度聚类是一个强大的工具,适用于多种领域的数据分析和挖掘任务。