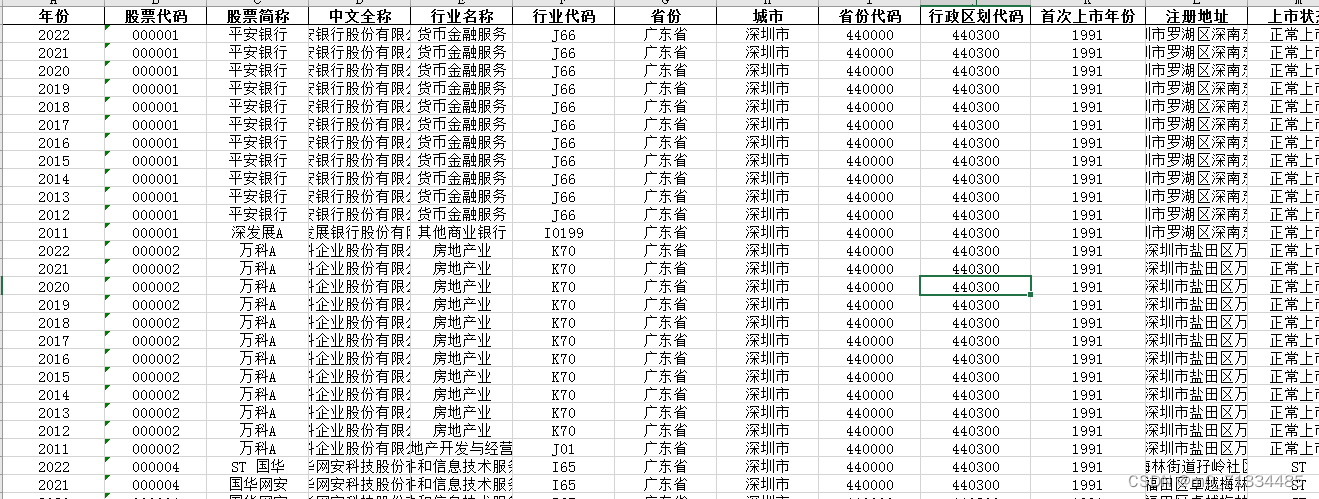
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。
有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每种算法的不同配置。在本教程中,你将发现如何在 python 中安装和使用顶级聚类算法。
学习完本文后,你将获取如下知识:
1、聚类是在输入数据的特征空间中查找自然组的无监督问题。
2、对于所有数据集,有许多不同的聚类算法和单一的最佳方法。
3、在 scikit-learn 机器学习库的 Python 中如何实现、适配和使用顶级聚类算法。
一、聚类
聚类分析,即聚类,是一项无监督的机器学习任务。它包括自动发现数据中的自然分组。与监督学习(类似预测建模)不同,聚类算法只解释输入数据,并在特征空间中找到自然组或群集。
群集通常是特征空间中的密度区域,其中来自域的示例(观测或数据行)比其他群集更接近群集。群集可以具有作为样本或点特征空间的中心(质心),并且可以具有边界或范围。
聚类可以作为数据分析活动提供帮助,以便了解更多关于问题域的信息,即所谓的模式发现或知识发现。例如:
1、该进化树可以被认为是人工聚类分析的结果;
2、将正常数据与异常值或异常分开可能会被认为是聚类问题;
3、根据自然行为将集群分开是一个集群问题,称为市场细分。
聚类还可用作特征工程的类型,其中现有的和新的示例可被映射并标记为属于数据中所标识的群集之一。虽然确实存在许多特定于群集的定量措施,但是对所识别的群集的评估是主观的,并且可能需要领域专家。通常,聚类算法在人工合成数据集