当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况:
数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。
1. Deep Multi network Embedded Clustering
Applied Intelligence
主要提出使用 DEC(deep Embed clutering ) 深度编码聚类的 方法,对特征进行聚类;
在此基础上加上了几个 多视图的特征;
2. Deep convolutional self-paced clustering
本文中主要用到的研究方法有:
- 无监督聚类;
- 自步学习方式, 将样本从简单到困难的学习方式;
2.1 存在问题与提出的解决方法
2.1.1 存在问题
当数据点均匀地分布在特征空间中相应的质心周围时,Kmeans算法非常有效。然而,K-means通常不适用于高维数据,因为“维数诅咒”造成的相似度度量效率低下。
2.1.2 解决方法
论文的主要贡献:
具体而言,
-
在预训练阶段,我们提出利用卷积自动编码器来提取包含空间相关信息的高质量数据表示。
-
然后,在精调阶段,直接对学习到的特征施加聚类损失,共同进行特征细化和聚类分配。我们保留解码器,以避免特征空间因聚类损失而被扭曲。
-
为了稳定整个网络的训练过程,我们进一步引入了自步长学习机制,并在每次迭代中选择最自信的样本。通过对7个流行图像数据集的综合实验,我们证明了所提出的算法可以持续地超过最先进的竞争对手。
前两个表明, 将特征学习与聚类过程 作为互相辅助的过程,
第三点使用自步 学习的方式,优化过程中样本由易到难,边际样本的不利影响可以得到有效的缓解。 是为了降低不可靠的样本会混淆甚至误导DNN的训练过程,从而严重降低聚类性能。
简单说来, 使用卷积提取特征; 然后对特征进行聚类; 3. 并且在训练过程中,引入自步学习步长机制, 每次迭代过程中选择,最自信的样本;
2.2 实现方法
具体来说,我们的方法包含两个阶段:预训练和微调。
-
在预训练阶段,我们通过最小化重构损失来训练卷积自动编码器 (convolutional autoencoder, CAE) [26]通过使用 CAE,我们的方法可以将数据从一个相对高维和稀疏的空间转换为一个低维和紧凑的空间。
-
,在微调阶段,不同于以往的一些作品[31,32,37]只保留编码器,我们通过使用聚类损失和重构损失对整个自动编码器(即CAE)进行调优,这样可以保留数据属性,避免特征空间的破坏。
- 问题: 代过程中选择,最自信的样本, 那么如何知道哪些样本的可信度高;
3. 多视图表示学习
4. 聚类方法
采用几种聚类方法与DCSPC方法进行比较,大致可分为三类:
-
1)传统方法,包括Kmeans (KM)[5]、高斯混合模型(GMM)[6]和谱聚类(SC) [7];
-
2)基于表示的方法,包括SAE[25]和CAE[26];
-
3)深度聚类方法,由深度嵌入聚类组成(DEC)[32]、改进深度嵌入聚类(IDEC)[33]、深度嵌入网络(DCN)[34]、深度K-means (DKM)[35]、卷积深度嵌入聚类(ConvDEC)[36]、自适应自步调聚类(ASPC)[37]、结构深度嵌入网络(SDCN)[38]、半监督深度嵌入聚类(SDEC)[39]、DDC (deep density-based clustering)[40]
4.1 K means 聚类
当数据点均匀地分布在特征空间中相应的质心周围时,Kmeans算法非常有效。然而,K-means通常不适用于高维数据,因为“维数诅咒”造成的相似度度量效率低下。因此,在实际应用中,我们应该使用降维方法,如PCA[8]、MDS[9]、NMF[10]等,将原始数据投影到低维空间,然后使用K-means算法对低维数据进行聚类,通常会得到更好的结果。除上述线性降维方法外,非线性算法如tSNE[17]、LLE[18]和基于dnn的方法[19-21]被广泛应用于Kmeans算法前的预处理。有兴趣的读者可参考[22-24]进行全面了解。在许多实际应用中,数据可能来自不同的视图,因此,许多多视图聚类方法被提出。例如,Zhang et al.[13]先将多视图样本映射到共享视图空间,然后将样本转换到判别空间,最后对转换后的样本进行K-means聚类。Wang et al.[14]提出了一种通用的基于图的多视图聚类框架,该框架通过提取多视图的特征矩阵,融合图矩阵,生成统一的图矩阵进行直接聚类。考虑到训练数据中可能存在特定类不存在的情况,Hayashi et al.[16]提出了一种基于聚类的零射击学习方法,将数据分为不可见类和可见类。
4.2 无监督聚类
深度无监督聚类方法大致可分为两类。一类是通常独立对待特征学习或聚类的方法,即先将原始数据投射到一个低维的特征空间中,然后用常规的聚类算法对特征点进行分组。不幸的是,这种分离的形式会对集群性能造成限制,因为忽略了这一点特征学习和聚类之间的一些潜在关系。
另一类是使用联合优化准则的方法,它同时进行特征学习和聚类,比分离的方法有很大的优越性。最近,人们提出了几种方法来将特征学习和聚类集成到一个统一的框架中。联合无监督学习(Joint unsupervised learning, JULE)[29]提出在统一加权三态损失的基础上,同时引导聚类和表示学习,但计算复杂度较高。Chang et al.[30]提出了成对图像之间二值关系的假设,并开发了深度自适应聚类(deep adaptive clustering, DAC)模型,将聚类任务重新建立为二值两两分类问题,在6个图像数据集上显示出良好的结果。自适应自定步长聚类(ASPC)[37]借鉴硬加权自定步长学习方法,在聚类网络训练时优先考虑高置信度样本,以消除边际样本的负面影响,稳定训练过程。Ren et al.[40]提出了一种基于深度密度的聚类(DDC)技术,该技术可以自适应估计任意形状的数据聚类数量。基于数据增强的深度嵌入聚类(Deep embedded clustering with data augmentation, DECDA)[36]将数据增强技巧引入到原始的深度嵌入聚类框架中,并在4个灰度图像数据集上取得了良好的聚类性能。半监督深度嵌入聚类(semi - supervised deep embedded clustering, SDEC)[39]克服了DEC[32]不能利用先验知识指导训练过程的缺点。
deep adaptive clustering, DAC 模型: Chang J, Wang L, Meng G, Xiang S, Pan C (2017) Deep adaptive
image clustering. In: International Conference on Computer
Vision, pp 5880–5888
https://github.com/vector-1127/DAC
自适应自定步长聚类(ASPC)[37]借鉴硬加权自定步长学习方法,Guo X, Liu X, Zhu E, Zhu X, Li M, Xu X, Yin J (2020) Adaptive
self-paced deep clustering with data augmentation. IEEE Trans Knowl Data Eng
https://github.com/XifengGuo/ASPC-DA;
半监督深度嵌入聚类(semi - supervised deep embedded clustering, SDEC) Ren Y, Hu K, Dai X, Pan L, Hoi SCH, Xu Z (2019) Semi- supervised deep embedded clustering. Neurocomputing 325:121–
130
https://github.com/yongzx/SDEC-Keras;
5. 自步学习
与课程学习[43]的核心思想相似,self-pace learning的目标是学习一个模型,由易到难,逐步引入样本进行训练。这两种方法之间的明显区别是,前者需要预先确定简单和困难的样本,而后者可以自动从数据本身选择顺序。给定一个训练集X ={(x1, y1), (x2, y2),…,(xn, yn)}和以θ为模型参数的训练模型fθ,则自步学习的总体目标可表示为:
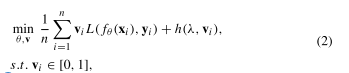
其中,L(·)表示特定问题的损失函数,h(λ, vi)表示独立于L(·)的自步长正则化器,可以以多种形式定义,
V =[v1, v2,…], vn] T代表反映样本复杂性的权重变量,λ是一个参数,称为学习速度,用于控制“模型年龄”,该年龄逐渐增加,以探索更多的样本。当h(λ, vi) =−λvi且vi等于0或1时,自定步学习退化为硬加权形式,即:

另外,对于用固定的v更新θ,问题(3)退化为加权损失最小化问题,该问题可以通过随机梯度下降(SGD)和反向传播(BP)很容易解决。
到目前为止,自定进度学习已被应用于各种任务和模型。Kumar等人的[44]首次证明了一种自定步学习算法在学习潜在结构支持向量机方面的性能优于目前最先进的方法。在[45]中,成功地将自定步长学习范式应用于时间序列的聚类。 Tang Y, Xie Y, Yang X, Niu J, Zhang W (2021) Tensor multi-
elastic kernel self-paced learning for time series clustering. IEEE
Trans Knowl Data Eng 33(3):1223–1237;
Jiang et al.[46]提出了一种自定进度课程学习(self-pace curriculum learning, SPCL)框架,该框架能够联合考虑先验知识和学习进度。为了同时增强有监督学习的鲁棒性和有效性,[47]等人首先提出了自步速boost learning (SPBL)框架,该框架能够揭示和利用boost与自步速学习的关联。Ren et al.[48]注意到标准的自进度学习可能存在类不平衡问题,通过为每个类分配权重和局部选择实例,精心设计了两种新的软加权方案来弥补这一问题。最近,SPUDRFs[49]在公平性方面解决了自进度学习中的排序和选择的基本问题,并可以方便地与各种深度判别模型结合。在SAMVC[50]中,在多视图聚类模型中引入一种软加权自步长学习形式,以减少离群值和噪声的不利影响,并提出一种自加权策略来判断不同视图的重要性。孟等人的[51]设法提供了一些自我节奏学习范式的解释,以追求理论理解。总的来说,这些文献出版物证实了自节奏学习有助于避免陷入不希望出现的局部最小值,并总体上改善模型的性能。