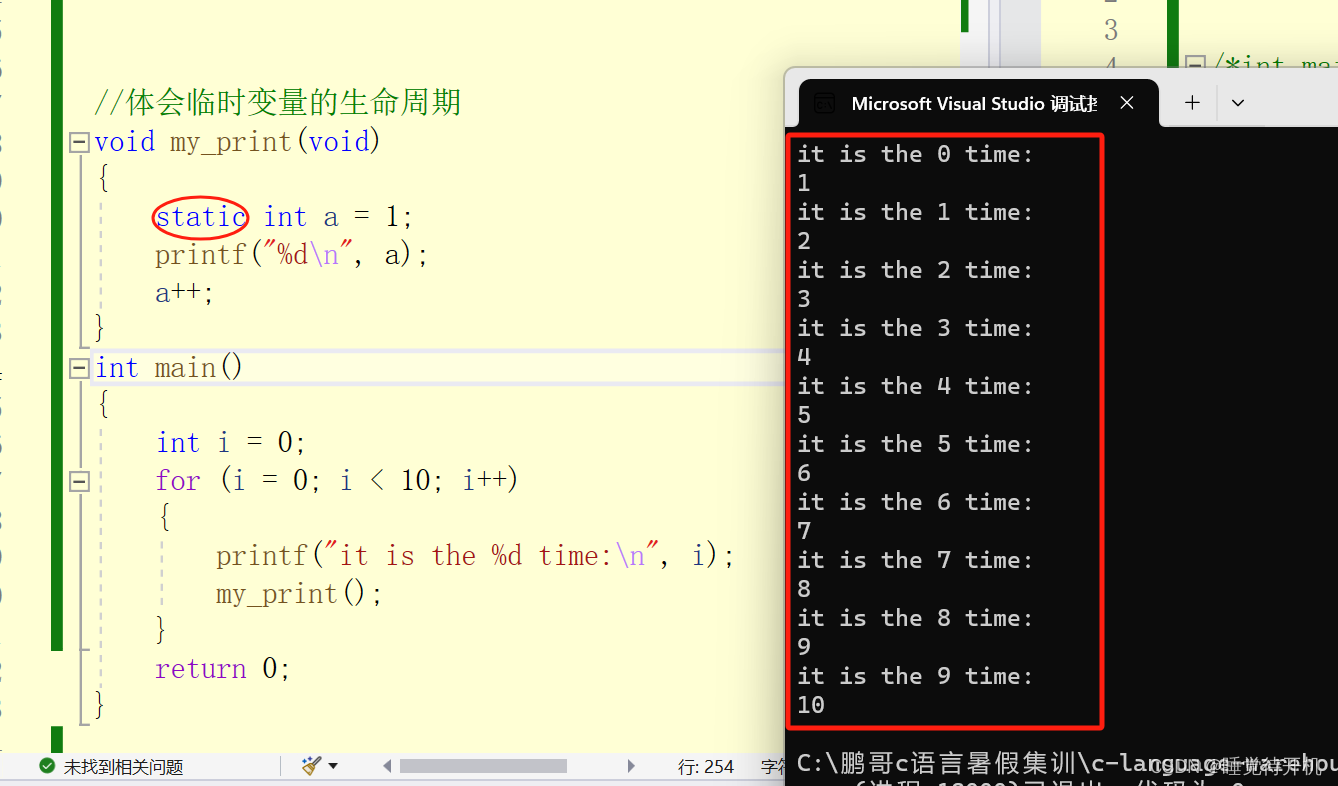
在本篇博客中,我们将深入探讨凝聚层次聚类(Agglomerative Hierarchical Clustering)和DBscan算法,并通过Python实例演示它们的应用。这两种算法都属于聚类算法的范畴,用于将数据点划分为不同的簇。

凝聚层次聚类
凝聚层次聚类是一种层次化的聚类方法,其主要思想是将每个数据点视为一个初始簇,然后逐步合并相邻的簇,直到满足停止条件。以下是一个简单的Python实例,演示了如何使用凝聚层次聚类对随机生成的点进行聚类:
python">import math
import random
import pylab
class Point:
__slots__ = ["x", "y", "group"]
def __init__(self, x=0, y=0, group=0):
self.x, self.y, self.group = x, y, group
# 生成随机数据点
def generatePoints(pointsNumber, radius):
points = [Point() for _ in range(4 * pointsNumber)]
originX = [-radius, -radius, radius, radius]
originY = [-radius, radius, -radius, radius]
count = 0
countCenter = 0
for index, point in enumerate(points):
count += 1
r = random.random() * radius
angle = random.random() * 2 * math.pi
point.x = r * math.cos(angle) + originX[countCenter]
point.y = r * math.sin(angle) + originY[countCenter]
point.group = index
if count >= pointsNumber * (countCenter + 1):
countCenter += 1
return points
# 计算两点间的欧氏距离
def solveDistanceBetweenPoints(pointA, pointB):
return (pointA.x - pointB.x) ** 2 + (pointA.y - pointB.y) ** 2
# 获取距离映射
def getDistanceMap(points):
distanceMap = {}
for i in range(len(points)):
for j in range(i + 1, len(points)):
distanceMap[str(i) + '#' + str(j)] = solveDistanceBetweenPoints(points[i], points[j])
distanceMap = sorted(distanceMap.items(), key=lambda dist:dist[1], reverse=False)
return distanceMap
# 凝聚层次聚类算法
def agglomerativeHierarchicalClustering(points, distanceMap, mergeRatio, clusterCenterNumber):
unsortedGroup = {index: 1 for index in range(len(points))}
for key, _ in distanceMap:
lowIndex, highIndex = int(key.split('#')[0]), int(key.split('#')[1])
if points[lowIndex].group != points[highIndex].group:
lowGroupIndex = points[lowIndex].group
highGroupIndex = points[highIndex].group
unsortedGroup[lowGroupIndex] += unsortedGroup[highGroupIndex]
del unsortedGroup[highGroupIndex]
for point in points:
if point.group == highGroupIndex:
point.group = lowGroupIndex
if len(unsortedGroup) <= int(len(points) * mergeRatio):
break
sortedGroup = sorted(unsortedGroup.items(), key=lambda group: group[1], reverse=True)
topClusterCenterCount = 0
for key, _ in sortedGroup:
topClusterCenterCount += 1
for point in points:
if point.group == key:
point.group = -1 * topClusterCenterCount
if topClusterCenterCount >= clusterCenterNumber:
break
return points
# 可视化聚类结果
def showClusterAnalysisResults(points):
colorStore = ['or', 'og', 'ob', 'oc', 'om', 'oy', 'ok']
pylab.figure(figsize=(9, 9), dpi=80)
for point in points:
color = ''
if point.group < 0:
color = colorStore[-1 * point.group - 1]
else:
color = colorStore[-1]
pylab.plot(point.x, point.y, color)
pylab.show()
# 主函数
def main():
clusterCenterNumber = 4
pointsNumber = 500
radius = 10
mergeRatio = 0.025
points = generatePoints(pointsNumber, radius)
distanceMap = getDistanceMap(points)
points = agglomerativeHierarchicalClustering(points, distanceMap, mergeRatio, clusterCenterNumber)
showClusterAnalysisResults(points)
main()
在这个例子中,我们首先生成了一个包含随机数据点的数据集,然后使用凝聚层次聚类算法对这些点进行聚类。通过调整参数,如clusterCenterNumber、pointsNumber等,我们可以观察到不同的聚类效果。最终,我们通过可视化展示了聚类的结果。
DBscan算法
DBscan(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,具有排除噪声点的优势。该算法通过定义密度的概念,将数据点划分为核心点、边界点和噪声点。以下是DBscan算法的Python实例:
python"># 代码部分略,详见前文提供的Python代码
在DBscan算法中,我们需要设置参数,如Eps(领域半径)和minPointsNumberWithinBoundary(边界点最小邻居数)。通过调整这些参数,我们可以对数据点进行不同粒度和范围的聚类,以满足具体问题的要求。
实例演示
在博客的最后,我们通过实例演示了凝聚层次聚类和DBscan算法在随机点集上的应用,通过可视化的方式展示了聚类的效果。读者可以通过运行这些代码,并自行调整参数,深入理解这两种聚类算法的工作原理。
通过本篇博客,读者可以学到如何使用Python实现凝聚层次
聚类和DBscan算法,并了解如何通过调整参数优化聚类效果。这两种算法在不同场景下具有广泛的应用,是聚类分析中重要的工具。希望本文对大家学习聚类算法有所帮助。