文章目录
- 前言
- 一、原理
- 前置知识点
- Mean Shift计算步骤
- 二、应用举例-图像分割
- 三、聚类实战-简单实例
- bandwidth=1
- bandwidth=2
- 总结
前言
Mean Shift(均值漂移)是基于密度的非参数聚类算法,其算法思想是假设不同簇类的数据集符合不同的概率密度分布,找到任一样本点密度增大的最快方向(最快方向的含义就是Mean Shift),样本密度高的区域对应于该分布的最大值,这些样本点最终会在局部密度最大值收敛,且收敛到相同局部最大值的点被认为是同一簇类的成员。
Mean Shift在计算机视觉领域的应用非常广,如图像分割,聚类和视频跟踪等。
一、原理
前置知识点
- 核密度估计: Mean-shift的核心思想是通过估计数据点分布的概率密度函数来发现数据集的聚类结构。它使用核函数(通常是高斯核函数)来对每个数据点的周围区域进行加权,得到一个局部密度估计。
对于每一个数据点 x i x_i xi,其邻域内点密度计算公式如下:
其中,K是高斯核函数,h是带宽参数,n是数据集的大小,d是数据点的维数
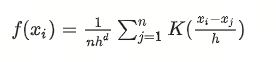
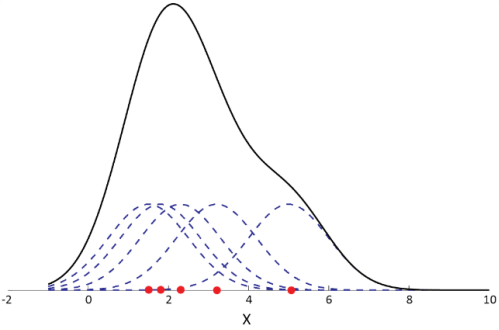
下图是一维数据集的核概率密度,其中虚线表示每个样本的核函数,实线是每个样本的核函数进行叠加,表示数据集的概率密度。该数据集的概率密度只有一个局部最大值,因此,此时mean shift算法的簇类个数是1。
ps:
数据集密度函数如下:
对数据集密度函数求导:
其中, g ( s ) = − k ′ ( s ) g(s)=-k'(s) g(s)=−k′(s)
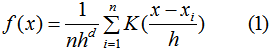
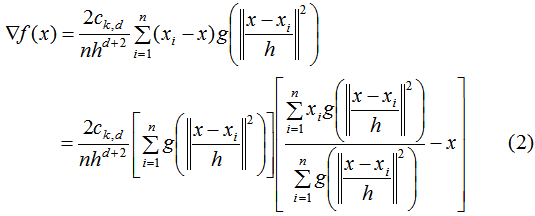
- 迭代过程: 算法通过不断迭代的方式更新每个数据点的位置,直到收敛到一个局部极值点。具体而言,对于每个数据点,通过计算其周围区域内的梯度方向,将点沿梯度方向移动一定的步长。这个步长通常由算法自适应确定。
ps:
公式(2)的第一项为实数值,因此第二项的向量方向与梯度方向一致,得到均值漂移向量(均值漂移向量所指的方向是密度增加最大的方向):
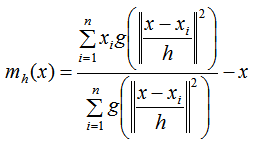
-
收敛条件: 迭代过程的收敛条件通常是梯度变为零或变得足够小。当梯度接近零时,说明数据点已经移动到密度估计的峰值位置,此时算法认为达到了聚类中心。
-
聚类结果: 最终,所有数据点都会收敛到密度估计的峰值位置,形成聚类。如果多个数据点收敛到相同的峰值,它们被认为属于同一个聚类。
Mean Shift计算步骤
- (1)计算每个样本的均值漂移向量: m h ( x i ) m_h(x_i) mh(xi)
- (2)对每个样本进行平移: x i = x i + m h ( x i ) x_i=x_i+m_h(x_i) xi=xi+mh(xi)
- (3)重复步骤(1)(2),直到样本点收敛,即 m h ( x i ) = 0 m_h(x_i)=0 mh(xi)=0
- (4)收敛到相同点的样本被认为是同一簇类的成员
二、应用举例-图像分割
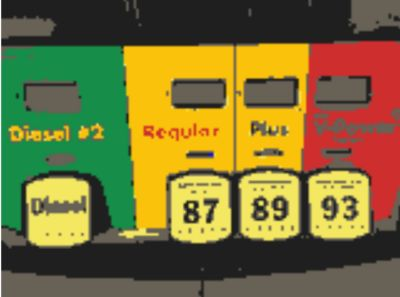
对下图进行图像分割

将数据映射到RGB三维空间:

运行mean shift算法,使用带宽为25的高斯核,下图展示了每个样本收敛到局部最大核密度的过程:
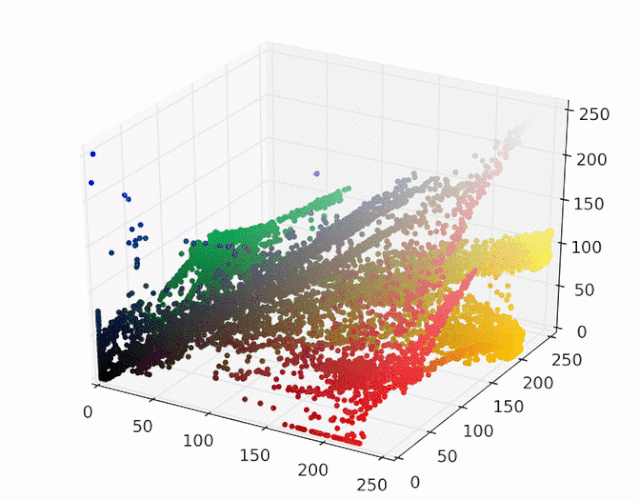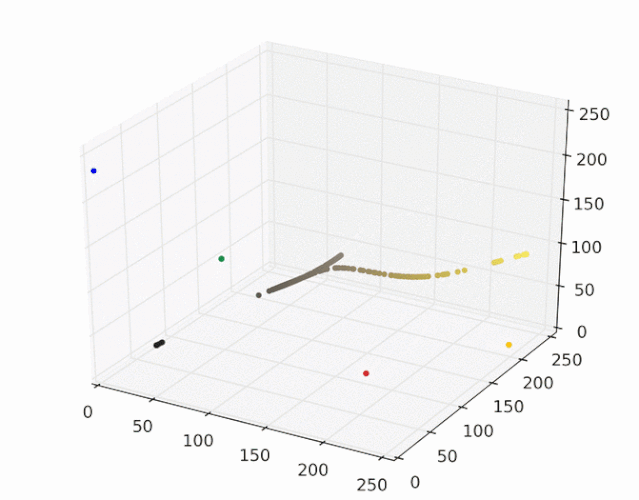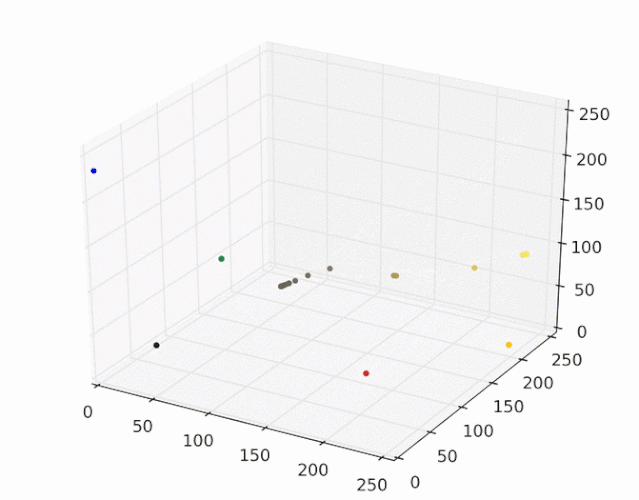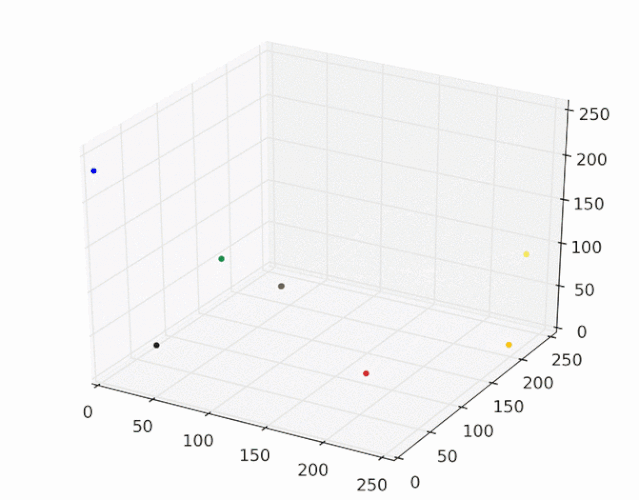
每个样本点最终会移动到核概率密度的峰值,移动到相同峰值的样本点属于同一种颜色,图像分割结果如下图所示:
三、聚类实战-简单实例
python">from sklearn.cluster import MeanShift
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=1.0, random_state=42)
# 创建Mean Shift模型并拟合数据
bandwidth = 1 # 设置带宽,需要根据数据特点调整
bin_seeding = True # 是否使用直方图种子来初始化均值漂移,它可以加快收敛速度,默认True
ms = MeanShift(bandwidth=bandwidth, bin_seeding=bin_seeding)
ms.fit(X)
# 获取聚类结果
labels = ms.labels_
cluster_centers = ms.cluster_centers_
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1,], marker='o', s=100, color='red')
plt.show()
重要参数:bandwidth,需要根据数据特点调整,如下所示:
ps:如果带宽参数过小,会导致聚类中心过多,如果带宽参数过大,会导致聚类中心过少。因此,在实际应用中,我们需要通过交叉验证等方法来确定带宽参数的取值。
bandwidth=1
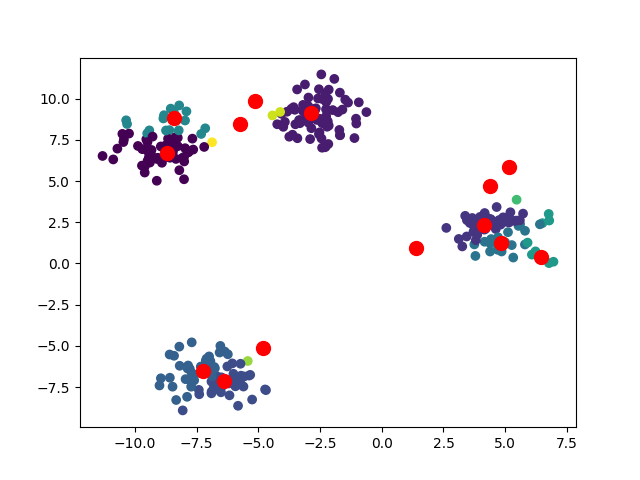
bandwidth=2
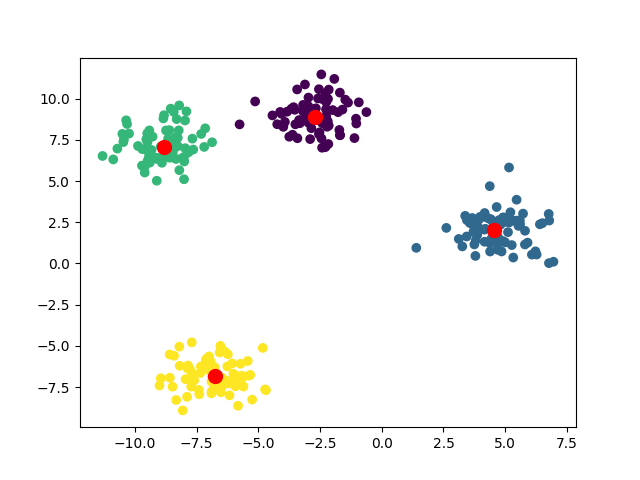
总结
优点:
- 不需要设置簇类的个数,自动发现潜在的聚类中心,对于高维度和非线性分布的数据集也有很好的适应性
- 可以处理任意形状的簇类
- 参数少,算法只需设置带宽这一个参数,带宽影响数据集的核密度估计
- 算法结果稳定,不需要进行类似K均值的样本初始化
缺点:
- 聚类结果取决于带宽的设置,带宽设置的太小,收敛太慢,簇类个数过多;带宽设置的太大,一些簇类可能会丢失。
- 对于较大的特征空间,计算量非常大。