简介
使用sklearn基于TF_IDF算法,实现把文本变成向量。再使用sklearn的kmeans聚类算法进行文本聚类。
个人观点:这是比较古老的技术了,文本转向量的效果不如如今的 text2vec 文本转向量好。
而且sklearn 不支持GPU加速,处理大量数据速度极慢。
实现
项目完整可运行代码:https://github.com/JieShenAI/csdn/blob/main/machine_learning/TF-IDF%20sklearn聚类.ipynb
import re
import random
import jieba
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfTransformer, TfidfVectorizer
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import gensim
from gensim.models import Word2Vec
from sklearn.preprocessing import scale
import multiprocessing
语料库如下
corpus = [
'花呗更改绑定银行卡',
'我什么时候开通了花呗',
'A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.'
]
jieba 分词
jieba.add_word("花呗"),给jieba添加花呗, 不然 jieba 会把花呗拆分成'花', '呗'。
分词模型,用起来还是有点麻烦
jieba.add_word("花呗")
def preprocess_text(content_lines, sentences):
for line in content_lines:
try:
segs=jieba.lcut(line)
segs = [v for v in segs if not str(v).isdigit()]#去数字
segs = list(filter(lambda x:x.strip(), segs)) #去左右空格
segs = list(filter(lambda x:len(x)>1, segs)) #长度为1的字符
# segs = list(filter(lambda x:x not in stopwords, segs)) #去掉停用词
sentences.append(" ".join(segs))
except Exception:
print(line)
continue
sentences = []
# 处理语料,语料的处理结果存放在sentences
preprocess_text(corpus, sentences)
jieba 分词结果如下:
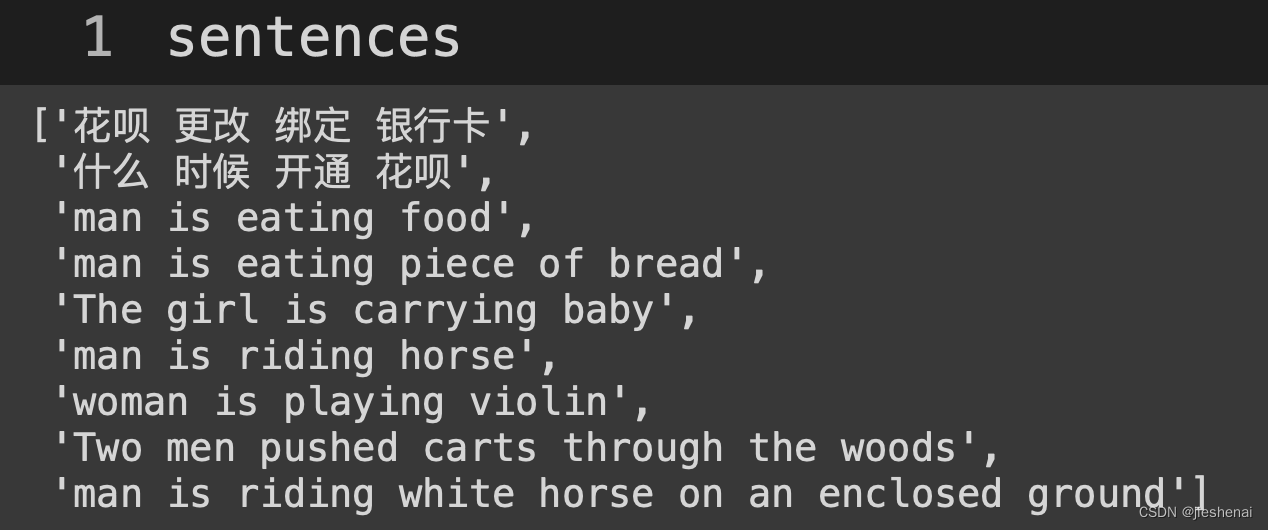
利用 TF_IDF 算法把分词结果转成向量
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5)
#统计每个词语的tf-idf权值
transformer = TfidfTransformer()
# 第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(sentences))
# 获取词袋模型中的所有词语
word = vectorizer.get_feature_names_out()
# 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
#查看特征大小
print ('Features length: ' + str(len(word)))
如下图所示,向量矩阵过于稀疏了,没有worc2vec编码的向量稠密。
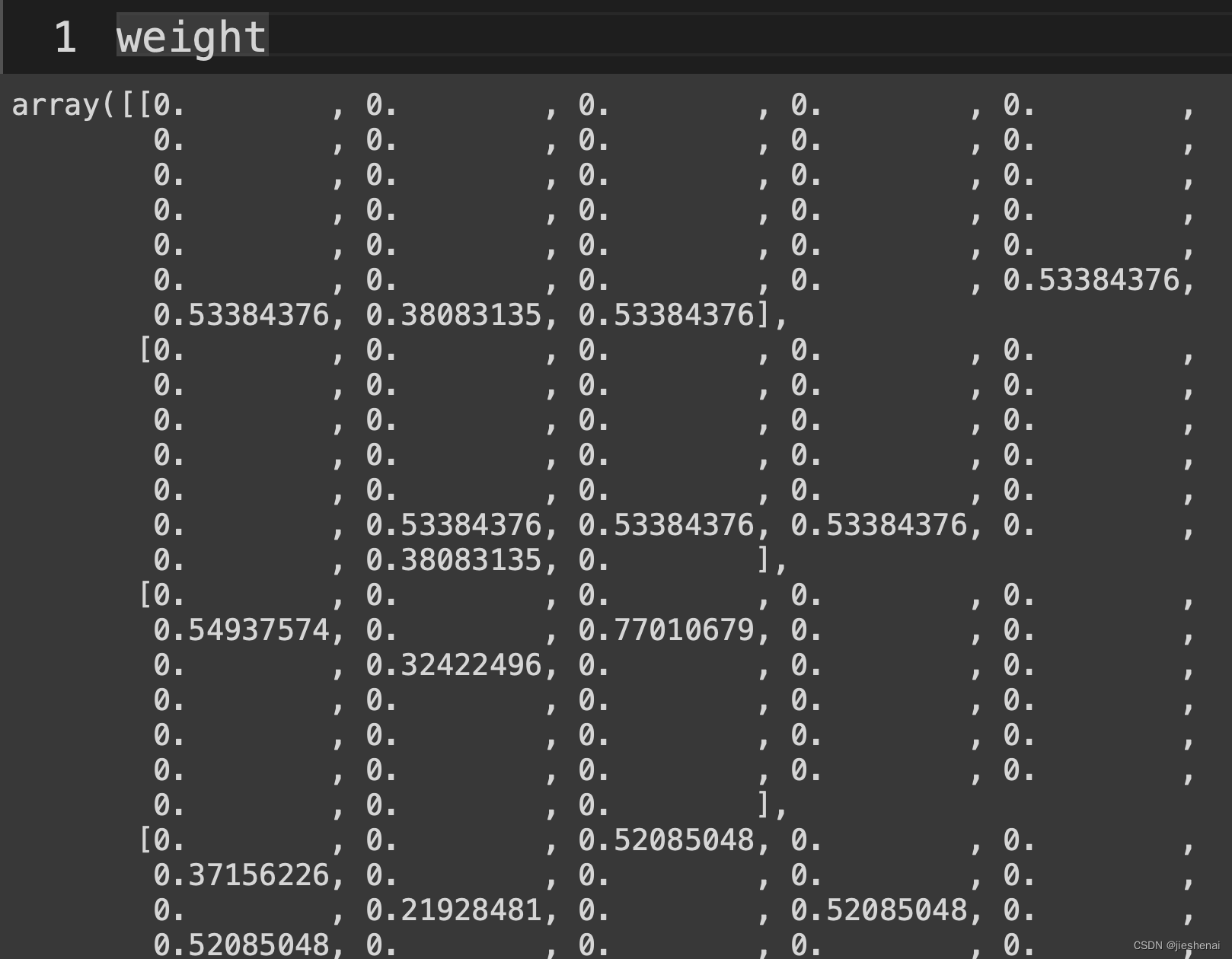
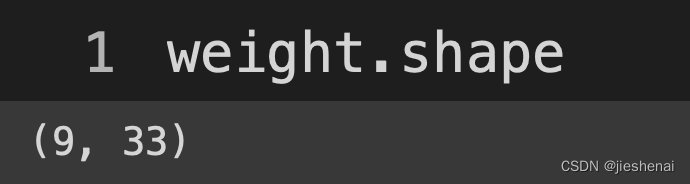
编码的向量是33纬;
模型
为了方便使用,在JieKmeans类中封装了,kmeans聚类训练、预测和绘图功能。
from sklearn.decomposition import PCA
class JieKmeans:
def __init__(self, numClass=4, n_components=10, func_type='PCA'):
#这里也可以选择随机初始化init="random"
self.PCA = PCA(n_components=n_components)
if func_type == 'PCA':
self.func_plot = PCA(n_components=2)
elif func_type == 'TSNE':
from sklearn.manifold import TSNE
self.func_plot = TSNE(2)
self.numClass = numClass
def plot_cluster(self, result, newData):
plt.figure(2)
Lab = [[] for i in range(self.numClass)]
index = 0
for labi in result:
Lab[labi].append(index)
index += 1
color = ['oy', 'ob', 'og', 'cs', 'ms', 'bs', 'ks', 'ys', 'yv', 'mv', 'bv', 'kv', 'gv', 'y^', 'm^', 'b^', 'k^',
'g^'] * 3
for i in range(self.numClass):
x1 = []
y1 = []
for ind1 in newData[Lab[i]]:
# print ind1
try:
y1.append(ind1[1])
x1.append(ind1[0])
except:
pass
plt.plot(x1, y1, color[i])
#绘制初始中心点
x1 = []
y1 = []
for ind1 in self.model.cluster_centers_:
try:
y1.append(ind1[1])
x1.append(ind1[0])
except:
pass
plt.plot(x1, y1, "rv") #绘制中心
plt.show()
def train(self, data):
tmp = self.PCA.fit_transform(data)
self.model = KMeans(
n_clusters=self.numClass,
max_iter=10000, init="k-means++", tol=1e-6)
s = self.model.fit(tmp)
print("聚类算法训练完成\n", s)
def predict(self, data):
t_data = self.PCA.fit_transform(data)
result = list(self.model.predict(t_data))
return result
def plot(self, weight):
t_data = self.PCA.fit_transform(weight)
result = list(self.model.predict(t_data))
plot_pos = self.func_plot.fit_transform(weight)
self.plot_cluster(result, plot_pos)
net = JieKmeans(
numClass=3, # 聚类类别
n_components=5,
func_type='PCA' # 绘图降纬方法
)
net.train(weight)
# net.plot(weight)
聚类可视化
net.plot(weight)
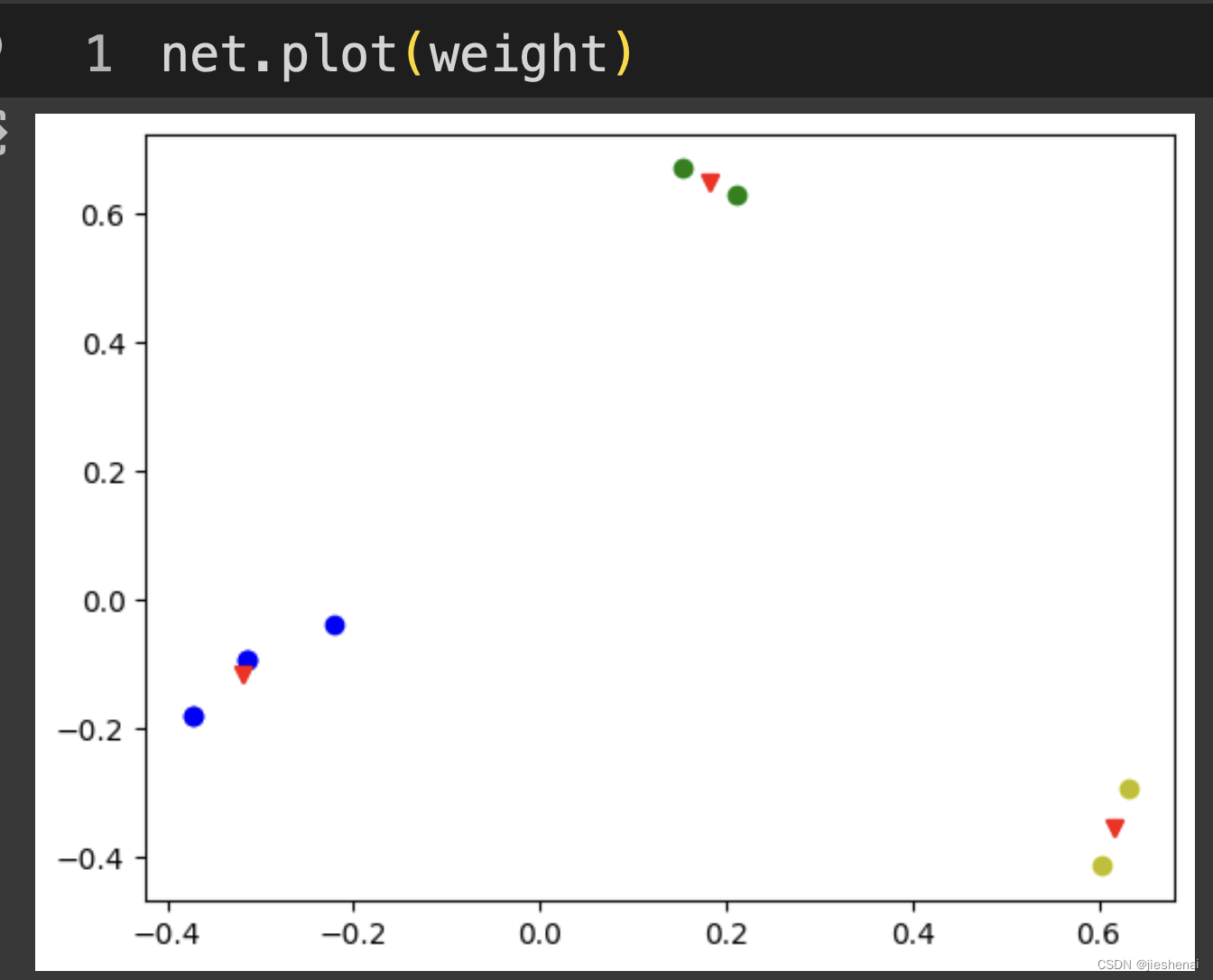
如上图所示,上图的可视化显示聚类效果很好,但是由于TF-IDF文本转向量的效果不是很好,所以上述聚类出来的结果可能并不是我们想要的。
预测结果:
p = net.predict(weight)
class_data = {
i:[]
for i in range(3)
}
for text,cls in zip(corpus, p):
class_data[cls.item()].append(text)
class_data
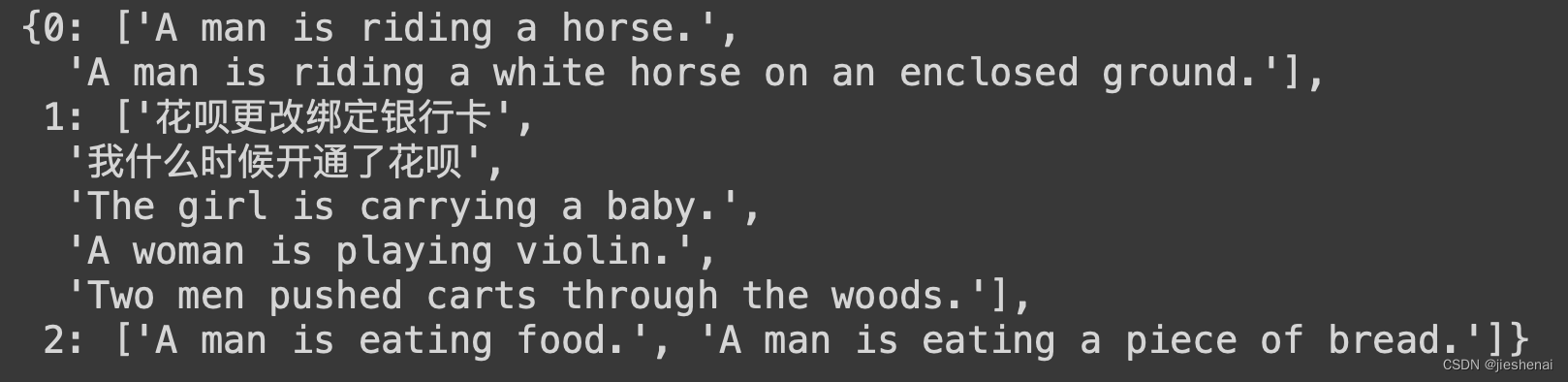
聚类结果如下:
进一步阅读
点击即可阅读,基于word2vec 和 kmeans_pytorch 的文件聚类实现,利用GPU加速提高聚类速度
该文使用text2vec通过cuda加速,加快文本转向量的速度。使用kmeans_pytorch包,基于pytorch在GPU上计算,提高聚类速度。
如下是其基于word2vec的聚类结果: