脑结构连接改变与精神分裂症(SZ)、双相情感障碍(BD)和重度抑郁障碍(MDD)等精神疾病的病理生理学有关。然而,目前尚不清楚这些连接异常中的哪一部分是疾病特有的,哪些是精神障碍和情感障碍的共同特征。本文基于大样本精神分裂症、双相情感障碍、重度抑郁患者和健康人群探讨了共同和特有的连接性改变。
结果表明,不同组在网络指标全局效率、聚类、当前边缘和全局连接强度方面存在显著差异,诊断之间的变化模式趋于一致。子网络分析揭示了所有三种障碍中受影响边缘的共同核心,但也揭示了障碍之间的差异。机器学习算法无法区分疾病,但可以区分每一种障碍和健康对照。此外,无论诊断如何,连接障碍模式在发病较早的患者中最为明显。本文发表在Biological Psychiatry杂志。
方法:这项研究分析了720名MDD患者、112名BD患者、69名SZ患者和842名健康对照(平均年龄:35.7岁)的基于扩散加权成像的结构性连接拓扑结构。采用图网络分析方法研究四组被试的连接组拓扑结构,并根据各组的结构连接矩阵采用机器学习算法对四组被试进行分类。
结果:不同组在网络指标全局效率、聚类、当前边缘和全局连接强度方面存在显著差异,诊断之间的变化模式趋于一致(例如,效率:HC>MDD>BD>SZ,pFDR=0.028)。子网络分析揭示了所有三种障碍中受影响边缘的共同核心,但也揭示了障碍之间的差异。机器学习算法无法区分疾病,但可以区分每一种障碍和健康对照。此外,无论诊断如何,连接障碍模式在发病较早的患者中最为明显。
结论:我们展示了SZ、BD和MDD的共同和特定的结构性白质连接障碍的特征,导致网络效率普遍降低。这些结果表明,在一系列主要的精神障碍中,大脑通信受到了损害。
引言
将重大精神疾病概念化为“连接障碍疾病”由来已久,包括从早期的精神病学研究到现代的微观和宏观神经科学的补充观点。神经成像技术提供了绘制人类连接组结构图并在体内检查结构连接复杂网络的可能性。在一系列条件下绘制大脑连通性的网络结构图可以分析基于图论的网络全局度量,例如效率、聚类系数和小世界属性,代表人脑的通信、分割和整合能力,以及大脑连通性结构如何与健康和疾病相关。
研究连接组结构中的变化有助于我们理解精神分裂症(SZ)、双相情感障碍(BD)和严重抑郁障碍(MDD)等一系列精神疾病中脑功能障碍的潜在机制。完整的脑白质连接促进了大脑的综合功能,而这种连接的中断使大脑网络容易受到神经和精神障碍的影响。使用网络科学来阐明这些疾病中结构性脑连接的变化已经取得了很好的进展。值得注意的是,研究不同条件下连接强度和网络组织的差异可以精确定位条件内和条件之间的具体解剖变化。
虽然SZ、BD和MDD在症状学上有所不同,在我们目前的诊断系统中被概念化为不同的疾病,但遗传学研究和临床表型分析指出了这些诊断之间相当大的重叠。先前对SZ、BD和MDD的连接组研究表明,连接性改变可能在这些疾病的病理生理学中发挥基础作用,但这些连接组研究通常一次只研究一种情况,因此未能阐明所报道的这些发现在多大程度上是特定的,或者它们是否有共同的基础机制。虽然所有研究在报告的全局图论指标上都是不同的,并选择性地聚焦在节点变化上,但在所有这些研究中,与健康对照相比,各种精神障碍中均出现了连接强度降低的模式(通过重建流线的数量来衡量)。只有很少的研究直接比较了几种疾病。虽然大多数样本量都不大,但最终的结果表明,精神分裂症患者存在最严重的连接性障碍,这些连接性变化可能与遗传易感性有关。
在目前的研究中,我们假设所有疾病的结构连接组的变化,并分析这些变化是特定精神疾病的神经生物学特征还是本质上的诊断异常。鉴别和分离基于疾病特有的连接组变化,对于诊断和预测精神疾病长期结果的生物标记物方面起着重要的推动作用。在横向分析中,我们分析和比较了SZ、BD、MDD和健康对照(HC)之间的结构连接组差异,并评估了结构连接性数据在疾病分类方面的预测作用。
材料和方法
数据获取和预处理
纳入的对象是马尔堡-明斯特情感障碍队列研究(MACS)的一部分。研究参与者的年龄在18岁到65岁之间,通过报纸广告和当地精神病院在两个地点(德国马尔堡和明斯特)招募。纳入的对象是马尔堡-明斯特情感障碍队列研究(MACS)的一部分。研究参与者的年龄在18岁到65岁之间,通过报纸广告和当地精神病院在两个地点(德国马尔堡和明斯特)招募。采用DSM-IV-TR结构性临床访谈(SCID-I)确定精神病终生诊断。所有的实验都是在道德准则和规定下进行的,所有参与者在检查前都给予了书面知情同意。这项分析采集了1776名参与者(马尔堡:351名MDD,60名BD,54名SZ,533名HC;明斯特:402名MDD,62名BD,17名SZ,336名HC)。
在位于两个地点的MACS研究中,两台3T西门子MR扫描仪用于数据采集(T1和弥散加权成像(DWI))。在所有分析中,扫描地点作为协变量包括在内。
我们使用公开可用的开源CATO工具箱进行数据预处理和解剖连接组重建。该过程包括以下步骤:对于DWI的预处理(使用FSL)和采用确定性跟踪术进行纤维束重建。随后,我们获得了每个参与者的114个大脑皮质区域(节点)以及这些大脑区域之间重建的白质流线(边缘)的网络。使用基于连续跟踪纤维分配(FACT)算法的确定性流线形成术重建网络边缘。选择了单张量重建和确定性跟踪算法,因为它在假阴性和假阳性纤维重建之间提供了合理的平衡。如果至少有三条重构的流线将两个节点(即大脑区域)之间的边连接在一起,以平衡得到的连接性矩阵的灵敏度和特异度,则将它们包括在内。每个受试者的网络最终被存储在连通性矩阵中,其中行和列表示节点,矩阵条目表示边(即以重建流线的数量作为连接强度)。
解剖连接组拓扑学
使用图论度量来评估解剖脑网络的拓扑组织。我们使用基于二值化(连接存在或连接不存在)连接矩阵的当前边的总数,来描述未加权的网络边。全局效率被定义为所有节点对之间的平均反向最短路径长度,通常被解释为总体通信能力的度量。聚类系数被计算为一个节点周围相互连接的平均可能性,也可作为一种可分离的测量。此外,针对不同的当前边数,对全局效率和聚类进行了归一化处理,归一化度量分别表示为全局效率归一化和聚类归一化。为此,从每个受试者的连接组矩阵生成1000个随机网络,并将归一化度量计算为随机网络的度量与平均度量的比率。小世界指数定义为归一化聚类系数与归一化最短路径长度之比。连通性的总强度被计算为给定对象的加权网络中所有边的流线的总数。最后,我们通过将强度除以当前边缘来计算每条边缘的平均流线数量。
质量控制
通过对连接组矩阵的质量控制导致马尔堡样本中排除了15个MDD、4个BD、1个SZ和12个HC,明斯德样本中排除了18个MDD、6个BD、1个SZ和15个HC。最后的总样本包含了马尔堡445名患者(336名MDD,56名BD和53名SZ)和521名HC,以及明斯特的456名患者(384名MDD,56名BD和16名SZ)和321名HC(总计n=1743)。
统计分析
使用IBM SPSS Statistics 26、MatLab 2019b和Python3.7.9进行统计分析。如果没有特别说明,统计检验是在α=0.05的双侧显著性水平上进行的。
在全局指标上的组间差异
首先,分析了全局组间差异(HC、MDD、BD和SZ)。使用协方差分析(ANCOVA),以各自的图形度量为因变量,组别、性别、扫描站点为固定因素,年龄作为协变量。对ANCOVA有显著组效应的再进行事后双样本T检验,比较组间差异。对ANCOVA和事后双样本T检验的P值均采用了FDR校正。
子网络分析
为了研究哪些子网络或哪些特定边缘潜在地驱动了观察到的在强度上的组间差异,我们检查了哪些边缘与四组之间的强度差异有关。为此,我们使用基于网络的统计(NBS)来检测与群体效应相关的一组边缘。为了确定不同诊断之间的共同影响,我们首先比较了患者组合(包括所有SZ、BD和MDD患者)与HC。下一步,为了分析可能的特定障碍的影响,我们分析了所有不同组之间的配对差异。在每一项分析中,对于网络中的每一条边计算了两组之间的t值。组别、性别、扫描站点为固定因素,年龄作为协变量。NBS通过在家族误差(family-wise error ,FWE)控制下的边缘水平执行单变量测试来判定在聚类水平的影响。首先,每条边都被分配了一个t值,该t值是从不同组之间流线数量的差异获得的。为每个成对关联计算的检验统计量在t=1.5处设置阈值,以选择所有阈值以上的边。然后,选择阈值以上边缘的最大分量来检测最稳健的组间边缘。使用5000个排列执行排列测试(随机分组)来描述FWE控制下的p值,作为基于组类大小的边缘簇。所有的分析都进行了FDR较正。
发病年龄分析
为了研究起病年龄(被认为是跨诊断疾病严重性的替代指标)是否与所有患者组中的网络改变相关,我们再次使用NBS来测试起病年龄是否与患者样本中的子网络流线的数量相关,同时校正了年龄、性别和扫描站点。在事后分析中,我们测试了已确定的网络中的诊断x发病年龄交互作用来检测不同疾病组的发病年龄和流线数目之间可能存在的不同联系。
基于机器学习的疾病组分类
我们想要知道的是,基于每个受试者的结构流线加权连接体矩阵,是否可以通过机器学习方法将患者组与健康对照组以及彼此分开。为此,我们训练了单独的两组分类模型。我们首先执行HC与组合患者组分类,然后采用一对一设计对所有单独组进行成对分类。为此,将连通性矩阵的上三角形(通过连接所有列)投射到作为分类流水线输入的一列。作为分类算法,我们首先采用了一种基于核的方法--支持向量机,由于其即使在高维数据中也能很好地表现,因此被频繁地用于神经成像数据。另一类重要的基于决策树集成的学习算法,随机森林(RF),已经被证明在神经成像中获得了良好的分类性能,这就是为什么我们使用RF作为替代算法。请注意,选择支持向量机或RF是我们的超参数优化的一部分,结果只有一种算法包含在最佳性能模型中。
所有步骤都是在PHOTONAI中实现的,PHOTONAI是一种用于设计和优化机器学习管道的高级PythonAPI。机器学习流程、超参数优化和模型评估使用嵌套交叉验证方案进行,以避免训练、验证和测试集之间的数据泄漏。使用最优参数配置在完整的训练集上训练模型。该模型随后被用来预测测试集中的组分配。平衡准确度被作为模型性能指标,它平衡了敏感性和特异性,以确保基线随机值为50%来解决分类组中样本数量的不平衡。平均准确性基于10个测试集评估得到。关于我们的特征选择、群体规模平衡措施、超参数优化、模型评估和使用置换测试估计重要性的程序请见附件材料。
表1 人口统计学数据及全局图论指标
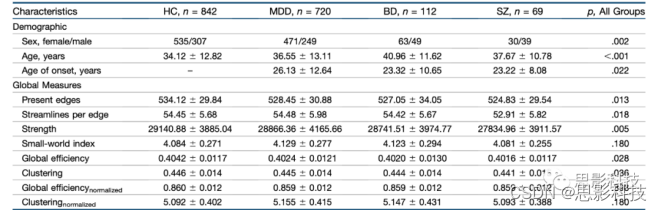
注:该表显示了样本的人口统计学、临床和连接组特征。全局图论指标的P值均采用FDR多重比较校正。
HC=健康对照组,MDD=重度抑郁碍,BD=双相情感障碍,SZ=精神分裂症
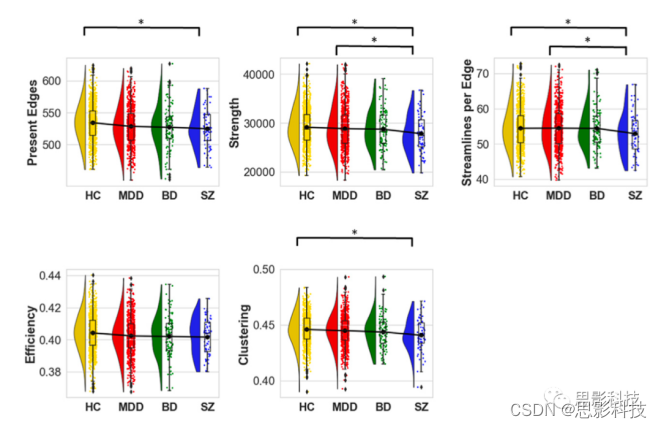
图1 全局图论指标的组间差异
在对年龄、性别和扫描地点进行校正的单因素方差分析中,检测到了组内的主要效应。*代表后验t检验的统计学意义(p<0.05)。盒子图显示了各自的样本中位数和四分位数之间的范围。每组内的平均值显示为一个黑点。
HC=健康对照组,MDD=重度抑郁障碍,BD=双相情感障碍,SZ=精神分裂症
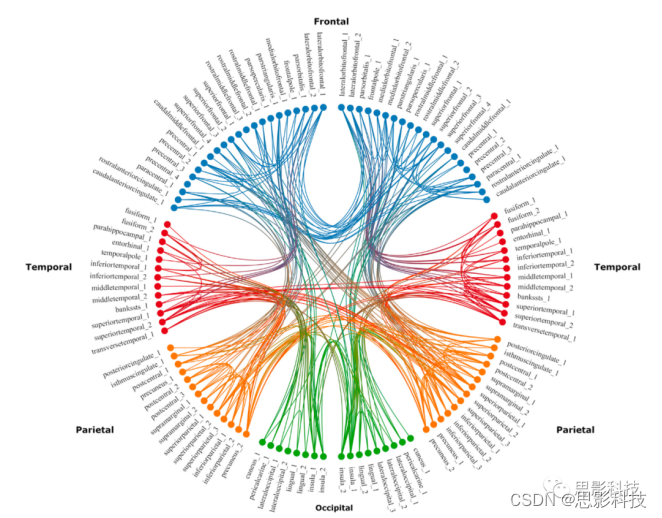
图2 与HC相比,精神病患者边缘的子网络流线数量减少
该网络来自于NBS (pFWE<0.05,超阈值t值t=1.5)测试健康对照组(HC)和诊断为严重抑郁障碍、双相情感障碍和精神分裂症的患者组之间的差异。该图是使用BrainDataViewer创建的。
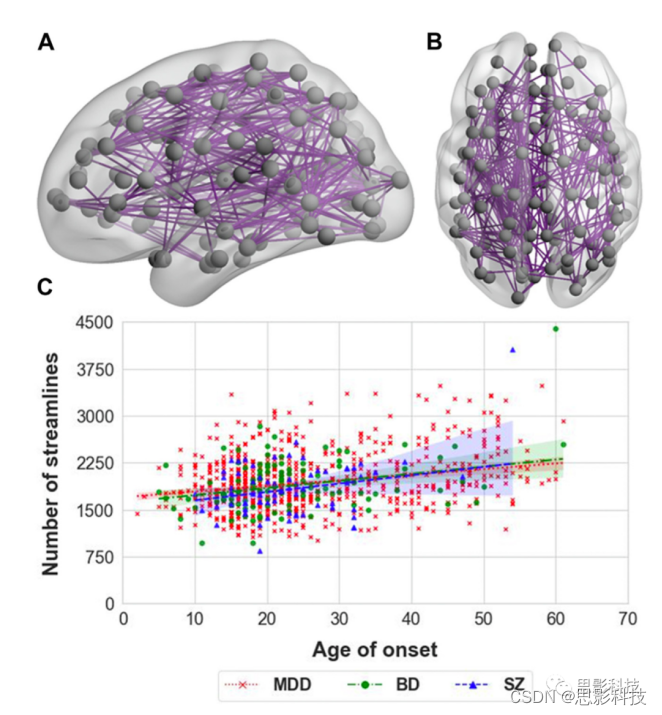
图3.与发病年龄相关的边缘的子网络
发病年龄越早,患者组中特定子网络的连接强度越低。子网络来源于NBS (pFWE<0.05,超阈值t值t=1.5)。网络图像使用BrainNet软件创建。
A:矢状视图。B:轴向视图。C:散点图,描绘了发病年龄和从显著簇中提取的流线总数之间的关系。
讨论
我们通过分析精神分裂症(SZ,n=69)、双相情感障碍(BD,n=112)或严重抑郁障碍(MDD,n=720)的患者,并将他们与健康对照组(HC,n=842)进行比较,研究了精神障碍和情感性障碍之间结构连接组变化的共同和特定模式。对大样本多方法连接网络分析揭示了三个主要发现:
- 结构连接障碍的总体模式,可在所有诊断中检测到,并能通过机器学习将精神病患者与健康对照组区分开来;
- 发病年龄与结构连接之间的额外关联,在那些起病较早的患者中,连接强度较低,这与诊断无关;
- 在总体连接异常模式之上和之外指向特定于诊断的连接组变化的患者组之间有显著差异。
我们对全局图论指标的分析揭示了MDD、BP和SZ在效率、聚类、连接强度、流线数量以及边缘上的组间效应。结果的模式在所有指标中都是一致的,比如通信效率按HC>MDD>BD>SZ的顺序递减(如图1)。这些结果表明,全局网络通信存在一连串的损害,其中在SZ中可以检测到最严重的连接改变。量化网络的整体通信容量的效率差异很可能是由于当前边的数量的差异,因为我们在分析归一化效率时没有发现组间的实质性差异,这解释了网络边数量的差异。为了进一步识别这种全局模式下的边缘子网络,我们采用了基于网络统计(NBS)。NBS发现了一个广泛的网络,其特征是患者的连接强度降低。在所有诊断组中都观察到了这种效果。因此,连接性强度的降低可能反映了所有精神病和情感障碍的共享的跨诊断标记物,并可能反映了MDD、BD和SZ的连接性障碍的共同核心。对这些区域的进一步调查和它们与精神病理学的关联可以支持跨诊断边界的疾病维度的概念。
根据目前的文献,这些结果增加了对精神障碍中连接组改变的理解:虽然到目前为止有几项研究集中在与HC相比的单一障碍上,但我们现在显示了这些障碍结构连接性受损的共同核心。虽然在某些情况下有必要研究特定的解剖、结节参数,但我们的结果表明,与导致精神病理学的特定、局部解剖改变的概念相比,损害模式影响到所有主要大脑区域,因此指向网络通信的真正损害。然而,虽然我们的大多数结果强调了改变的跨诊断性质,但结果与之前的研究一致,这些研究表明精神分裂症的损害程度最明显。
总而言之,这些结果指出了结构连接组内连接障碍的总体模式,这种模式在障碍中是共有的,可能反映了网络交流的障碍。同样,代表结构连接组的连接矩阵形成了基础,在此基础上,我们能够通过机器学习将所有患者组与健康对照组区分开来,在HC与SZ的对比中具有最高的准确性,与全局指标结果一致。虽然我们的机器学习模型中的显著性检验显示,与对照预测相比,所有患者的分类准确率都很明显(p<0.05),但应该注意的是,准确率的值并不高(最高值为60.2%)。这意味着在这一点上,基于机器学习的分类还不适合临床实施。然而,精确值与大样本量的机器学习精确度是一致的。未来的研究应该测试在结构连接中检测到的模式是否对预测疾病轨迹和功能结果有意义。
除了这种共有的连接障碍模式外,我们还发现了另一个跨诊断网络,在该网络中,起病较早的患者表现出最严重的连接障碍。较早发病的患者是精神障碍中已知的一个更严重的疾病轨迹的风险因素。有趣的是,与发病年龄相关的子网络与SZ、BD或MDD各自的疾病网络没有明显重叠,这表明连接体连接障碍特征与诊断的特定效果无关。未来的纵向研究应该集中在尚未解决的问题上,即连接体改变是如何以及何时在大脑中表现出与疾病发病相关的。
除了这些跨诊断发现,我们的分析还揭示了潜在的诊断特异性连接体改变,在全局水平的患者组比较中可以检测到,特别是在使用NBS的子网络分析中。这些分析揭示了不同诊断组之间某些白质束的不同损害。然而,机器学习模型不能根据患者组数据预测诊断(例如,MDD与SZ)。这指向了特定于障碍的网络特征的较低预测价值。未来的研究应该研究NBS分析确定的特定子网络中的连通性差异是否有助于疾病组的机器学习预测。
必须承认有几个限制。这项研究是横向的,因此不能解决纵向研究可以解决的问题:首先,探索性结果没有指出结构连接体与共病或药物负荷之间有很强的相关性。然而,由于该数据集的横向性质,我们不能将诊断效果从治疗或疾病轨迹相关的影响中分离出来,这需要通过未来的纵向队列研究来解决,这些研究理想地包括具有广泛和详细的临床随访期的未服用药物的患者组。特别是我们的机器分学习方法,其中我们没有纠正所有这些混杂因素,结果容易受到药物或并发症的影响而产生偏差。因此,我们决定使用推断统计学来全面评估这些混杂因素的影响,并通过承认我们的推理统计学和机器学习方法的互补性来完善结果。
总结
本文展示了SZ、BD和MDD中共有和特定的连接模式,从而导致这些情况下普遍存在的网络通信效率降低。这些发现表明,结构连接障碍的模式不仅在精神分裂症中,在情感障碍中也是如此,因此进一步质疑这些障碍是否是真正不同的神经生物学实体。然而,它们也打开了进一步阐明可能偏离共同连接障碍模式的机会,从而确定未来不同精神表型和症状特征的微妙神经生物学基础。