机器学习是人工智能中一个流行的子领域,其涉及的领域非常广泛。流行的原因之一是在其策略下有一个由复杂的算法、技术和方法论组成的综合工具箱。该工具箱已经经过了多年的开发和改进,同时新的工具箱也在持续不断地被研究出来。为了更好地使用机器学习工具箱,我们需要先了解以下几种机器学习的分类方式。

基于是否有人工进行监督的分类如下。
- 监督学习。这一类别高度依赖人工监督。监督学习类别下的算法从训练数据和对应的输出中学习两个变量之间的映射,并将该映射运用于从未见过的数据。分类任务和回归任务是监督学习算法的两种主要任务类型。
- 无监督学习。这类算法试图从没有任何(在人工监督之下)关联输出或标记的输入数据中学习内在的潜在结构、模式和关系。聚类、降维、关联规则挖掘等任务是无监督学习算法的几种主要任务类型。
- 半监督学习。这类算法是监督学习算法和无监督学习算法的混合。这一类别下的算法使用少量的标记训练数据和更多的非标记训练数据,因此需要创造性地使用监督学习方法和无监督学习方法来解决特定问题。
- 强化学习。这类算法与监督学习和无监督学习算法略有不同。强化学习算法的中心实体是一个代理,它在训练期间会同环境进行交互让奖励最大化。代理会迭代地进行学习,并基于和环境的交互中获得的奖励或惩罚来调整其策略。
基于数据可用性的分类如下。
- 批量学习。也被称为离线学习,当所需的训练数据可用时可以使用这类算法,同时这种算法也可以在部署到生产环境或现实世界之前对模型进行训练和微调。
- 在线学习。顾名思义,在这类算法中只要数据可用,学习就不会停止。另外,在这类算法中,数据会被小批量地输入系统,而下一次训练将会使用新批次中的数据。
前面讨论的分类方法让我们对关于如何组织、理解和利用机器学习算法有了一个抽象的理解。机器学习算法最常见的分类方法为监督学习算法和无监督学习算法。下面让我们更详细地讨论这两个类别,因为这将有助于我们开启后面将要介绍的更高级的主题。
1.2.1 监督学习
监督学习算法是一类使用数据样本(也称为训练样本)和对应输出(或标签)来推断两者之间映射函数的算法。推断映射函数或学习函数是这个训练过程的输出。学习函数能正确地映射新的和从未见过的数据点(即输入元素),以测试自身的性能。
监督学习算法中的几个关键概念的介绍如下。
- 训练数据集。训练过程中使用的训练样本和对应的输出称为训练数据。在形式上,一个训练数据集是由一个输入元素(通常是一个向量)和对应的输出元素或信号组成的二元元组。
- 测试数据集。用来测试学习函数性能的从未见过的数据集。该数据集也是一个包含输入数据点和对应输出信号的二元元组。在训练阶段不使用该集合中的数据点(该数据集也会进一步划分为验证集,我们将在后续章节中详细讨论)。
- 学习函数。这是训练阶段的输出,也称为推断函数或模型。该函数基于训练数据集中的训练实例(输入数据点及其对应的输出)被推断出。一个理想的模型或学习函数学到的映射也能推广到从未见过的数据。
可用的监督学习算法有很多。根据使用需求,它们主要被划分为分类模型和回归模型。
1.分类模型
用最简单的话来说,分类算法能帮助我们回答客观问题或是非预测。例如这些算法在一些场景中很有用,如“今天会下雨吗?”或者“这个肿瘤可能癌变吗?”等。
从形式上来说,分类算法的关键目标是基于输入数据点预测本质分类的输出标签。输出标签在本质上都是类别,也就是说,它们都属于一个离散类或类别范畴。
逻辑回归、支持向量机(Support Vector Machine,SVM)、神经网络、随机森林、K-近邻算法(K-Nearest Neighbour,KNN)、决策树等算法都是流行的分类算法。
假设我们有一个真实世界的用例来评估不同的汽车模型。为了简单起见,我们假设模型被期望基于多个输入训练样本预测每个汽车模型的输出是可接受的还是不可接受的。输入训练样本的属性包括购买价格、门数、容量(以人数为单位)和安全级别。
除了类标签以外,每一层的其他属性都会用于表示每个数据点是否可接受。图1.3所示描述了目前的二元分类问题。分类算法以训练样本为输入来生成一个监督模型,然后利用该模型为一个新的数据点预测评估标签。
机器学习算法" src="https://img-blog.csdnimg.cn/img_convert/0521a0b06cb96ddf7c23d6b6f1942d54.png" />
图1.3
在分类问题中,由于输出标签是离散类,因此如果只有两个可能的输出类,任务则被称为二元分类问题,否则被称为多类分类问题。例如预测明天是否下雨是一个二元分类问题(其输出为是或否);从扫描的手写图像中预测一个数字则是一个包含10个标签(可能的输出标签为0~9)的多类分类问题。
2.回归模型
这类监督学习算法能帮助我们回答“数量是多少”这样的量化问题。从形式上来说,回归模型的关键目标是估值。在这类问题中,输出标签本质上是连续值(而不是分类问题中的离散输出)。
在回归问题中,输入数据点被称为自变量或解释变量,而输出被称为因变量。回归模型还会使用由输入(或自变量)数据点和输出(或因变量)信号组成的训练数据样本进行训练。线性回归、多元回归、回归树等算法都是监督回归算法。
回归模型可以基于其对因变量和自变量之间关系的模型进一步分类。
简单线性回归模型适用于包含单个自变量和单个因变量的问题。普通最小二乘(Ordinary Least Square,OLS)回归是一种流行的线性回归模型。多元回归或多变量回归是指只有一个因变量,而每个观测值是由多个解释变量组成的向量的问题。
多项式回归模型是多元回归的一种特殊形式。该模型使用自变量的n次方对因变量进行建模。由于多项式回归模型能拟合或映射因变量和自变量之间的非线性关系,因此这类模型也被称为非线性回归模型。
图1.4所示是一个线性回归的例子。
机器学习算法" src="https://img-blog.csdnimg.cn/img_convert/93db4455dada2028488d15a4b7852321.png" />
图1.4
为了理解不同的回归类型,我们可以考虑一个现实世界中根据车速估计汽车的行车距离(单位省略)的用例。在这个问题中,基于已有的训练数据,我们可以将距离建模为汽车速度(单位省略)的线性函数,或汽车速度的多项式函数。记住,主要目标是在不过拟合训练数据本身的前提下将误差最小化。
前面的图1.4描述了一个线性拟合模型,而图1.5所示描述了使用同一数据集的多项式拟合模型。
机器学习算法" src="https://img-blog.csdnimg.cn/img_convert/72fbb71798d0019c46c95de00356fd11.png" />
图1.5
1.2.2 无监督学习
顾名思义,无监督学习算法是在没有监督的情况下对概念进行学习或推断。监督学习算法基于输入数据点和输出信号组成的训练数据集来推断映射函数,而无监督学习算法的任务是在没有任何输出信号的训练数据集中找出训练数据中的模式和关系。这类算法利用输入数据集来检测模式,挖掘规则或将数据点进行分组/聚类,从而从原始输入数据集中提取出有意义的见解。
当我们没有包含相应输出信号或标签的训练集时,无监督学习算法就能派上用场。在许多现实场景中,数据集在没有输出信号的情况下是可用的,并且很难手动对其进行标记。因此无监督学习算法有助于填补这些空缺。
与监督学习算法类似,为了便于理解和学习,无监督学习算法也可以进行分类。下面是不同类别的无监督学习算法。
1.聚类
分类问题的无监督学习算法称为聚类。这些算法能够帮助我们将数据点聚类或分组到不同的组或类别中,而不需要在输入或训练数据集中包含任何输出标签。这些算法会尝试从输入数据集中找到模式和关系,利用固有特征基于某种相似性度量将它们分组。
一个有助于理解聚类的现实世界的例子是新闻文章。每天有数百篇新闻报道被创作出来,每一篇都针对不同的话题,如政治、体育和娱乐等。聚类是一种可以将这些文章进行分组的无监督方法,如图1.6所示。
执行聚类过程的方法有多种,其中最受欢迎的方法包括以下几种。
- 基于重心的方法。例如流行的K-均值算法和K-中心点算法。
- 聚合和分裂层次聚类法。例如流行的沃德算法和仿射传播算法。
- 基于数据分布的方法。例如高斯混合模型。
- 基于密度的方法。例如具有噪声的基于密度的基类方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)等。
机器学习算法" src="https://img-blog.csdnimg.cn/img_convert/fd0401afe5207097440bc725b4adadd9.png" />
图1.6
2.降维
数据和机器学习是最好的朋友,但是更多、更大的数据会带来许多问题。大量的属性或膨胀的特征空间是常见的问题。一个大型特征空间在带来数据分析和可视化方面的问题的同时,也带来了与训练、内存和空间约束相关的问题。这种现象被称为维度诅咒。由于无监督方法能够帮助我们从未标记的训练数据集中提取见解和模式,因此这些方法在帮助我们减少维度方面很有用。
换句话说,无监督方法能够帮助我们从完整的可用列表中选择一组具有代表性的特征,从而帮助我们减少特征空间,如图1.7所示。
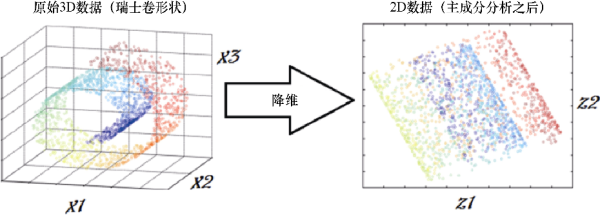
图1.7
主成分分析(Principal Component Analysis,PCA)、最近邻分析和判别分析是常用的降维技术。
图1.7所示是基于PCA的降维技术的工作原理的著名描述图片。图片左侧展示了一组在三维空间中能表示为瑞士卷形状的数据,图片右侧则展示了应用PCA将数据转换到二维空间中的结果。
3.关联规则挖掘
这类无监督机器学习算法能够帮助我们理解和从交易数据集中提取模式。这些算法被称为市场篮子分析(Market Basket Analysis,MBA),可以帮助我们识别交易项目之间有趣的关系。
使用关联规则挖掘,我们可以回答“在特定的商店中哪些商品会被一起购买?”或者“买葡萄酒的人也会买奶酪吗?”等问题。FP-growth、ECLAT和Apriori是关联规则挖掘任务的一些广泛使用的算法。
4.异常检测
异常检测是基于历史数据识别罕见事件或观测的任务,也称为离群点检测。异常值或离群值通常具有不频繁出现或在短时间内突然爆发的特征。
对于这类任务,我们为算法提供了一个历史数据集,因此它能够以无监督学习的方式识别和学习数据的正常行为。一旦学习完成之后,算法将帮助我们识别不同于之前学习行为的模式。