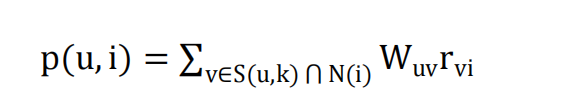基于聚类的推荐算法笔记——以豆瓣电影为例(一)(附源代码)
前言
本文记载一下本科毕设所研究的课题步骤以及一些细节,由于此次毕设对于推荐领域很感兴趣,发表一些浅显见解,希望大佬们不吝赐教。
一、Canopy聚类
Canopy 算法单独使用效果较差,因为它仅使用一种快速、单一的方法来计 算距离,为了降低时间成本舍弃了精度。
1.1具体实现
Canopy算法需要设定T1和T2(T1>=T2),随机选择一个中心点,其余点到中心点距离在T1内视为弱相关,小于T2则视为强相关,将该点移除不参与下一次中心点的选择。
具体步骤:
- 需要设定距离阈值 T1 和 T2,其中 T1>=T2;
- 从数据 D 中随机算出一点 a,计算其余点到 a 的距离 T ;
- 将 T<T1 的点都归入 a 类;
- 将 T<T2 的点从 D 中移除,不再参与下次迭代;
- 重复步骤 2-4,直至 D 中为空。
1.2遇到的问题
- 实现过程中发现T1的距离并无太大作用,对大于T1的点和小于T1大于T2的点的操作并无不同,因此在实现中设定T1==T2,方便后续计算。
- 再有就是T值的设定没有明确的规定,只能依照经验进行设置,在本次实验中借鉴一些说法,计算每个点与其余点的平均距离然后再取平均作为参考值。
计算T值实现代码:
python">import math
import numpy as np
import pandas as pd
def distance(point1,point2):
return math.sqrt(pow(point1[0] - point2[0], 2) + pow(point1[1] - point2[1], 2))
points = []
#center_points = []
K = 0
file="D:\\experiment\\第三次豆瓣\\测试3\\train\\douban_train_zuobiao.csv"#放路径
data=pd.read_csv(file)
train_data = np.array(data)#转换为数组
#print(train_data)
all_list=train_data.tolist()#转换list
#print(all_list)
for item in all_list:
print(item[1])
print(item[2])
print("-----------------------")
point = [item[1], item[2]]
points.append(point)
#print(type(points))#每个点存入列表
points = np.array(points)#转化为数组形式
#print(points)
T = 0
for item in points:
avg = 0
for other in points:
if all(other == item):
continue
avg += distance(item,other)
avg /= 181#数据中一共182位用户,刨除自己剩余181位用户,计算每个点到其余点的平均距离
print("当前点的平均距离为:",avg)
T += avg
T /= 182
print("T值为:",T)
二、K-means聚类
俗话说“人与类聚,物以群分”,K-means聚类就是遵循这句话的算法,根据特征将数据分为不同的组,组内差异越小越好,组间差距越大越好,就是相同特性聚在一起,不同特性相互远离。
2.1具体实现
利用Canopy算法得到的中心点集和簇数作为K-means算法的初始值,有效的避免了由于K值的选择导致精度不好的问题。
python">#计算点与点间的距离使用欧氏距离公式:[(x1-x2)^2+(y1-y2)^2]^1/2
代码太长了此处写不下~
详细代码可以看我的Git仓库(要是有帮助恳请点个赞)
2.2遇到的问题
需要传入中心点集和簇数作为初始值,故没有使用sklearn库中的K-means函数,单独将K-means函数写成K-means类使用。
3. 聚类结果
实验集中共有182位用户,画出散点图如下:

进行混合聚类后划分为4簇,结果如下:
 聚类效果图" />
聚类效果图" />
总结
使用Canopy算法作为K-means的前置算法,无疑比单独使用K-means算法精度更高,本次只是简单介绍了一下使用的两个方法的原理以及代码。下一篇开始介绍使用的数据以及数据获取,更多详细代码请移步仓库
CSND资源