This post was originally published here
这篇文章最初发表在这里
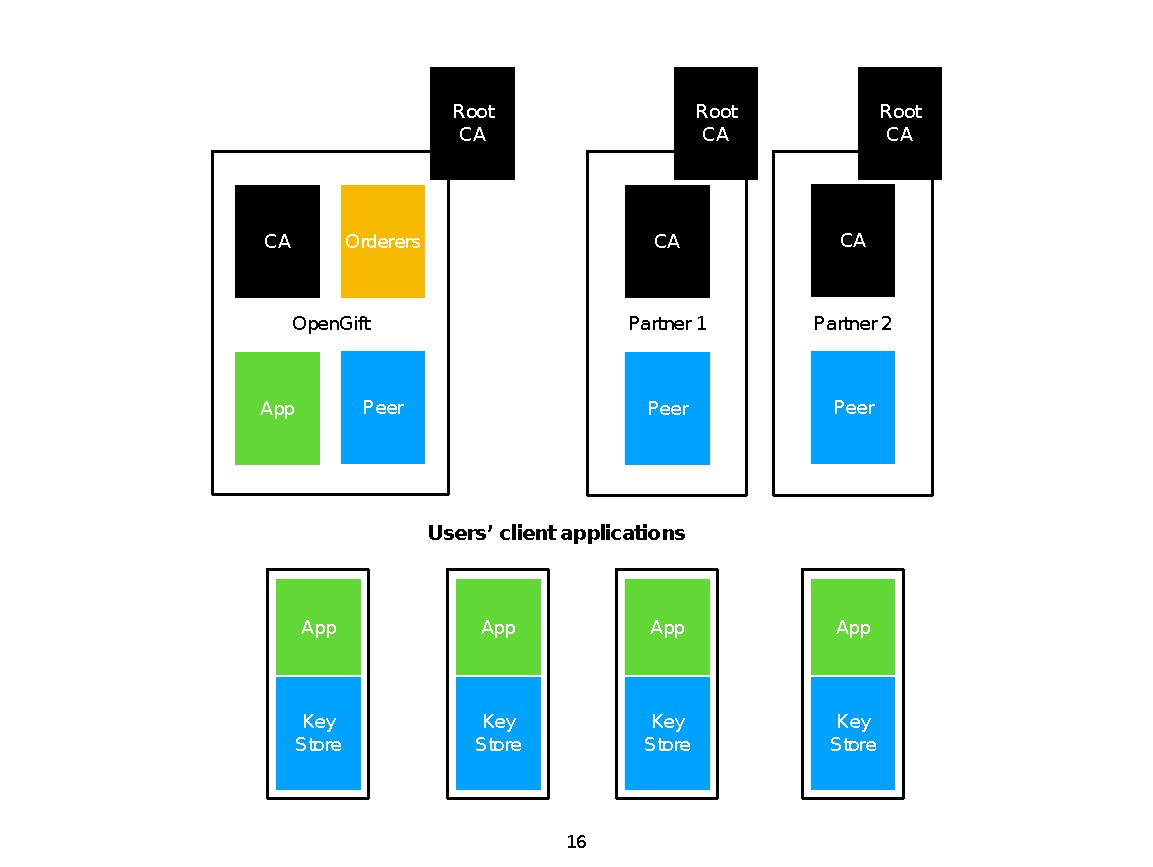
Clustering is the grouping of objects together so that objects belonging in the same group (cluster) are more similar to each other than those in other groups (clusters). In this intro cluster analysis tutorial, we’ll check out a few algorithms in Python so you can get a basic understanding of the fundamentals of clustering on a real dataset.
聚类是将对象分组在一起,以便属于同一组(群集)的对象比其他组(群集)的对象彼此更相似。 在此介绍性群集分析教程中,我们将检查一些Python中的算法,以便您可以基本了解真实数据集上的群集基础。
数据集 (The Dataset)
For the clustering problem, we will use the famous Zachary’s Karate Club dataset. The story behind the data set is quite simple: There was a Karate Club that had an administrator “John A” and an instructor “Mr. Hi” (both pseudonyms). Then a conflict arose between them, causing the students (Nodes) to split into two groups. One that followed John and one that followed Mr. Hi.
对于聚类问题,我们将使用著名的Zachary的空手道俱乐部数据集。 数据集背后的故事很简单:一个空手道俱乐部有一个管理员“约翰·A”和一个教练“先生”。 嗨”(两个化名)。 然后他们之间发生了冲突,导致学生(节点)分为两组。 一个跟随约翰,另一个跟随Hi先生。

Python群集入门 (Getting Started with Clustering in Python)
But enough with the introductory talk, let’s get to main reason you are here, the code itself. First of all, you need to install both scikit-learn and networkx libraries to complete this tutorial. If you don’t know how, the links above should help you. Also, feel free to follow along by grabbing the source code for this tutorial over on Github.
但是,通过介绍性的讨论就足够了,让我们了解代码出现的主要原因。 首先,您需要同时安装scikit-learn和networkx库才能完成本教程。 如果您不知道如何,上面的链接应该可以为您提供帮助。 另外,欢迎随时通过Github获取本教程的源代码。
Usually, the datasets that we want to examine are available in text form (JSON, Excel, simple txt file, etc.) but in our case, networkx provide it for us. Also, to compare our algorithms, we want the truth about the members (who followed whom) which unfortunately is not provided. But with these two lines of code, you will be able to load the data and store the truth (from now on we will refer it as ground truth):
通常,我们要检查的数据集以文本形式(JSON,Excel,简单的txt文件等)可用,但在我们的情况下, networkx为我们提供了它。 另外,为了比较我们的算法,我们想要关于不幸的是没有提供成员(跟随谁)的真相。 但是,通过这两行代码,您将能够加载数据并存储真相(从现在开始,我们将其称为基本真相):
# Load and Store both data and groundtruth of Zachary's Karate Club G = nx.karate_club_graph() groundTruth = [0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,0,0,1,0,1,0,1,1,1,1,1,1,1,1,1,1,1,1]# Load and Store both data and groundtruth of Zachary's Karate Club G = nx.karate_club_graph() groundTruth = [0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,0,0,1,0,1,0,1,1,1,1,1,1,1,1,1,1,1,1]
The final step of the data preprocessing, is to transform the graph into a matrix (desirable input for our algorithms). This is also quite simple:
数据预处理的最后一步是将图形转换成矩阵(对于我们的算法来说是理想的输入)。 这也很简单:
Before we get going with the Clustering Techniques, I would like you to get a visualization on our data. So, let’s compile a simple function to do that:
在我们开始使用聚类技术之前,我希望您对我们的数据有一个可视化。 因此,让我们编译一个简单的函数来做到这一点:
def drawCommunities(G, partition, pos): # G is graph in networkx form # Partition is a dict containing info on clusters # Pos is base on networkx spring layout (nx.spring_layout(G)) # For separating communities colors dictList = defaultdict(list) nodelist = [] for node, com in partition.items(): dictList[com].append(node) # Get size of Communities size = len(set(partition.values())) # For loop to assign communities colors for i in range(size): amplifier = i % 3 multi = (i / 3) * 0.3 red = green = blue = 0 if amplifier == 0: red = 0.1 + multi elif amplifier == 1: green = 0.1 + multi else: blue = 0.1 + multi # Draw Nodes nx.draw_networkx_nodes(G, pos, nodelist=dictList[i], node_color=[0.0 + red, 0.0 + green, 0.0 + blue], node_size=500, alpha=0.8) # Draw edges and final plot plt.title("Zachary's Karate Club") nx.draw_networkx_edges(G, pos, alpha=0.5)def drawCommunities(G, partition, pos): # G is graph in networkx form # Partition is a dict containing info on clusters # Pos is base on networkx spring layout (nx.spring_layout(G)) # For separating communities colors dictList = defaultdict(list) nodelist = [] for node, com in partition.items(): dictList[com].append(node) # Get size of Communities size = len(set(partition.values())) # For loop to assign communities colors for i in range(size): amplifier = i % 3 multi = (i / 3) * 0.3 red = green = blue = 0 if amplifier == 0: red = 0.1 + multi elif amplifier == 1: green = 0.1 + multi else: blue = 0.1 + multi # Draw Nodes nx.draw_networkx_nodes(G, pos, nodelist=dictList[i], node_color=[0.0 + red, 0.0 + green, 0.0 + blue], node_size=500, alpha=0.8) # Draw edges and final plot plt.title("Zachary's Karate Club") nx.draw_networkx_edges(G, pos, alpha=0.5)
What that function does is to simply extract the number of clusters that are in our result and then assign a different color to each of them (up to 10 for the given time is fine) before plotting them.
该函数的作用是简单地提取结果中的聚类数量,然后为每个聚类分配不同的颜色(在给定时间内最多可以分配10个颜色),然后再绘制它们。

聚类算法 (Clustering Algorithms)
Some clustering algorithms will cluster your data quite nicely and others will end up failing to do so. That is one of the main reasons why clustering is such a difficult problem. But don’t worry, we won’t let you drown in an ocean of choices. We’ll go through a few algorithms that are known to perform very well.
一些聚类算法会很好地聚类您的数据,而另一些聚类算法最终会失败。 这是聚类如此困难的问题的主要原因之一。 但请放心,我们不会让您淹没在众多选择中。 我们将介绍一些表现出色的算法。
K均值聚类 (K-Means Clustering)
Source: github.com/nitoyon/tech.nitoyon.com
资料来源: github.com/nitoyon/tech.nitoyon.com
K-means is considered by many the gold standard when it comes to clustering due to its simplicity and performance, and it’s the first one we’ll try out. When you have no idea at all what algorithm to use, K-means is usually the first choice. Bear in mind that K-means might under-perform sometimes due to its concept: spherical clusters that are separable in a way so that the mean value converges towards the cluster center. To simply construct and train a K-means model, use the follow lines:
由于涉及简单性和性能,在聚类方面,K-means被许多黄金标准视为标准,这是我们将尝试的第一个方法。 当您完全不知道要使用哪种算法时,K-means通常是首选。 请记住,由于其概念,K均值有时可能会表现不佳:球形聚类可以以某种方式分离,以使平均值朝聚类中心收敛。 要简单地构建和训练K均值模型,请使用以下代码行:
聚集聚类 (Agglomerative Clustering)
The main idea behind agglomerative clustering is that each node starts in its own cluster, and recursively merges with the pair of clusters that minimally increases a given linkage distance. The main advantage of agglomerative clustering (and hierarchical clustering in general) is that you don’t need to specify the number of clusters. That of course, comes with a price: performance. But, in scikit’s implementation, you can specify the number of clusters to assist the algorithm’s performance. To create and train an agglomerative model use the following code:
聚集群集背后的主要思想是,每个节点都从其自己的群集开始,然后与这对群集进行递归合并,从而最小地增加了给定的链接距离。 聚集集群(通常是分层集群)的主要优点是,您无需指定集群的数量。 当然,这要付出代价:性能。 但是,在scikit的实现中,您可以指定簇数以辅助算法的性能。 要创建和训练凝聚模型,请使用以下代码:
# Agglomerative Clustering Model agglomerative = cluster.AgglomerativeClustering(n_clusters=kClusters, linkage="ward") agglomerative.fit(edgeMat) # Transform our data to list form and store them in results list results.append(list(agglomerative.labels_))# Agglomerative Clustering Model agglomerative = cluster.AgglomerativeClustering(n_clusters=kClusters, linkage="ward") agglomerative.fit(edgeMat) # Transform our data to list form and store them in results list results.append(list(agglomerative.labels_))
光谱 (Spectral)
The Spectral clustering technique applies clustering to a projection of the normalized Laplacian. When it comes to image clustering, spectral clustering works quite well. See the next few lines of Python for all the magic:
频谱聚类技术将聚类应用于归一化拉普拉斯算子的投影。 当涉及图像聚类时,光谱聚类可以很好地工作。 有关所有魔术,请参见Python的以下几行:
亲和力传播 (Affinity Propagation)
Well this one is a bit different. Unlike the previous algorithms, you can see AF does not require the number of clusters to be determined before running the algorithm. AF, performs really well on several computer vision and biology problems, such as clustering pictures of human faces and identifying regulated transcripts:
好吧,这个有点不同。 与以前的算法不同,您可以看到AF不需要在运行算法之前确定簇数。 AF在一些计算机视觉和生物学问题上表现出色,例如将人脸图片聚类并识别受管制的笔录:
# Affinity Propagation Clustering Model affinity = cluster.affinity_propagation(S=edgeMat, max_iter=200, damping=0.6) # Transform our data to list form and store them in results list results.append(list(affinity[1]))# Affinity Propagation Clustering Model affinity = cluster.affinity_propagation(S=edgeMat, max_iter=200, damping=0.6) # Transform our data to list form and store them in results list results.append(list(affinity[1]))
指标和绘图 (Metrics & Plotting)
Well, it is time to choose which algorithm is more suitable for our data. A simple visualization of the result might work on small datasets, but imagine a graph with one thousand, or even ten thousand, nodes. That would be slightly chaotic for the human eye. So, let me show how to calculate the Adjusted Rand Score (ARS) and the Normalized Mutual Information (NMI):
好了,现在该选择哪种算法更适合我们的数据了。 对结果进行简单的可视化可能适用于小型数据集,但可以想象一个具有一千甚至一万个节点的图。 对于人眼来说,这将有些混乱。 因此,让我展示如何计算调整后的兰德分数(ARS)和归一化的共同信息(NMI):
If you’re unfamiliar with these metrics, here’s a quick explanation:
如果您不熟悉这些指标,请快速进行说明:
标准化互信息(NMI) (Normalized Mutual Information (NMI))
Mutual Information of two random variables is a measure of the mutual dependence between the two variables. Normalized Mutual Information is a normalization of the Mutual Information (MI) score to scale the results between 0 (no mutual information) and 1 (perfect correlation). In other words, 0 means dissimilar and 1 means perfect match.
两个随机变量的互信息是两个变量之间相互依赖的度量。 归一化互信息是互信息(MI)分数的归一化,用于在0(无互信息)和1(完全相关)之间缩放结果。 换句话说,0表示不相似,1表示完全匹配。
调整后的兰德比分(ARS) (Adjusted Rand Score (ARS))
Adjusted Rand Score on the other hand, computes a similarity measure between two clusters by considering all pairs of samples and counting pairs that are assigned in the same or different clusters in the predicted and true clusters. If that’s a little weird to think about, have in mind that, for now, 0 is the lowest similarity and 1 is the highest.
另一方面,调整后的兰德得分可通过考虑所有样本对并计算在预测和真实群集中相同或不同群集中分配的对对来计算两个群集之间的相似性度量。 如果觉得这有点怪异,请记住,目前,0是最低的相似性,而1是最高的相似性。
So, to get a combination of these metrics (the NMI and ARS), we simply calculate the average value of their sum. And remember, the higher the number, the better the result.
因此,要获得这些指标(NMI和ARS)的组合,我们只需计算其总和的平均值即可。 请记住,数字越大,结果越好。
Below, I have plotted the score evaluation so we can get a better understanding of our results. We could plot them in many ways, as points, as a straight line, but I think a bar chart is the better choice for our case. To do so, just use the following code:
下面,我绘制了分数评估,以便我们可以更好地了解我们的结果。 我们可以通过多种方式将它们绘制为点或直线,但我认为条形图是我们案例的更好选择。 为此,只需使用以下代码:
# Code for plotting results # Average of NMI and ARS y = [sum(x) / 2 for x in zip(nmiResults, arsResults)] xlabels = ['Spectral', 'Agglomerative', 'Kmeans', 'Affinity Propagation'] fig = plt.figure() ax = fig.add_subplot(111) # Set parameters for plotting ind = np.arange(len(y)) width = 0.35 # Create barchart and set the axis limits and titles ax.bar(ind, y, width,color='blue', error_kw=dict(elinewidth=2, ecolor='red')) ax.set_xlim(-width, len(ind)+width) ax.set_ylim(0,2) ax.set_ylabel('Average Score (NMI, ARS)') ax.set_title('Score Evaluation') # Add the xlabels to the chart ax.set_xticks(ind + width / 2) xtickNames = ax.set_xticklabels(xlabels) plt.setp(xtickNames, fontsize=12) # Add the actual value on top of each chart for i, v in enumerate(y): ax.text( i, v, str(round(v, 2)), color='blue', fontweight='bold') # Show the final plot plt.show()# Code for plotting results # Average of NMI and ARS y = [sum(x) / 2 for x in zip(nmiResults, arsResults)] xlabels = ['Spectral', 'Agglomerative', 'Kmeans', 'Affinity Propagation'] fig = plt.figure() ax = fig.add_subplot(111) # Set parameters for plotting ind = np.arange(len(y)) width = 0.35 # Create barchart and set the axis limits and titles ax.bar(ind, y, width,color='blue', error_kw=dict(elinewidth=2, ecolor='red')) ax.set_xlim(-width, len(ind)+width) ax.set_ylim(0,2) ax.set_ylabel('Average Score (NMI, ARS)') ax.set_title('Score Evaluation') # Add the xlabels to the chart ax.set_xticks(ind + width / 2) xtickNames = ax.set_xticklabels(xlabels) plt.setp(xtickNames, fontsize=12) # Add the actual value on top of each chart for i, v in enumerate(y): ax.text( i, v, str(round(v, 2)), color='blue', fontweight='bold') # Show the final plot plt.show()
As you can see in the chart below, K-means and Agglomerative clustering have the best results for our dataset (best possible outcome). That of course, does not mean that Spectral and AF are low-performing algorithms, just that the did not fit in our data.
如下图所示,K均值和聚集聚类对我们的数据集具有最佳结果(可能的最佳结果)。 当然,这并不意味着Spectral和AF是性能不佳的算法,只是不适合我们的数据。
 聚类得分评估" width="800" height="597" />
聚类得分评估" width="800" height="597" />
Well, that’s it for this one!
好了,仅此而已!
Thanks for joining me in this clustering intro. I hope you found some value in seeing how we can easily manipulate a public dataset and apply several different clustering algorithms in Python. Let me know if you have any questions in the comments below, and feel free to attach a clustering project you’ve experimented with!
感谢您加入我的这个集群介绍。 我希望您在了解如何轻松地操纵公共数据集并在Python中应用几种不同的聚类算法中找到一些价值。 如果您在下面的评论中有任何疑问,请告诉我,并随时附加您尝试过的集群项目!
翻译自: https://www.pybloggers.com/2017/02/k-means-clustering-algorithms-quick-intro-python/